Запуск ядра в pyCUDA дает странные результаты (Earth Movers Distance)
Я пытаюсь запустить программу CUDA через colab с pyCUDA, чтобы рассчитать расстояние земных движителей для 2d изображений. Код изначально запускался через matlab и mex (исходный код) . Поскольку у меня нет Matlab в colab, я попытался запустить ядра через pyCUDA. Но, похоже, проблема в том, как я запускаю ядра, потому что получаю неверные результаты. Я предполагаю, что исходная программа должна быть правильной, потому что я использовал ее в качестве руководства для создания чистой реализации python / numpy, которая дает правильные результаты, и она использовалась в прошлом.
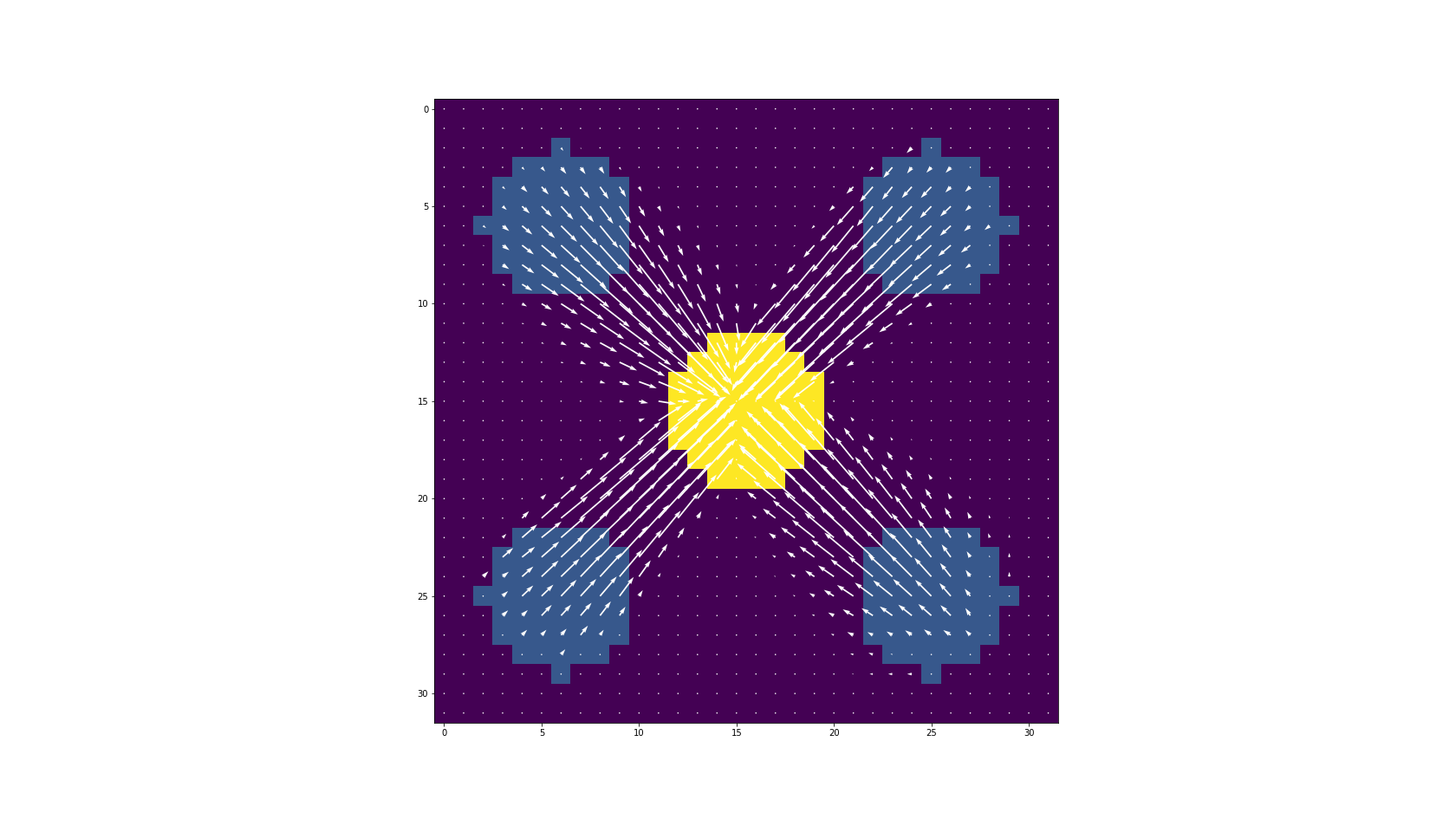
Пример того, что делает этот код, следующий. На первом изображении средняя точка является целевой точкой для масс пикселей в углах. Программное обеспечение дает векторное поле, чтобы толкать массу
lambda0 к месту назначения
lambda1посередине. Белые стрелки показывают правильное
m.
