Необработанная строка и регулярное выражение в Python
У меня есть некоторые заблуждения относительно необработанной строки в следующем коде:
import re
text2 = 'Today is 11/27/2012. PyCon starts 3/13/2013.'
text2_re = re.sub(r'(\d+)/(\d+)/(\d+)', r'\3-\1-\2', text2)
print (text2_re) #output: Today is 2012-11-27. PyCon starts 2013-3-13.
print (r'(\d+)/(\d+)/(\d+)') #output: (\d+)/(\d+)/(\d+)
Как я понимаю необработанную строку, без r, \ трактуется как escape-символ; с r обратная косая черта \ трактуется буквально как сама по себе.
Однако, что я не могу понять в приведенном выше коде, так это то, что: В строке 5 регулярного выражения, даже если есть r, внутренняя часть "\ d" обрабатывается как одно число [0-9] вместо одной обратной косой черты \ плюс один буква д.
Во второй строке печати 8 все символы обрабатываются как необработанные строки.
В чем разница?
Дополнительное издание:
Я сделал следующие четыре варианта, с или без r:
import re
text2 = 'Today is 11/27/2012. PyCon starts 3/13/2013.'
text2_re = re.sub(r'(\d+)/(\d+)/(\d+)', r'\3-\1-\2', text2)
text2_re1 = re.sub('(\d+)/(\d+)/(\d+)', r'\3-\1-\2', text2)
text2_re2 = re.sub(r'(\d+)/(\d+)/(\d+)', '\3-\1-\2', text2)
text2_re3 = re.sub('(\d+)/(\d+)/(\d+)', '\3-\1-\2', text2)
print (text2_re)
print (text2_re1)
print (text2_re2)
print (text2_re3)
И получите следующий вывод:
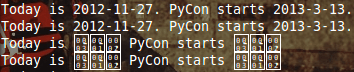
Не могли бы вы объяснить эти четыре ситуации конкретно?
4 ответа
Вы сбиты с толку разницей между строкой и строковым литералом.
Строковый литерал - это то, что вы помещаете между " или же ' и интерпретатор python анализирует эту строку и помещает ее в память. Если вы пометите свой строковый литерал как необработанный строковый литерал (используя r') тогда интерпретатор python не изменит представление этой строки перед тем, как поместить ее в память, но после того, как они были проанализированы, они сохраняются точно так же.
Это означает, что в памяти нет такой вещи как необработанная строка. Обе следующие строки хранятся в памяти одинаково без понятия, были ли они необработанными или нет.
r'a regex digit: \d' # a regex digit: \d
'a regex digit: \\d' # a regex digit: \d
Обе эти строки содержат \d и нечего сказать, что это произошло из необработанной строки. Поэтому, когда вы передаете эту строку re модуль видит, что есть \d и видит это как цифру, потому что re Модуль не знает, что строка взята из необработанного строкового литерала.
В вашем конкретном примере, чтобы получить буквальную обратную косую черту с последующим литералом d, вы бы использовали \\d вот так:
import re
text2 = 'Today is 11/27/2012. PyCon starts 3/13/2013.'
text2_re = re.sub(r'(\\d+)/(\\d+)/(\\d+)', r'\3-\1-\2', text2)
print (text2_re) #output: Today is 11/27/2012. PyCon starts 3/13/2013.
В качестве альтернативы, без использования необработанных строк:
import re
text = 'Today is 11/27/2012. PyCon starts 3/13/2013.'
text_re = re.sub('(\\d+)/(\\d+)/(\\d+)', '\\3-\\1-\\2', text2)
print (text_re) #output: Today is 2012-11-27. PyCon starts 2013-3-13.
text2 = 'Today is 11/27/2012. PyCon starts 3/13/2013.'
text2_re = re.sub('(\\\\d+)/(\\\\d+)/(\\\\d+)', '\\3-\\1-\\2', text2)
print (text2_re) #output: Today is 11/27/2012. PyCon starts 3/13/2013.
Надеюсь, это поможет.
