Предварительная обработка графиков в BigQuery (использование цикла for со структурой и типом словаря в BigQuery)
Обновлять
- Я нашел решение с использованием оператора цикла for в bigquery, но оно слишком медленное и слишком дорогое, когда существует много tag_id
- Это был бы только хороший способ использовать оператор соединения, а не использовать оператор цикла (все же я не нашел решения)
Столбец device_id имеет несколько tag_id (если tag_id такой же, app_id тоже.)
Столбец tag_id имеет несколько device_id .
Мне нужен список словарей (тип структуры в большом запросе) из этой примерной таблицы (например, словарь в python)
+-----------+--------+--------+
| device_id | tag_id | app_id |
+-----------+--------+--------+
| d1 | t1 | ai1 |
| d1 | t2 | ai2 |
| d3 | t3 | ai3 |
| d4 | t3 | ai3 |
| d5 | t2 | ai2 |
| d6 | t3 | ai3 |
+-----------+--------+--------+
- Я хочу создать сеть, используя приведенную выше таблицу
- [tag_id & tag_id] можно подключить только с помощью device_id
Правый вывод приведенной выше примерной таблицы:
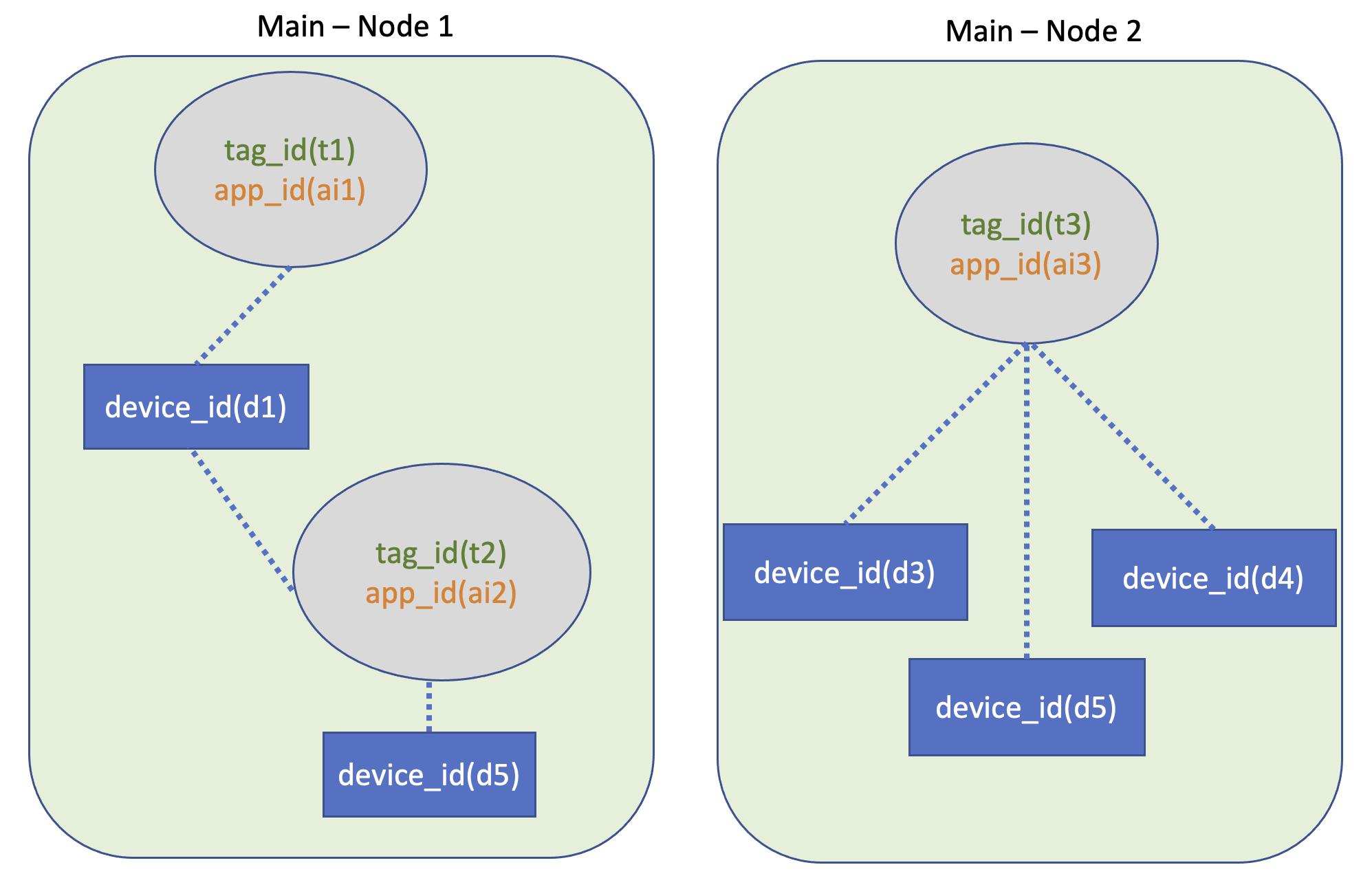
[{tag_id : [t1, t2], device_id : [d1, d5], app_id : [ai1, ai2]},
{tag_id : [t3], device_id : [d3, d4, d6], app_id : [ai3]}]
И структура
List(Dictionary(list of tag_id, list of device_id, list of app_id))
Мне нужно решение BigQuery, потому что приведенная выше примерная таблица очень большая. (Использование Spark или Python запрещено)
BigQuery UDF тоже в порядке (может ли кто-нибудь перевести это решение на javascript)
Мое решение в Python3.8 (вам не нужно этого делать. Просто ссылка.)
- Шаг 1. Составьте список словаря tag_id с уникальным списком device_id. (Я называю это «полуузел» )
def create_semi_node_list(raw_df):
unique_tag_id_lst = raw_df['tag_id'].to_list()
# create semi-node
semi_node = []
for tag_id in unique_tag_id_lst:
# make tag_id, device_id bucket
bucket = {}
bucket['tag_id'] = [tag_id]
bucket['device_id'] = df[df["tag_id"] == tag_id]["device_id"].to_list()
bucket['app_id'] = list(set(df[df["tag_id"] == tag_id]["app_id"].to_list()))
