Как мы можем исключить ненужные строки из файла Excel при загрузке данных с помощью операции копирования в ADF
У меня есть полуструктурированный файл Excel. В таблице есть данные, но в некоторых строках есть разделители, которые следует игнорировать. Обработка данных должна начинаться с заголовков столбцов (Col1, col2 ....) и обрабатывать только строки с фактическими данными. Может ли кто-нибудь предложить способ добиться этого, используя копирование в adf.
Мой источник - файл xls, а цель - ADLA (файл Parquet)
Любая помощь приветствуется. Заранее спасибо.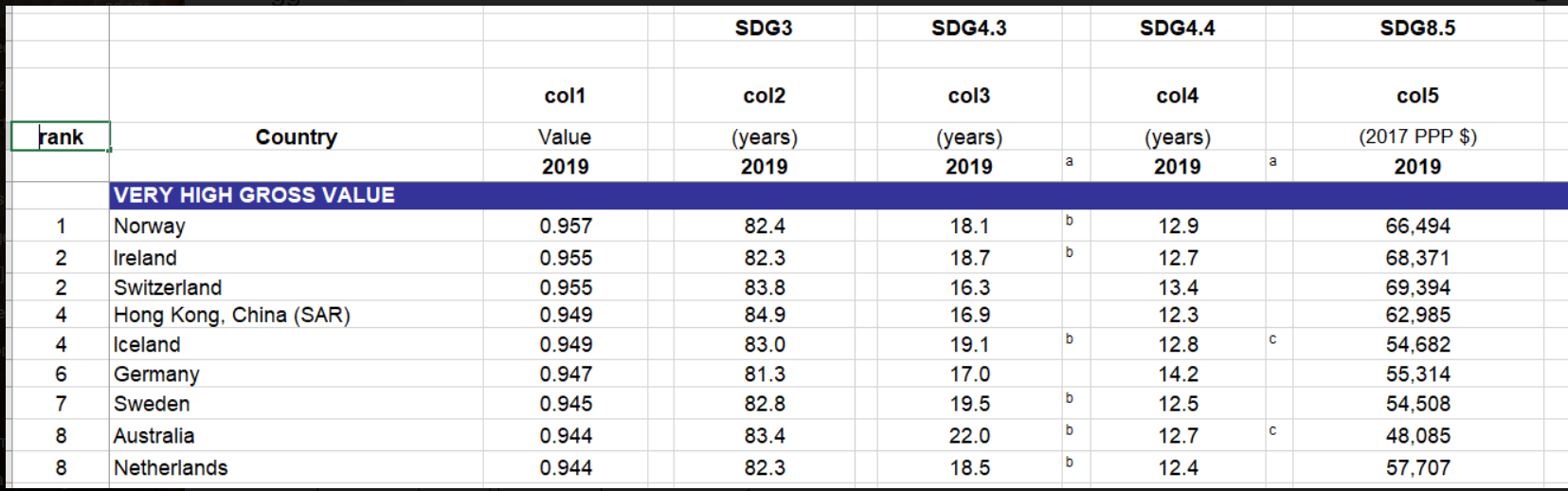
1 ответ
Наиболее близким решением является то, что вам нужно вручную выбрать диапазон данных в файле Excel: 
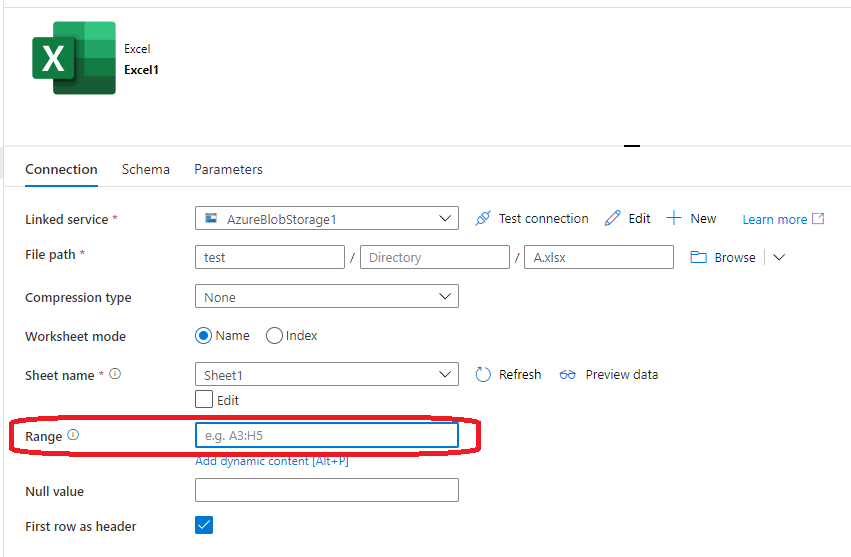
Ссылка: https://docs.microsoft.com/en-us/azure/data-factory/format-excel#dataset-properties
HTH.