Почему связывание записей в Dedupe.io дает разные идентификаторы кластера для совпадающих записей?
Привет, у меня есть следующие два файла, и я хочу найти совпадения между этими двумя файлами. Каждая запись в Test1.csv может соответствовать не более одной записи из Test2.csv, но несколько записей из Test1.csv могут соответствовать одной и той же записи в Test2.csv. Я сопоставляю имя и столбец domainWithExtension.
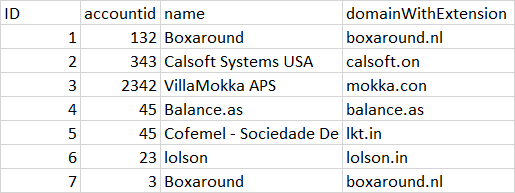

Это код:
import csv
import re
import logging
import optparse
import dedupe
from unidecode import unidecode
def preProcess(column):
column = unidecode(column)
column = re.sub('\n', ' ', column)
column = re.sub('-', '', column)
column = re.sub('/', ' ', column)
column = re.sub("'", '', column)
column = re.sub(",", '', column)
column = re.sub(":", ' ', column)
column = re.sub(' +', ' ', column)
column = column.strip().strip('"').strip("'").lower().strip()
if not column:
column = None
return column
def readData(filename):
"""
Read in our data from a CSV file and create a dictionary of records,
where the key is a unique record ID.
"""
data_d = {}
with open(filename,encoding='utf-8') as f:
reader = csv.DictReader(f)
for i, row in enumerate(reader):
clean_row = dict([(k, preProcess(v)) for (k, v) in row.items()])
data_d[filename + str(i)] = dict(clean_row)
return data_d
if __name__ == '__main__':
optp = optparse.OptionParser()
optp.add_option('-v', '--verbose', dest='verbose', action='count',
help='Increase verbosity (specify multiple times for more)'
)
(opts, args) = optp.parse_args()
log_level = logging.WARNING
if opts.verbose:
if opts.verbose == 1:
log_level = logging.INFO
elif opts.verbose >= 2:
log_level = logging.DEBUG
logging.getLogger().setLevel(log_level)
output_file = 'data_matching_output.csv'
settings_file = 'data_matching_learned_settings'
training_file = 'data_matching_training.json'
left_file = 'Test1.csv'
right_file = 'Test2.csv'
print('importing data ...')
data_1 = readData(left_file)
data_2 = readData(right_file)
if os.path.exists(settings_file):
print('reading from', settings_file)
with open(settings_file, 'rb') as sf:
linker = dedupe.StaticRecordLink(sf)
else:
fields = [
{'field' : 'name', 'type': 'String', 'has missing': True},
{'field' : 'domainWithExtension', 'type': 'String', 'has missing': True},
]
linker = dedupe.RecordLink(fields)
if os.path.exists(training_file):
print('reading labeled examples from ', training_file)
with open(training_file) as tf:
linker.prepare_training(data_1,
data_2,
training_file=tf,
sample_size=15000)
else:
linker.prepare_training(data_1, data_2, sample_size=15000)
print('starting active labeling...')
dedupe.console_label(linker)
linker.train()
with open(training_file, 'w') as tf:
linker.write_training(tf)
with open(settings_file, 'wb') as sf:
linker.write_settings(sf)
print('clustering...')
linked_records = linker.join(data_1, data_2, 0.5, constraint='many-to-one')
print(linked_records)
print('# duplicate sets', len(linked_records))
cluster_membership = {}
for cluster_id, (cluster, score) in enumerate(linked_records):
for record_id in cluster:
cluster_membership[record_id] = {'Cluster ID': cluster_id,
'Link Score': score}
print(cluster_membership)
with open(output_file, 'w',encoding = "utf-8") as f:
header_unwritten = True
for fileno, filename in enumerate((left_file, right_file)):
with open(filename,encoding = "utf-8") as f_input:
reader = csv.DictReader(f_input)
if header_unwritten:
fieldnames = (['Cluster ID', 'Link Score', 'source file'] +
reader.fieldnames)
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
header_unwritten = False
for row_id, row in enumerate(reader):
record_id = filename + str(row_id)
cluster_details = cluster_membership.get(record_id, {})
row['source file'] = fileno
row.update(cluster_details)
writer.writerow(row)
Это работает и дает следующий результат:
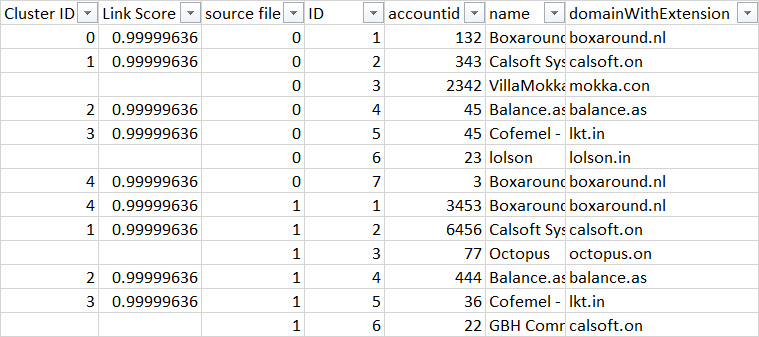
Запись для "Boxaround" дважды появляется в Test1.csv. Поэтому я ожидаю, что обе эти записи будут сопоставлены с записью "Boxaround" в Test2.csv и должны иметь одинаковый идентификатор кластера в выходных данных, однако идентификатор кластера 4 в выходных данных содержит две записи и еще одну с идентификатором кластера 0 для " Окно ". Я хочу, чтобы все три записи "Boxaround" имели одинаковый идентификатор кластера 4. Как я могу этого добиться? Пожалуйста помоги.