semi_node.append(bucket)
- Шаг 2. Сделайте результат (я называю это "главным узлом" ), используя цикл for
- Одно словарное значение списка зацикливается на другом словарном значении (его количество случаев равно квадрату длины df).
- Словари списка имеют уникальный tag_id (из-за вышеупомянутой функции) для каждого.
- Итак, если у них одинаковый device_id, он объединяется (и делает пустой словарь с зацикленным значением словаря)
def create_node_list(node_lst):
semi_node = copy.deepcopy(node_lst)
main_node_idx = 0
comp_node_idx = 0
result = []
while True:
key_length = len(semi_node)
if main_node_idx == comp_node_idx:
if main_node_idx+1 < key_length:
comp_node_idx += 1
else:
break
elif comp_node_idx+1 == key_length:
main_node_idx += 1
comp_node_idx = 0
elif (main_node_idx+1 < key_length) and (len(semi_node[main_node_idx]['tag_id']) == 0):
main_node_idx += 1
elif (comp_node_idx+1 < key_length) and (len(semi_node[comp_node_idx]['tag_id']) == 0):
comp_node_idx += 1
else:
# if have same device_id
var1 = len(semi_node[main_node_idx]['device_id'])
var2 = len(semi_node[comp_node_idx]['device_id'])
if var1 + var2 != len(set(semi_node[main_node_idx]['device_id'] + semi_node[comp_node_idx]['device_id'])):
# merge device_id bucket
result.extend(
[{
'tag_id' : list(set(semi_node[main_node_idx]['tag_id'] + semi_node[comp_node_idx]['tag_id'])),
'device_id' : list(set(semi_node[main_node_idx]['device_id'] + semi_node[comp_node_idx]['device_id'])),
'app_id' : list(set(semi_node[main_node_idx]['app_id'] + semi_node[comp_node_idx]['app_id'])),
'package_nm' : list(set(semi_node[main_node_idx]['package_nm'] + semi_node[comp_node_idx]['package_nm']))
}]
)
semi_node[comp_node_idx]['tag_id'] = []
- Шаг 3. Удалите словарь с пустым значением.
def pop_empty_node(node_list):
# node_list is main-node
try:
while True:
empty_node_idx=node_list.index({"tag_id":[], "device_id":[], "app_id":[], "package_nm":[]})
node_list.pop(empty_node_idx)
except:
return node_list