Как убрать пробел между английскими словами после извлечения из pdfplumber
Я извлек текст из pdf (используя pdfplumber) в txt, но между словами есть пробелы, которых нет в файле PDF. 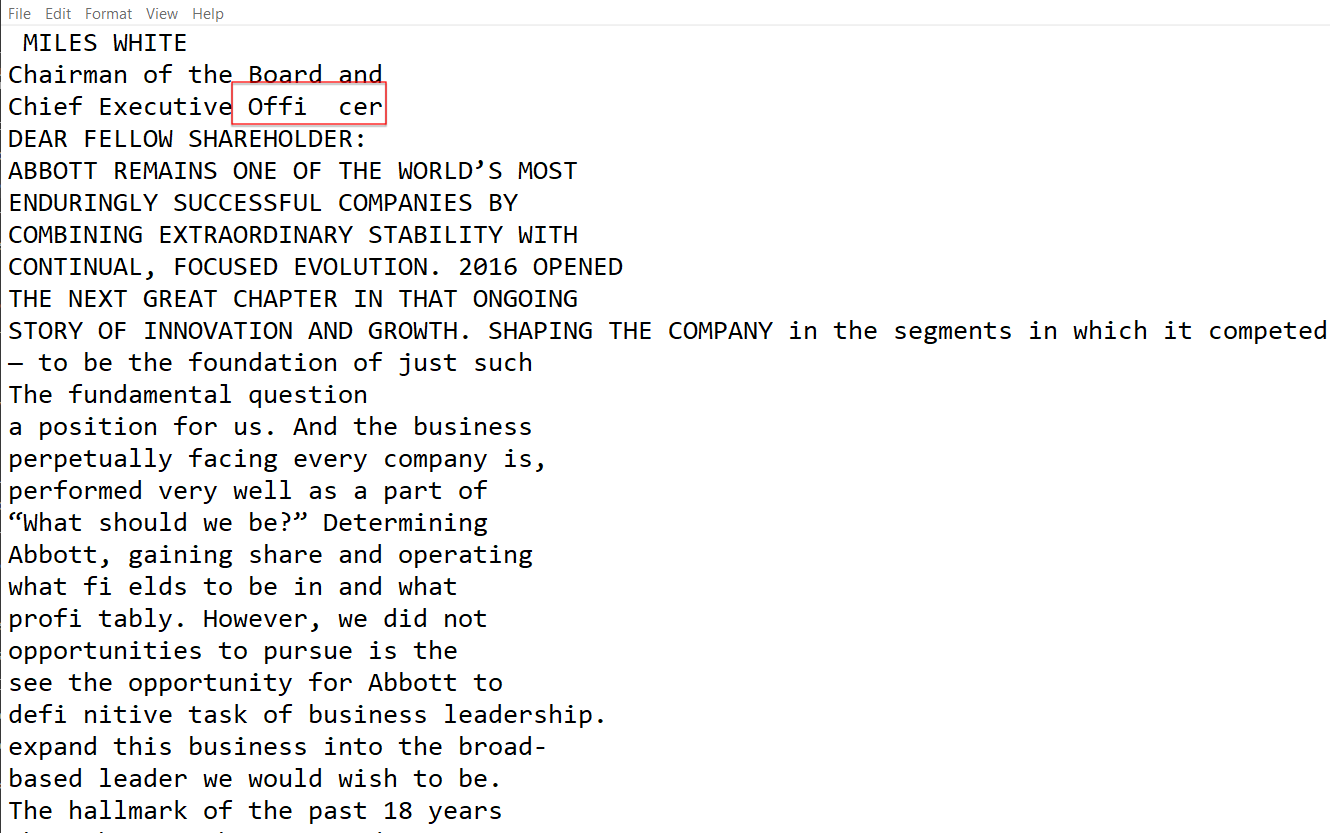
Я попытался nltk найти слова, используя комбинацию «Предыдущее_слово» + «текущее_слово» и проверить, существуют ли они в NLTK.words, чтобы узнать, где есть лишний пробел между словами, но это не работает.
Я ищу предложения, спасибо
2 ответа
Пример логики, которая помещает слова с двумя пробелами между ними в список, а затем вы можете реализовать функции, которые вам нравятся:
text = """
asdasd asd asdd d
uuurr ii ii rrr
"""
words = text.split(" ") #<- split if 1 spaces
dictionary = list() #<- dictionary list to compare
words_wrapper = list() #<- list of words with 2 spaces
for idx in range(len(words)):
if words[idx] == '':
word = f"{words[idx-1]} {words[idx+1]}"
words_wrapper.append(word)
if word in dictionary:
pass #<- do sth
# Print filtered words
print(words_wrapper)
или Вы также можете использовать .join для объединения слов с двумя пробелами вместе:
text = """
asdasd asd asdd d
uuurr ii ii rrr
"""
print("".join(text.split(" ")))
Я предлагаю искать вхождения двух следующих друг за другом слов, которых нет в вашем корпусе, что должно выявить все случаи, когда такое разделение не приводит к другому английскому слову.