Но моя попытка pyCUDA дает мне неправильный транспорт. Все стрелки указывают в одном направлении.

Исходный код запускает два ядра (
phiUpdate,
mUpdate_l2) в
mexFunctionи выполняет итерацию по ним. В отрывке показано, как ядра изначально настраиваются и запускаются:
#include <cassert>
#include <string>
#include <ctime>
#include <iostream>
#include <cmath>
#include "somt.h"
#include "mex.h"
class mystream : public std::streambuf
{
protected:
virtual std::streamsize xsputn(const char *s, std::streamsize n) { mexPrintf("%.*s", n, s); return n; }
virtual int overflow(int c=EOF) { if (c != EOF) { mexPrintf("%.1s", &c); } return 1; }
};
class scoped_redirect_cout
{
public:
scoped_redirect_cout() { old_buf = std::cout.rdbuf(); std::cout.rdbuf(&mout); }
~scoped_redirect_cout() { std::cout.rdbuf(old_buf); }
private:
mystream mout;
std::streambuf *old_buf;
};
static scoped_redirect_cout mycout_redirect;
void mexFunction(int nlhs, mxArray *plhs[], int nrhs, mxArray const *prhs[]) {
const int d = 2;
float mu;
float tau;
int max_iter;
int norm_type;
mu = float(*mxGetPr(prhs[2]));
tau = float(*mxGetPr(prhs[3]));
max_iter = int(*mxGetPr(prhs[4]));
norm_type = int(*mxGetPr(prhs[5]));
if ( nrhs!=6 ){
mexErrMsgIdAndTxt("error:error",
"wrong number of inputs.");
}
if ( !(nlhs==1 || nlhs==3) ) {
mexErrMsgIdAndTxt("error:error",
"output should be dist or [dist U Phi]");
}
const int n = mxGetDimensions(prhs[0])[0];
const float dx = 1. / float(n - 1);
const double* lambda0_float = mxGetPr(prhs[0]);
const double* lambda1_float = mxGetPr(prhs[1]);
float* lambda0 = new float[n*n];
float* lambda1 = new float[n*n];
//convert input to float
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
lambda0[i + n*j] = float(lambda0_float[i + n*j]);
lambda1[i + n*j] = float(lambda1_float[i + n*j]);
}
}
if ( !( n==1 || n==2 || n==4 || n==8 || n==16 || n==32 || n==64 || n==128 || n==256) ) {
mexErrMsgIdAndTxt("error:error",
"n has to be a power of 2");
}
int threads_per_block;
if (n==1) {
threads_per_block = 1;
} else if (n==2) {
threads_per_block = 4;
} else if (n==4) {
threads_per_block = 16;
} else if (n==8) {
threads_per_block = 64;
} else if (n==16) {
threads_per_block = 128;
} else if (n==32) {
threads_per_block = 128;
} else if (n==64) {
threads_per_block = 256;
} else if (n==128) {
threads_per_block = 256;
} else if (n==256) {
threads_per_block = 256;
} else {
mexErrMsgIdAndTxt("error:error",
"unknown error");
}
//Problem data initialization over
//initialize m and Phi to be 0
float* m = new float[n*n*d];
memset(m, 0, sizeof(float)*n*n*d);
float* Phi = new float[n*n];
memset(Phi, 0, sizeof(float)*n*n);
float* m_prev = new float[n*n*d];
float* Phi_prev = new float[n*n];
