Как реализовать быструю нечеткую поисковую систему с использованием BK-дерева, когда в корпусе содержится 10 миллиардов уникальных последовательностей ДНК?
Я пытаюсь использовать структуру данных BK-tree в python для хранения корпуса с ~10 миллиардами записей (
1e10) для реализации быстрой нечеткой поисковой системы.
Как только я добавлю более ~10 миллионов (
1e7) значений в одно BK-дерево, я начинаю замечать значительное снижение производительности запросов.
Я думал сохранить корпус в лесу из тысячи BK-деревьев и запрашивать их параллельно.
Кажется ли, что эта идея осуществима? Должен ли я одновременно создавать и запрашивать 1000 BK-деревьев? Что еще можно сделать, чтобы использовать BK-дерево для этого корпуса.
Я использую pybktree.py, и мои запросы предназначены для поиска всех записей на расстоянии редактирования
d.
Есть ли какая-то архитектура или база данных, которые позволят мне хранить эти деревья?
Примечание: у меня не заканчивается память, дерево становится неэффективным (возможно, у каждого узла слишком много потомков).
3 ответа
Нечеткий
Поскольку вы упоминаете об использовании FuzzyWuzzy в качестве метрики расстояния, я сосредоточусь на эффективных способах реализации алгоритма, используемого FuzzyWuzzy. FuzzyWuzzy предоставляет две следующие реализации:
- difflib, который полностью реализован на Python
- python-Levenshtein, который использует взвешенное расстояние Левенштейна с весом 2 для замен (замены - это удаление + вставка). Python-Levenshtein реализован на C и намного быстрее, чем реализация на чистом Python.
Реализация на Python-Левенштейне
Реализация
- удаляет общий префикс и суффикс двух строк, поскольку они не влияют на конечный результат. Это можно сделать за линейное время, поэтому сопоставление похожих строк происходит очень быстро.
- Расстояние Левенштейна между обрезанными строками реализуется с помощью квадратичного времени выполнения и линейного использования памяти.
RapidFuzz
Я являюсь автором библиотеки RapidFuzz, которая реализует алгоритмы, используемые FuzzyWuzzy, более производительно. RapidFuzz использует следующий интерфейс для:
def ratio(s1, s2, processor = None, score_cutoff = 0)
Дополнительный параметр может использоваться для предоставления порога оценки в виде числа с плавающей запятой между 0 и 100. Для ratio <score_cutoff вместо него возвращается 0. В некоторых случаях это может быть использовано реализацией для использования более оптимизированной реализации. Далее я опишу оптимизацию, используемую RapidFuzz в зависимости от входных параметров. Далее подразумевается максимальное расстояние, которое возможно без получения коэффициента ниже порогового значения.
максимальное расстояние == 0
Сходство можно вычислить с помощью прямого сравнения, поскольку между строками не допускается различие. Временная сложность этого алгоритма составляет.
максимальное расстояние == 1 и len (s1) == len(s2)
Сходство также можно вычислить с помощью прямых сравнений, так как замена приведет к тому, что расстояние редактирования будет выше максимального расстояния. Временная сложность этого алгоритма составляет.
Удалить общий префикс
Общий префикс / суффикс двух сравниваемых строк не влияет на расстояние Левенштейна, поэтому аффикс удаляется перед вычислением сходства. Этот шаг выполняется для любого из следующих алгоритмов.
максимальное расстояние <= 4
Используется алгоритм mbleven. Этот алгоритм проверяет все возможные операции редактирования, которые возможны ниже порогового значения.
