Итерация значения RL, задача с несколькими действиями в gridworld
Я только начинаю изучать обучение с подкреплением и пытаюсь понять основы. Я понимаю алгоритмы оценки политики, итерации политики и значения и могу решить простую задачу оптимизации gridworld с двумя конечными состояниями -5 или +5. Вознаграждение за не оцениваемый шаг равно -1. Класс GridWorld, построенный с использованием некоторого кода шаблона с указанными выше состояниями терминала.
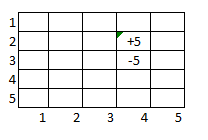
Теперь я пытаюсь понять, как я могу решить немного более сложный сценарий также с двумя конечными состояниями, одно из которых равно -5, а другое, когда все «точки» собраны:
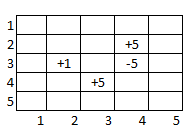
У меня есть очень четкое представление о том, что должно произойти, я просто изо всех сил пытаюсь реализовать это: когда мы проходим доску, если мы приземляемся на ячейку с точками «+», мы не хотим, чтобы агент продолжал идти. назад, поэтому мы устанавливаем эту награду на (-1). Проблема в том, что теперь свойство Маркова не будет выполнено, так как наши действия будут зависеть от того, были ли набраны очки. Я понимаю, что мне нужно обновить среду, чтобы отразить недавно добавленный «+», но как мне отразить набор точек? Мог бы я встроить его в окружающую среду? Если да, то будет ли это в части «переходы» класса GridWorld: (состояние, награда, is_terminal) - означает ли это, что мне понадобится несколько разных поисков «переходов» - 1 со всеми точками «+», один с 2 «+ "осталось очков, 1 из 1" + "точка и т. д.? Или алгоритм значения итераций? Я знаю, что могут быть другие алгоритмы, которые лучше подходят, но я еще не там ..
Было бы замечательно любое объяснение или соответствующий материал для чтения .. Я уже видел это: https://ai.stackexchange.com/questions/10732/how-do-i-apply-the-value-iteration-algorithm-when-there-are-two-goal-states / 10733 # 10733? newreg = a141ab7a8668426088d0d4b451628ced, но это точно не помогает части реализации.