//---------------------------------------------------------------------
//start error checking
//thread_per_block must divide number of points
assert((n*n) % threads_per_block == 0);
if (n*n / threads_per_block > 65535) {
cout << "maximum block number exceeded" << endl;
cout << "threads_per_block should be bigger" << endl;
assert(false);
}
//end error checking
//---------------------------------------------------------------------
//create CUDA pointers
float* d_lambda0;
float* d_lambda1;
float* d_m;
float* d_m_temp;
float* d_Phi;
cout << "Allocating GPU memory" << endl;
err_chk(cudaMalloc((void**)&d_lambda0, sizeof(float)*n*n));
err_chk(cudaMalloc((void**)&d_lambda1, sizeof(float)*n*n));
err_chk(cudaMalloc((void**)&d_m, sizeof(float)*n*n*d));
err_chk(cudaMalloc((void**)&d_m_temp, sizeof(float)*n*n*d));
err_chk(cudaMalloc((void**)&d_Phi, sizeof(float)*n*n));
cout << "copying memory from host to GPU" << endl;
err_chk(cudaMemcpy(d_m, m, sizeof(float)*n*n*d, cudaMemcpyHostToDevice));
err_chk(cudaMemcpy(d_Phi, Phi, sizeof(float)*n*n, cudaMemcpyHostToDevice));
err_chk(cudaMemcpy(d_lambda0, lambda0, sizeof(float)*n*n, cudaMemcpyHostToDevice));
err_chk(cudaMemcpy(d_lambda1, lambda1, sizeof(float)*n*n, cudaMemcpyHostToDevice));
cout << "starting iteration" << endl;
clock_t begin = clock();
for (int k = 0; k < max_iter; k++) {
mUpdate_l2 <<< n*n / threads_per_block, threads_per_block >>> (d_Phi, d_m, d_m_temp, n, dx, mu);
//Phi = Phi + tau*(div m_temp-lambda0_lambda1)
PhiUpdate <<< n*n / threads_per_block, threads_per_block >>> (d_Phi, d_m_temp, d_lambda0, d_lambda1, n, dx, tau);
}
float runtime = float(clock() - begin) / CLOCKS_PER_SEC;
cout << "Total runtime is " << runtime << "s." << endl;
cout << "This is " << runtime / float(max_iter) * 1000 << "ms per iteration" << endl;
err_chk(cudaMemcpy(m, d_m, sizeof(float)*n*n*d, cudaMemcpyDeviceToHost));
err_chk(cudaMemcpy(Phi, d_Phi, sizeof(float)*n*n, cudaMemcpyDeviceToHost));
if (norm_type == 1) {
plhs[0] = mxCreateDoubleScalar(wass_l1(m, n, d));
} else if (norm_type == 2) {
plhs[0] = mxCreateDoubleScalar(wass_l2(m, n, d));
} else {
assert(false);
}
if (nlhs==3) {
size_t m_dim[3] = {n,n,d};
size_t phi_dim[2] = {n,n};
plhs[1] = mxCreateNumericArray(3, m_dim, mxDOUBLE_CLASS, mxREAL);
plhs[2] = mxCreateNumericArray(2, phi_dim, mxDOUBLE_CLASS, mxREAL);
double* m_out = mxGetPr(plhs[1]);
double* phi_out = mxGetPr(plhs[2]);
for (int ii=0; ii<n*n*d; ii++)
m_out[ii] = double(m[ii]);
for (int ii=0; ii<n*n; ii++)
phi_out[ii] = double(Phi[ii]);
}
cout << "freeing CUDA resources" << endl;
cudaFree(d_lambda0);
cudaFree(d_lambda1);
cudaFree(d_m);
cudaFree(d_m_temp);
cudaFree(d_Phi);
cout << "freeing host resources" << endl;
delete[] lambda0;