len(более короткая строка) <= 64 после удаления общего аффикса
Используется алгоритм BitPAl, который параллельно вычисляет расстояние Левенштейна. Алгоритм описан здесь и расширен поддержкой UTF32 в этой реализации. Временная сложность этого алгоритма составляет
Струны длиной> 64
Расстояние Левенштейна рассчитывается с использованием метода Вагнера-Фишера с оптимизацией Укконенса. Временная сложность этого алгоритма составляет
Улучшения процессоров
FuzzyWuzzy предоставляет несколько таких процессоров, которые используются для вычисления сходства между запросом и множественным выбором. Реализация этого в C++ также позволяет сделать еще две важные оптимизации:
когда используется счетчик, который также реализован на C++, мы можем напрямую вызывать реализацию счетчика на C++, и нам не нужно переключаться между Python и C++, что обеспечивает значительное ускорение
Мы можем предварительно обработать запрос в зависимости от используемого счетчика. В качестве примера, когда
Пока реализованы только и на Python, а
Контрольные точки
Я провел тесты для отдельных счетчиков во время разработки, которые показывают разницу в производительности между RapidFuzz и FuzzyWuzzy. Имейте в виду, что производительность для вашего случая (длина всех строк 20), вероятно, не так хороша, поскольку многие строки в используемом наборе данных очень малы.
Источник воспроизводимых научных ДАННЫХ:
words.txt(набор данных из 99171 слов)
Аппаратное обеспечение, на котором были запущены графические тесты (спецификация):
