Как сократить время, затрачиваемое на потоки, достигающие точки Safepoint - состояние синхронизации
О проблеме: во
время интенсивного ввода-вывода в виртуальной машине мы столкнулись с паузой / замедлением JVM из-за того, что остановка потоков занимала больше времени. При просмотре журналов безопасной точки было показано, что состояние синхронизации занимает больше всего времени.

Мы также попытались распечатать следы Safepoint по таймауту (-XX:+SafepointTimeout -XX:SafepointTimeoutDelay=200), чтобы узнать, какие потоки вызывают эту проблему, но ничего подозрительного не было. Также при установке тайм-аута для точек сохранения мы не получаем распечатку с обнаружением тайм-аута, когда время, проведенное в состоянии «Синхронизация».
Вопросы об этой трассировке точки сохранения:
- Как работает тайм-аут точки сохранения?
- После регистрации сведений о потоке существует ли точка сохранения и все потоки возобновляются?
- Будет ли выполнена эта операция ВМ? Что будет, если vmop будет GC.
Использование Async-profiler:
попробовал профилирование time-to-safepoint с помощью async-profiler и заметил, что VM Thread требует больше времени на метод SafepointSynchronize::begin(), а потоки компилятора C2 занимают почти столько же времени, что и поток VM.
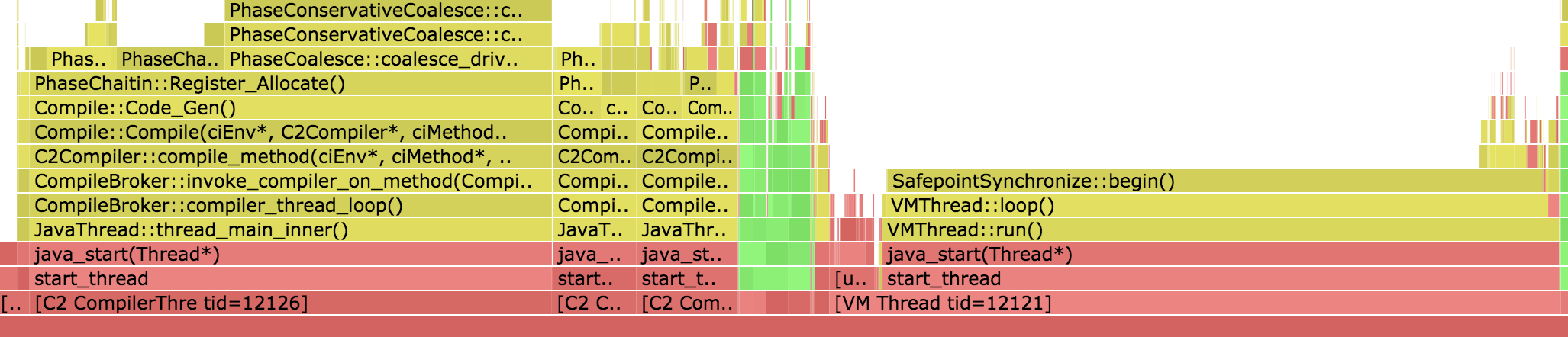
Мы сомневаемся, что компиляторам C2 может потребоваться время, чтобы достичь точки безопасности. Может ли кто-нибудь помочь нам в решении этой проблемы и интерпретации этого флеймографа времени до безопасной точки. Заранее спасибо.
1 ответ
опция влияет только на ведение журнала, т.е. потоки не будут прерваны, работа ВМ будет работать нормально и т. д.
не всегда распечатывает потоки с истекшим временем ожидания: поток, возможно, уже достиг точки безопасности к моменту выполнения печати. Более того,
SafepointTimeout может даже не обнаружить тайм-аут, если весь процесс был заморожен операционной системой.
Например, таких "зависаний" много бывает.
- когда процесс исчерпал свою квоту процессора в контрольной группе (контейнере);
- когда системе не хватает физической памяти и происходит прямое восстановление ;
- из-за активности другого процесса (например, я наблюдал длинные паузы JVM, когда
atopУтилита проверила систему).
async-profiler действительно имеет параметр профилирования времени до безопасной точки (
--ttsp), хотя его правильное использование может показаться сложным. Лучше всего работает в
wall режим профилирования с
jfrвыход. В этой конфигурации async-profiler будет проверять все потоки (как запущенные, так и блокирующие) во время синхронизации точки безопасности и записывать каждое отдельное событие с отметкой времени.
Затем такой профиль можно проанализировать с помощью JDK Mission Control: выберите временной интервал вокруг длинной паузы и посмотрите на трассировку стека потоков Java в этом интервале.
Обратите внимание, что если процесс JVM «заморожен», поток async-profiler также не работает, т.е. вы не увидите собранные образцы в течение этого периода. Обычно в режиме профилирования настенных часов все резьбы отбираются равномерно. Но если вы видите «пробел» (пропущенные события в течение некоторого промежутка времени), это, по-видимому, означает, что процесс JVM не получил процессорного времени. В этом случае причина пауз JVM не в приложении Java, а в операционной системе / среде.