delete[] lambda1;
delete[] m;
delete[] Phi;
delete[] m_prev;
delete[] Phi_prev;
}
__global__ void mUpdate_l2(const float* __restrict__ d_Phi, float* d_m, float* d_m_temp, int n, float dx, float mu) {
int N = n*n;
int ii = blockDim.x*blockIdx.x + threadIdx.x;
int i = ii % n;
int j = ii / n;
float local_d_m_x = d_m[ii + N * 0];
float local_d_m_y = d_m[ii + N * 1];
float local_d_m_temp_x;
float local_d_m_temp_y;
//m_temp = m;
local_d_m_temp_x = local_d_m_x;
local_d_m_temp_y = local_d_m_y;
//m_i = m_i + \mu \nabla \Phi
if (i < n - 1)
local_d_m_x += mu * (d_Phi[(i + 1) + n*j] - d_Phi[ii]) / dx;
// else
// local_d_m_x = 0;
if (j < n - 1)
local_d_m_y += mu * (d_Phi[i + n*(j + 1)] - d_Phi[ii]) / dx;
//Shrink2
float shrink_factor, norm;
norm = sqrt(local_d_m_x*local_d_m_x + local_d_m_y*local_d_m_y);
if (norm <= mu)
shrink_factor = 0.0f;
else
shrink_factor = 1 - mu / norm;
local_d_m_x *= shrink_factor;
local_d_m_y *= shrink_factor;
d_m[ii + N * 0] = local_d_m_x;
d_m[ii + N * 1] = local_d_m_y;
//m_temp = 2m - m_temp
d_m_temp[ii + N * 0] = 2.0f * local_d_m_x - local_d_m_temp_x;
d_m_temp[ii + N * 1] = 2.0f * local_d_m_y - local_d_m_temp_y;
}
__global__ void PhiUpdate(float* d_Phi, const float* __restrict__ d_m_temp, const float* __restrict__ d_lambda0, const float* __restrict__ d_lambda1, int n, float dx, float tau) {
int N = n*n;
int ii = blockDim.x*blockIdx.x + threadIdx.x;
int i = ii % n;
int j = (ii / n);
//divm = divergence * m_temp
float m_minus;
float divm = 0.0f;
//x-gradient on m_x
if (i >= 1)
m_minus = d_m_temp[(i - 1) + n*j + N * 0];
else
m_minus = 0.0f;
divm += (d_m_temp[ii + N * 0] - m_minus) / dx;
//y-gradient on m_y
if (j >= 1)
m_minus = d_m_temp[i + n*(j - 1) + N * 1];
else
m_minus = 0.0f;
divm += (d_m_temp[ii + N * 1] - m_minus) / dx;
//Phi = Phi + tau ( divergence * (2m - m_temp) + lambda1 - lambda0 )
d_Phi[ii] += tau * (divm + d_lambda1[ii] - d_lambda0[ii]);
}
И это моя попытка в pyCUDA:
import pycuda.driver as cuda
import pycuda.autoinit
from pycuda.compiler import SourceModule
import numpy as np
import matplotlib.pyplot as plt
modSomt = SourceModule("""
__global__ void mUpdate_l2(const float* __restrict__ d_Phi, float* d_m, float* d_m_temp, int n, float dx, float mu) {
int N = n*n;
int ii = blockDim.x*blockIdx.x + threadIdx.x;
int i = ii % n;
int j = ii / n;
float local_d_m_x = d_m[ii + N * 0];
float local_d_m_y = d_m[ii + N * 1];
float local_d_m_temp_x;
float local_d_m_temp_y;
//m_temp = m;
local_d_m_temp_x = local_d_m_x;
local_d_m_temp_y = local_d_m_y;
if (i < n - 1)
local_d_m_x += mu * (d_Phi[(i + 1) + n*j] - d_Phi[ii]) / dx;
// else
// local_d_m_x = 0;
if (j < n - 1)
local_d_m_y += mu * (d_Phi[i + n*(j + 1)] - d_Phi[ii]) / dx;
//Shrink2
float shrink_factor, norm;