- Процессор: одноядерный i7-8550U
- Оперативная память: 8 ГБ
- ОС: Fedora 32
Контрольные показатели
Код для этого теста можно найти здесь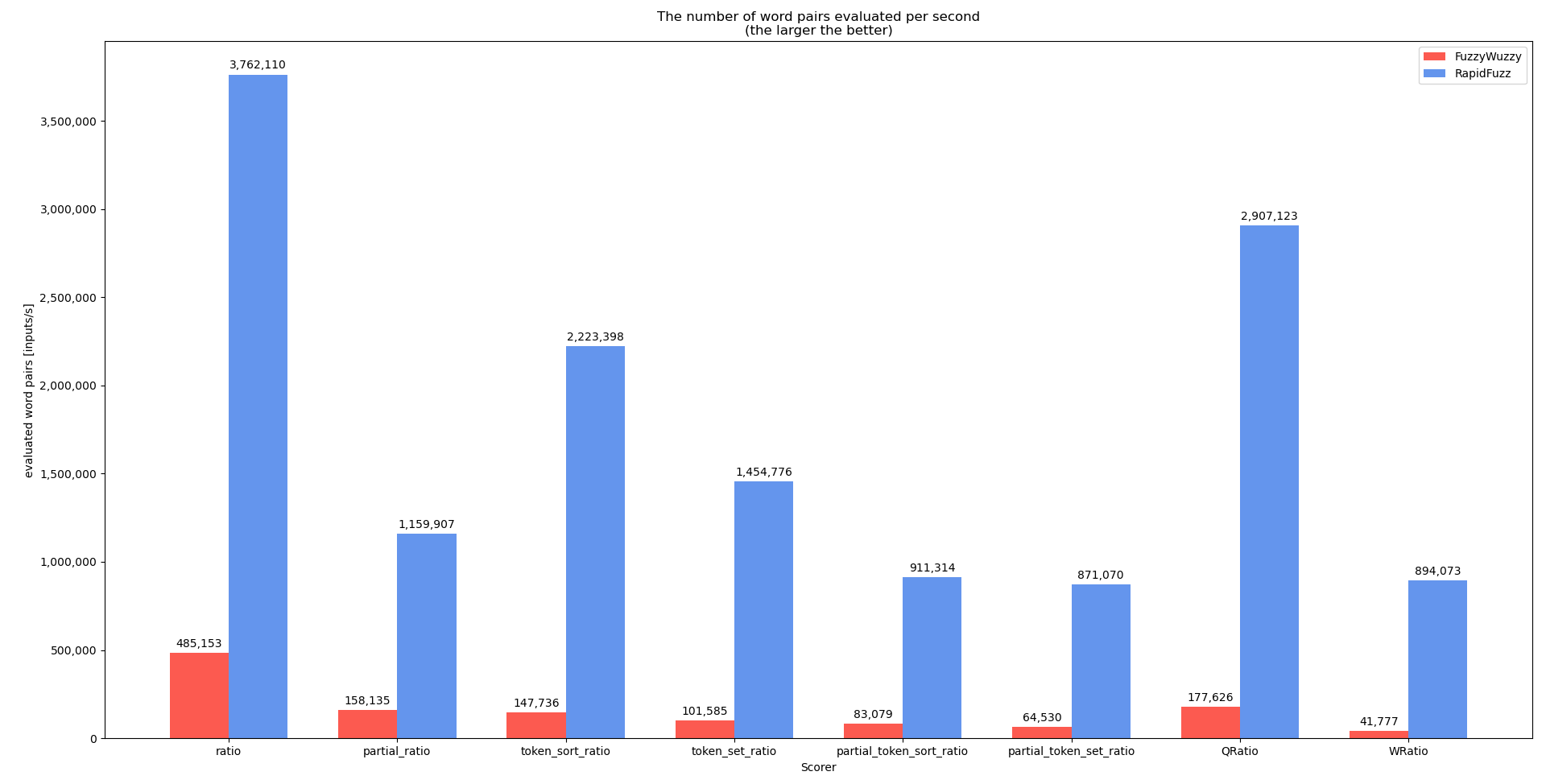
Эталонный экстрактOne
Для этого теста код немного изменен, чтобы удалить параметр. Это сделано потому, что в
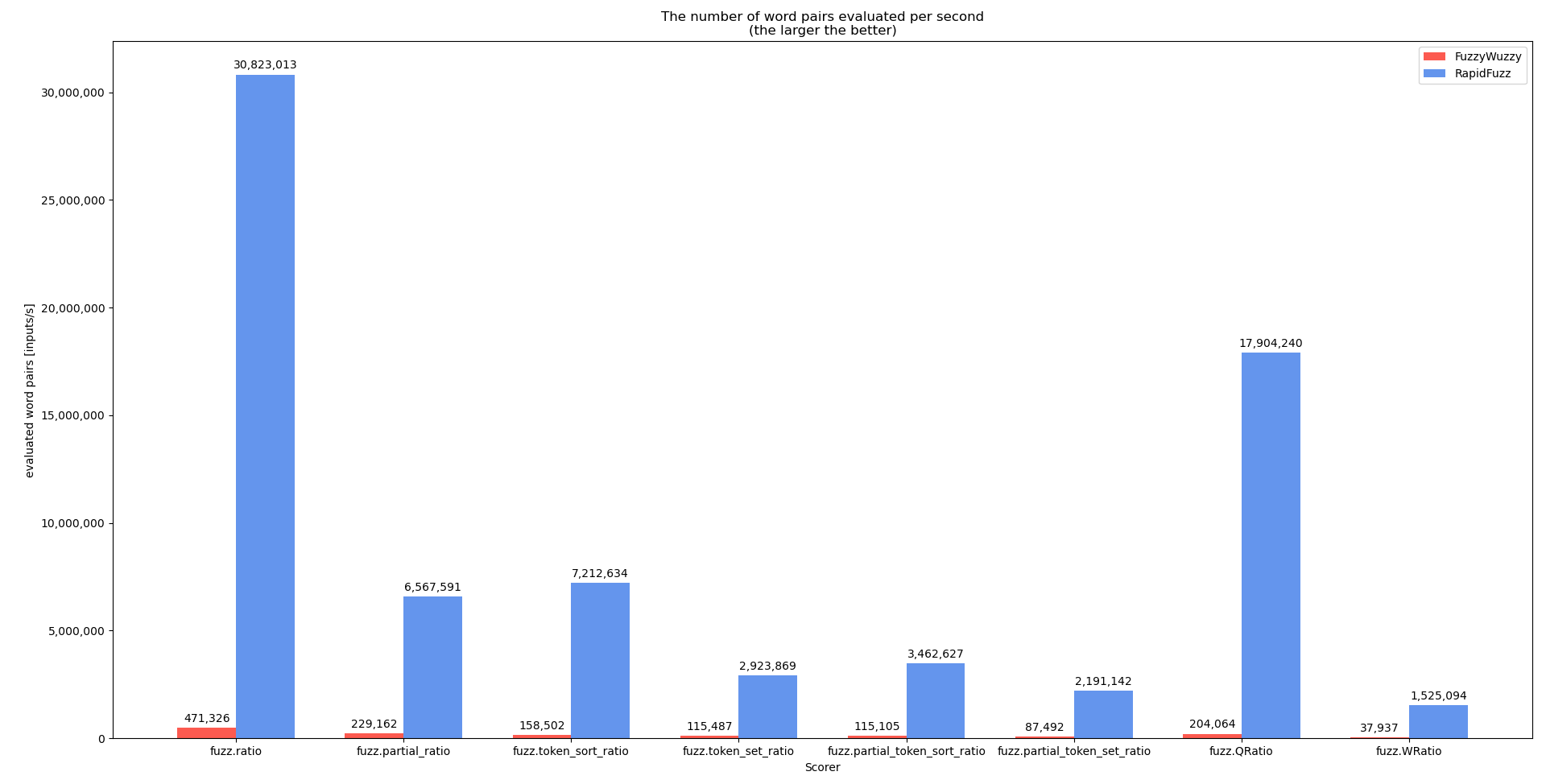
Это показывает, что, когда это возможно, счетчики должны использоваться не напрямую, а через процессоры, которые могут выполнять гораздо больше оптимизаций.
Альтернатива
В качестве альтернативы вы можете использовать реализацию на C++. Библиотека RapidFuzz доступна для C++ здесь. Реализация на C++ также относительно проста.
// function to load words into vector
std::vector<std::string> choices = load("words.txt");
std::string query = choices[0];
std::vector<double> results;
results.reserve(choices.size());
rapidfuzz::fuzz::CachedRatio<decltype(query)> scorer(query);
for (const auto& choice : choices)
{
results.push_back(scorer.ratio(choice));
}
или параллельно используя open mp
// function to load words into vector
std::vector<std::string> choices = load("words.txt");
std::string query = choices[0];
std::vector<double> results;
results.reserve(choices.size());
rapidfuzz::fuzz::CachedRatio<decltype(query)> scorer(query);
#pragma omp parallel for
for (const auto& choice : choices)
{
results.push_back(scorer.ratio(choice));
}
