Как напечатать рукописный текст внутри ограничительных рамок, используя открытое резюме
Я пытаюсь распознать рукописный текст (заглавные и буквенно-цифровые) и распечатать его.
Я использовал код, указанный в этой ссылке. распознавание слова от руки
Я также могу получать разные алфавиты отдельно в ограничивающих прямоугольниках, и это дает такие результаты. 
У меня есть два вопроса
1 - я хочу распечатать текст внутри ограничивающих рамок
2- при непрерывной записи он рассматривает все слово, как показано на
вывод в github-ссылке, но здесь рассматриваются только алфавиты.
вот вывод для строчных букв непрерывной записи
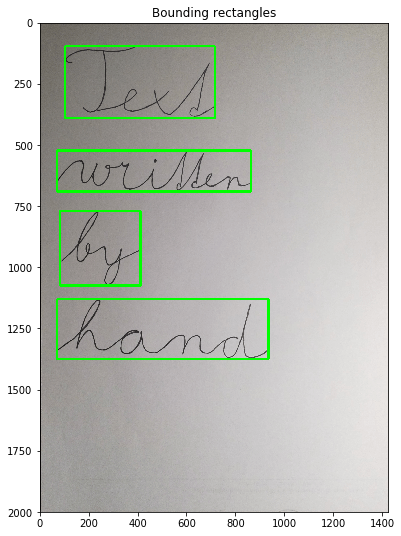
Кто-нибудь может дать мне направление относительно того, как я могу сделать это с капиталом
а также как печатать текст внутри ограничивающих рамок с
Точность, чтобы он работал хорошо для заглавных букв алфавитно-цифровых.
Пожалуйста, кто-нибудь, кто мог бы направить меня по этому поводу и рассказать о том, как это сделать.
Любая помощь по распознаванию рукописного текста и текста.
1 ответ
Перед тем, как найти ограничивающую рамку, вам необходимо выполнить некоторую предварительную обработку.
Я получил двоичное изображение, используя порог из предоставленного изображения. После этого я сделал собственное ядро таким образом, чтобы в нем было больше столбцов, чем строк для выполнения морфологических операций. Таким образом, буквы, расположенные близко друг к другу, будут спарены.
Код:
custom_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (30, 10))
threshed = cv2.morphologyEx(binary_image, cv2.MORPH_CLOSE, custom_kernel)
cv2.imshow('Connected letters', threshed)

После получения этого вы можете найти ограничивающие рамки.