norm = sqrt(local_d_m_x*local_d_m_x + local_d_m_y*local_d_m_y);
if (norm <= mu)
shrink_factor = 0.0f;
else
shrink_factor = 1 - mu / norm;
local_d_m_x *= shrink_factor;
local_d_m_y *= shrink_factor;
d_m[ii + N * 0] = local_d_m_x;
d_m[ii + N * 1] = local_d_m_y;
//m_temp = 2m - m_temp
d_m_temp[ii + N * 0] = 2.0f * local_d_m_x - local_d_m_temp_x;
d_m_temp[ii + N * 1] = 2.0f * local_d_m_y - local_d_m_temp_y;
}
__global__ void PhiUpdate(float* d_Phi, const float* __restrict__ d_m_temp, const float* __restrict__ d_lambda0, const float* __restrict__ d_lambda1, int n, float dx, float tau) {
int N = n*n;
int ii = blockDim.x*blockIdx.x + threadIdx.x;
int i = ii % n;
int j = (ii / n);
//divm = divergence * m_temp
float m_minus;
float divm = 0.0f;
//x-gradient on m_x
if (i >= 1)
m_minus = d_m_temp[(i - 1) + n*j + N * 0];
else
m_minus = 0.0f;
divm += (d_m_temp[ii + N * 0] - m_minus) / dx;
//y-gradient on m_y
if (j >= 1)
m_minus = d_m_temp[i + n*(j - 1) + N * 1];
else
m_minus = 0.0f;
divm += (d_m_temp[ii + N * 1] - m_minus) / dx;
//Phi = Phi + tau ( divergence * (2m - m_temp) + lambda1 - lambda0 )
d_Phi[ii] += tau * (divm + d_lambda1[ii] - d_lambda0[ii]);
}
""")
n = np.int32(32)
d=np.int32(2)
dx = np.float32(1/(n-1))
XX,YY = np.meshgrid(np.linspace(-2,2,n),np.linspace(-2,2,n))
lambda0 = np.zeros((n,n))
lambda1 = np.zeros((n,n))
lambda0 += (XX-1.25)**2 + (YY-1.25)**2 < 0.25
lambda0 += (XX+1.25)**2 + (YY+1.25)**2 < 0.25
lambda0 += (XX-1.25)**2 + (YY+1.25)**2 < 0.25
lambda0 += (XX+1.25)**2 + (YY-1.25)**2 < 0.25
lambda1 += XX**2 +YY**2 < 0.25
tau = np.float32(1)
mu = np.float32(1/(tau*16*(n-1)**2))
lambda0 /= lambda0.sum()
lambda1 /= lambda1.sum()
lambda0 = lambda0.astype(np.float32)
lambda1 = lambda1.astype(np.float32)
m = np.ones((n,n,d)).astype(np.float32)
phi = np.ones((n,n)).astype(np.float32)
d_lambda0 = cuda.mem_alloc(lambda0.nbytes) #allocations
d_lambda1 = cuda.mem_alloc(lambda1.nbytes)
d_m = cuda.mem_alloc(m.nbytes)
d_m_temp = cuda.mem_alloc(m.nbytes)
d_phi = cuda.mem_alloc(phi.nbytes)
plt.imshow(lambda0+lambda1)
mUpdate = modSomt.get_function("mUpdate_l2")
phiUpdate = modSomt.get_function("PhiUpdate")
threads_per_block = 1
if n==1:
threads_per_block = 1
elif n==2:
threads_per_block = 4
elif n==4:
threads_per_block = 16
elif n==8:
threads_per_block = 64
elif n==16:
threads_per_block = 128
elif n==32:
threads_per_block = 128
elif n==64:
threads_per_block = 256
elif n==128:
threads_per_block = 256
elif n==256:
threads_per_block = 256
gridsize = (int(n*n/threads_per_block),1,1)
blocksize = (threads_per_block,1,1)
assert((n*n) % threads_per_block == 0)
cuda.memcpy_htod(d_lambda0, lambda0) # host to device
cuda.memcpy_htod(d_lambda1, lambda1)
cuda.memcpy_htod(d_m, m)