На моей машине (см. Выше) это оценивает 43 миллиона слов в секунду и 123 миллиона слов в секунду в параллельной версии. Это примерно в 1,5 раза быстрее, чем реализация Python (из-за преобразований между типами Python и C++). Однако основным преимуществом версии C++ является то, что вы относительно свободны комбинировать алгоритмы, как хотите, в то время как в версии Python вы вынуждены использовать
Несколько мыслей
BK-деревья
Престижность Бену Хойту и его ссылка на проблему, из которой я буду черпать. При этом первое наблюдение из упомянутой проблемы заключается в том, что дерево BK не совсем логарифмическое. Из того, что вы нам сказали, ваш обычный d равен ~6, что составляет 3/10 длины вашей строки. К сожалению, это означает, что если мы посмотрим на таблицы из проблемы, вы получите сложность где-то между O (N ^ 0,8) и O (N). В оптимистическом случае, когда показатель степени равен 0,8 (он, вероятно, будет немного хуже), вы получите коэффициент улучшения ~100 для ваших 10B записей. Так что, если у вас есть достаточно быстрая реализация BK-деревьев, все же стоит использовать их или использовать в качестве основы для дальнейшей оптимизации.
Обратной стороной этого является то, что даже если вы используете 1000 деревьев параллельно, вы получите только улучшение от распараллеливания, поскольку производительность деревьев зависит от d, а не от количества узлов в дереве. Однако, даже если вы запустите все 1000 деревьев одновременно на массивной машине, мы находимся на ~10M узлов / дереве, о которых вы сообщили как медленные. Тем не менее, с точки зрения вычислений, это кажется выполнимым.
Подход грубой силы.
