Разница между spacy v3 конвейером en_core_web_trf и конвейером en_core_web_lg
Я провожу несколько тестов производительности с помощью spacy версии 3, чтобы правильно определить размер моих экземпляров в производственной среде. Я наблюдаю следующее
Наблюдение:
Почему нет значительной разницы между сценариями с NER и без NER в случае модели трансформатора? Является ли NER просто дополнительной задачей после тегирования POS в случае en_core_web_trf?
Тестовая среда: экземпляр GPU
Код теста:
import spacy
assert(spacy.__version__ == '3.0.3')
spacy.require_gpu()
texts = load_sample_texts() # loads 10,000 texts from a file
assert(len(texts) == 10000)
def get_execution_time(nlp, texts, N):
return timeit.timeit(stmt="[nlp(text) for text in texts]",
globals={'nlp': nlp, 'texts': texts}, number=N) / N
# load models
nlp_lg_pos = spacy.load('en_core_web_lg', disable=['ner', 'parser'])
nlp_lg_all = spacy.load('en_core_web_lg')
nlp_trf_pos = spacy.load('en_core_web_trf', disable=['ner', 'parser'])
nlp_trf_all = spacy.load('en_core_web_trf')
# get execution time
print(f'nlp_lg_pos = {get_execution_time(nlp_lg_pos, texts, N=1)}')
print(f'nlp_lg_all = {get_execution_time(nlp_lg_all, texts, N=1)}')
print(f'nlp_trf_pos = {get_execution_time(nlp_trf_pos, texts, N=1)}')
print(f'nlp_trf_all = {get_execution_time(nlp_trf_all, texts, N=1)}')
1 ответ
Не эксперт, но думаю, что это может быть связано с конструкцией трубопроводов.
Обученное проектирование трубопроводов
Документы для _sm/md/lgмодели утверждают:
Компонент независим и имеет собственный внутренний уровень tok2vec.
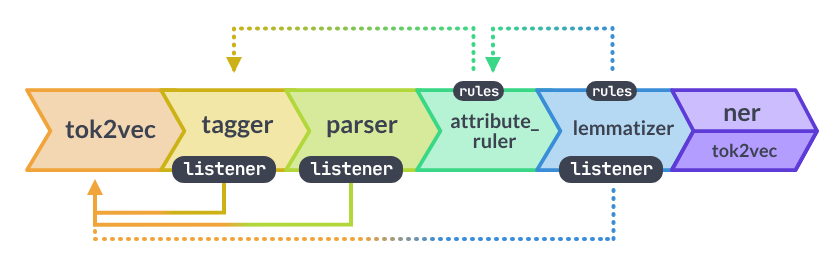
И в документации к модели указано:
В трансформаторе (
trf) модели,tagger,parserи (если присутствует) все слушают компонент.
Общие слои внедрения
Повторное использование слоя tok2vec между компонентами может значительно ускорить работу вашего конвейера и привести к значительному уменьшению размеров моделей. Однако это может сделать конвейер менее модульным и затруднить замену компонентов или переобучение частей конвейера.

Как видите, сделать компоненты независимыми, т.е. не делиться/прослушиватьtok2vec/transformerслоев, приводит к более медленному (но более модульному) конвейеру. Я считаю, что это причина того, чтоen_core_web_lgмодель заметно медленнее, когда вы добавляетеnerкомпонент, поскольку он по умолчанию независим.