cuda.memcpy_htod(d_phi, phi)
for k in range(2000):
mUpdate(d_phi, d_m, d_m_temp, n, dx, mu, grid=gridsize, block = blocksize)
phiUpdate(d_phi, d_m_temp, d_lambda1, d_lambda1, n, dx, tau, grid=gridsize, block = blocksize)
cuda.memcpy_dtoh(phi, d_phi)
cuda.memcpy_dtoh(m, d_m)
XX,YY = np.meshgrid(np.linspace(0,n-1,n),np.linspace(0,n-1,n))
plt.imshow(lambda0)
plt.quiver(XX,YY,m[:,:,0],m[:,:,1], color= "red")
Мой код Python, который произвел правильный транспорт, - это
import numpy as np
import matplotlib.pyplot as plt
def shrink1(x,mu):
return np.nan_to_num((1-mu/np.abs(x))*x*(np.abs(x)>= mu))
def shrink2(x,mu):
norm_2 = np.linalg.norm(x,axis=0)
return np.nan_to_num((1-mu/norm_2)*x*(norm_2>= mu))
def div_x(m,dx):
#phi(2:Mx,:) = phi(2:Mx,:) + (m(2:end,:,1) - m(1:end-1,:,1) )/dx;
div = np.zeros_like(m[0,:,:])
div[0,:] += m[0,0,:]/dx
div[1:,:] += (m[0,1:,:] - m[0,0:-1,:])/dx
div[:,0] += m[1,:,0]/dx
div[:,1:] += (m[1,:,1:] - m[1,:,0:-1])/dx
return div
def getlambda(n, select = 0):
lambda0 = np.zeros((n,n))
lambda1 = np.zeros((n,n))
#middle to corner
if select == 0:
lambda0 += (XX-1.25)**2 + (YY-1.25)**2 < 0.25
lambda0 += (XX+1.25)**2 + (YY+1.25)**2 < 0.25
lambda0 += (XX-1.25)**2 + (YY+1.25)**2 < 0.25
lambda0 += (XX+1.25)**2 + (YY-1.25)**2 < 0.25
lambda1 += XX**2 +YY**2 < 0.25
#circle
if select == 1:
lambda0 += np.abs(XX**2 + YY**2 - 1.5) < 0.1
#lambda0 += np.abs(XX**2 + YY**2 - 2) < 0.1
lambda1 += XX**2 +YY**2 < 0.25
#lambda1 += np.abs(XX**2 + YY**2 - 3) < 0.1
pass
#right vs left
if select == 2:
lambda0 += (XX+1)**2 +YY**2 < 0.25
lambda1 += (XX-1)**2 +YY**2 < 0.25
if select == 3:
lambda0 += (XX-1)**2 +(YY+1.25)**2 < 0.25
lambda1 += (XX-1)**2 +(YY-1.25)**2 < 0.25
pass
if select == 4:
lambda1 += (XX-1.25)**2 + (YY+1.25)**2 < 0.25
lambda0 += (XX+1.25)**2 + (YY-1.25)**2 < 0.25
lambda0 /= lambda0.sum()
lambda1 /= lambda1.sum()
return lambda0, lambda1
n = 32
XX,YY = np.meshgrid(np.linspace(-2,2,n),np.linspace(-2,2,n))
phi = np.ones((n,n))
#plt.imshow(phi)
m = np.zeros((2,n,n))
#phi = 1 - phi
tau = 1
dx = 1/(n-1)
mu = 1/(tau*16*(n-1)**2)
lambda0,lambda1 = getlambda(n,select= 0)
tol = 0
for k in np.arange(2000):
dx_phi = np.diff(phi, axis = 0) / dx
dy_phi = np.diff(phi, axis = 1) / dx
#padding
dx_phi = np.vstack((dx_phi,np.zeros((1,n))))
dy_phi = np.hstack((dy_phi,np.zeros((n,1))))
dphi = np.array([dx_phi,dy_phi])
m_step = shrink2(m+mu*dphi,mu)
s_arg = m+mu*dphi
phi += div_x(2*m_step - m,dx) + lambda1 - lambda0
divx = div_x(2*m_step - m,dx)
m = m_step
plt.figure(2)
plt.cla()
XXX,YYY = np.meshgrid(np.linspace(0,n-1,n),np.linspace(0,n-1,n))
plt.imshow(lambda0+lambda1)
plt.quiver(XXX,YYY,m[1,:,:],m[0,:,:]*-1, color = "white")
print("norm of m: ", np.linalg.norm(m))