Если вы не против немного заплатить, я бы посмотрел на что-то вроде большого запроса Google Cloud, если это не противоречит какой-либо конфиденциальности данных. Они предложат вам решение методом грубой силы - за определенную плату. Текущая ставка составляет 5 долларов за ТБ запроса. Ваш набор данных составляет ~10 млрд строк * 20 символов. Принимая один байт на символ, один запрос займет 200 ГБ, так что ~1 доллар за запрос, если вы пошли ленивым путем.
Однако, поскольку плата взимается за байт данных в столбце, а не за сложность вопроса, вы можете улучшить это, сохранив свои строки в виде битов - 2 бита на букву, это сэкономит вам 75% расходов.
При дальнейшем улучшении вы можете написать свой запрос таким образом, чтобы он запрашивал сразу дюжину строк. Возможно, вам придется проявить осторожность при использовании пакета похожих строк для запроса, чтобы избежать засорения результата слишком большим количеством одноразовых запросов.
Грубая форсировка BK-деревьев
Поскольку, если вы пойдете по указанному выше маршруту, вам придется платить в зависимости от объема, ~100-кратное уменьшение необходимых вычислений становится ~100-кратным снижением цены, что может быть полезно, особенно если вам нужно выполнить много запросов.
Однако вам нужно будет найти способ сохранить это дерево на нескольких уровнях баз данных для рекурсивного запроса, поскольку цена Bigquery зависит от объема данных в запрашиваемой таблице.
Создание интеллектуального пакетного движка для рекурсивной обработки запросов с целью минимизации затрат может быть забавным упражнением по оптимизации.
Выбор языка
Еще одно. Хотя я считаю, что Python - хороший язык для быстрого прототипирования, анализа и обдумывания кода в целом, вы уже прошли этот этап. В настоящее время вы ищете способ как можно быстрее выполнить конкретную, четко определенную и хорошо продуманную операцию. Как показывает этот пример, Python не лучший язык для этого . Хотя я использовал все приемы, которые только мог придумать в Python, решения на Java и C все же были в несколько раз быстрее. (Не говоря уже о ржавчине, которая победила всех нас - но он также победил нас по алгоритму, так что сравнивать его трудно.) Так что, если вы перейдете с питона на более быстрый язык, вы можете получить еще один фактор или десять, а может, даже больше прирост производительности. Это может быть еще одним забавным упражнением по оптимизации.
Примечание: Я довольно консервативен с оценкой, поскольку fuzzywuzzy уже предлагает использовать библиотеку C в фоновом режиме, поэтому я не слишком уверен в том, какая часть работы все еще зависит от питона. Мой опыт в подобных случаях показывает, что прирост производительности может быть в 100 раз от чистого питона (или, что еще хуже, чистого R) до скомпилированного языка.
Довольно поздно для вечеринки, но вот возможное решение, которое я бы реализовал, если бы был в вашей ситуации:
Сохраните набор данных как текстовый файл и поместите этот файл на очень быстрый участок диска (желательно на tmpfs).
Подготовьте мощный компьютер с большим количеством физических ядер ЦП (например, Threadripper 3990X с 64 ядрами).
Используйте эту реализацию и параллели GNU для сбора набора данных.
Вот немного технической информации об этом решении:
Оптимизированная версия алгоритма Майерса (ссылка выше) может обрабатывать около 14 миллионов записей в секунду на одном ядре ЦП.
Если вы можете полностью использовать все 64 физических ядра, вы можете архивировать пропускную способность 896 миллионов в секунду (= 14 миллионов * 64 ядра).
При такой скорости вы можете выполнить один запрос к 10 миллиардам наборов данных за 12 секунд, используя одну машину.
Более подробный анализ я разместил в этой статье . Как показано в статье, я мог выполнить запрос к набору данных из 100 миллионов записей за 1,04 секунды на моем дешевом настольном компьютере.
Используя более производительный процессор (или разделив задачу между несколькими компьютерами), я считаю, что вы можете заархивировать желаемый результат. Надеюсь это поможет.