Как удалить повторяющийся элемент в структуре массива pyspark
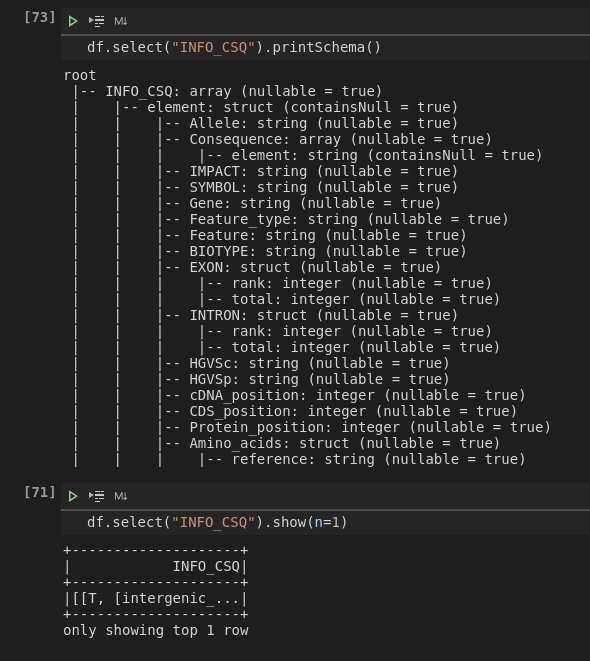
У меня есть столбец в фрейме данных, который называется «INFO_CSQ». Я хочу удалить любой повторяющийся элемент в структуре, из-за которого я не могу использовать команду
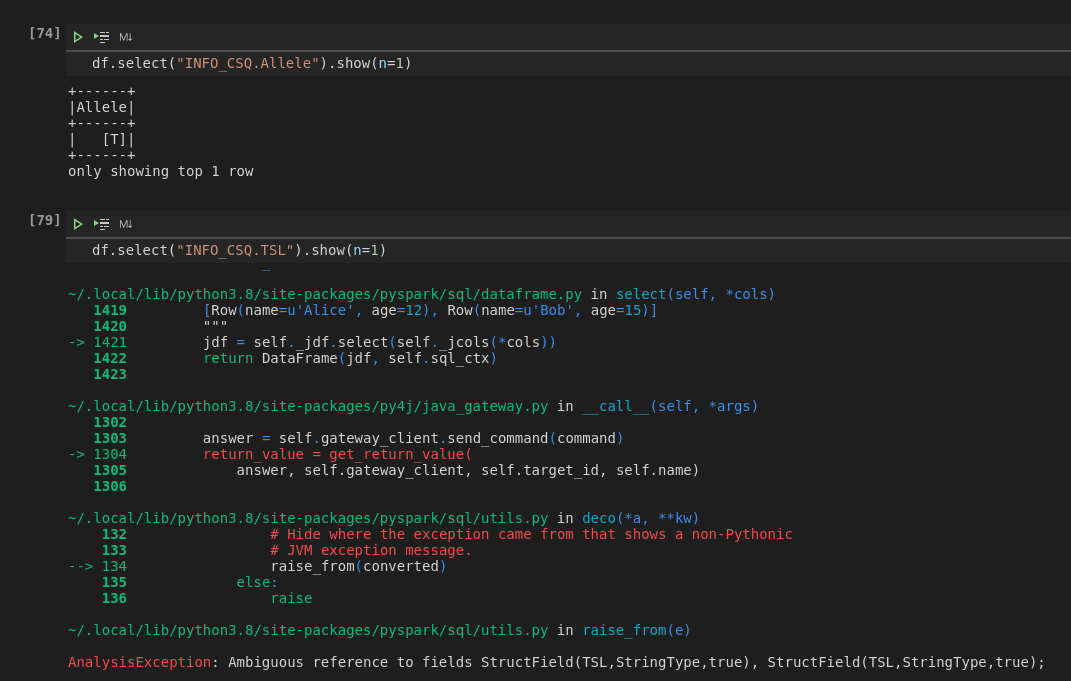
df.select("INFO_CSQ.xxx") потому что ссылка неоднозначная.
Если вам нужна дополнительная информация, не стесняйтесь спрашивать меня. Я отвечу как можно скорее.
Изменить Я видел, что многие решения используют переименование, и все они, которые я смотрел, вводятся вручную, например
strSchema = "array<struct<a_renamed:string,b:bigint,c:bigint>>" и приведите к новому фрейму данных, однако моя схема может изменяться в зависимости от входного файла.
1 ответ
Вы можете преобразовать фрейм данных в RDD, а затем обратно в фрейм данных. При повторном создании фрейма данных вы можете предоставить схему, в которой имена столбцов уникальны.
Я использую упрощенный пример, где имя поля
field2 не уникален:
df = ...
df.printSchema()
#root
# |-- INFO_CSQ: array (nullable = true)
# | |-- element: struct (containsNull = true)
# | | |-- field1: string (nullable = true)
# | | |-- field2: string (nullable = true)
# | | |-- field2: string (nullable = true)
import copy
schema_with_renames = copy.deepcopy(df.schema)
seen_fields = {}
#iterate over all fields and add a suffix where necessary
for f in schema_with_renames[0].dataType.elementType.fields:
name = f.name
suffix = ""
if name in seen_fields:
suffix = seen_fields[name] + 1
seen_fields[name] = suffix
else:
seen_fields[name] = 0
f.name = f.name + str(suffix)
df2 = spark.createDataFrame(df.rdd, schema_with_renames)
df2.printSchema()
#root
# |-- INFO_CSQ: array (nullable = true)
# | |-- element: struct (containsNull = true)
# | | |-- field1: string (nullable = true)
# | | |-- field2: string (nullable = true)
# | | |-- field21: string (nullable = true)
Теперь вы можете удалить или игнорировать переименованное поле.
field21.