Редактировать: я не хотел усложнять вещи, но потому что \d не является допустимой escape-последовательностью, Python не меняет ее, поэтому '\d' == r'\d' правда. поскольку \\ является допустимой escape-последовательностью, которая изменяется \так что вы получите поведение '\d' == '\\d' == r'\d', Строки иногда путают.
Edit2: чтобы ответить на ваши изменения, давайте рассмотрим каждую строку конкретно:
text2_re = re.sub(r'(\d+)/(\d+)/(\d+)', r'\3-\1-\2', text2)
re.sub получает две строки (\d+)/(\d+)/(\d+) а также \3-\1-\2, Надеюсь, это ведет себя так, как вы ожидаете сейчас.
text2_re1 = re.sub('(\d+)/(\d+)/(\d+)', r'\3-\1-\2', text2)
Опять (потому что \d не является допустимым экранированием строки, оно не изменяется, см. мое первое редактирование) re.sub получает две строки (\d+)/(\d+)/(\d+) а также \3-\1-\2, поскольку \d не изменяется интерпретатором Python r'(\d+)/(\d+)/(\d+)' == '(\d+)/(\d+)/(\d+)', Если вы понимаете мое первое редактирование, то, надеюсь, вы должны понять, почему эти два случая ведут себя одинаково.
text2_re2 = re.sub(r'(\d+)/(\d+)/(\d+)', '\3-\1-\2', text2)
Этот случай немного отличается, потому что \1, \2 а также \3 все допустимые escape-последовательности, они заменяются символом Unicode, десятичное представление которого задается числом. Это довольно сложно, но в основном сводится к:
\1 # stands for the ascii start-of-heading character
\2 # stands for the ascii start-of-text character
\3 # stands for the ascii end-of-text character
Это означает, что re.sub получает первую строку, как это было сделано в первых двух примерах ((\d+)/(\d+)/(\d+)) но вторая строка на самом деле <start-of-heading>/<start-of-text>/<end-of-text>, Так re.sub заменяет совпадение с этой второй строкой точно, но так как ни один из трех (\1, \2 или же \3) являются печатными символами. Python вместо этого просто печатает стандартный символ-заполнитель.
text2_re3 = re.sub('(\d+)/(\d+)/(\d+)', '\3-\1-\2', text2)
Это ведет себя как третий пример, потому что r'(\d+)/(\d+)/(\d+)' == '(\d+)/(\d+)/(\d+)', как объяснено во втором примере.
Есть различие, которое вы должны сделать между интерпретатором Python и re модуль.
В Python обратная косая черта, за которой следует символ, может означать специальный символ, если строка не является необработанной. Например, \n будет означать символ новой строки, \r будет означать возврат каретки, \t будет означать символ табуляции, \b представляет неразрушающий забой. Само по себе \d в строке python ничего особенного не значит.
В регулярном выражении, однако, есть группа символов, которые иначе не всегда что-то значат в python. Но в этом и заключается загвоздка "не всегда". Одна из вещей, которые могут быть неверно истолкованы \b который в python является backspace, в regex означает границу слова. Это подразумевает, что если вы передадите неопытный \b к регулярному выражению части регулярного выражения, это \b заменяется на backspace перед передачей в функцию регулярного выражения, и это ничего не значит. Таким образом, вы должны абсолютно передать b с его обратной косой чертой и для этого вы либо избегаете обратной косой черты, либо переписываете строку.
Вернуться к вашему вопросу о \d, \d не имеет никакого особого значения в Python, поэтому он остается нетронутым. Такой же \d переданное как регулярное выражение преобразуется механизмом регулярных выражений, который является отдельной сущностью для интерпретатора python.
По вопросу редактирования:
import re
text2 = 'Today is 11/27/2012. PyCon starts 3/13/2013.'
text2_re = re.sub(r'(\d+)/(\d+)/(\d+)', r'\3-\1-\2', text2)
text2_re1 = re.sub('(\d+)/(\d+)/(\d+)', r'\3-\1-\2', text2)
text2_re2 = re.sub(r'(\d+)/(\d+)/(\d+)', '\3-\1-\2', text2)
text2_re3 = re.sub('(\d+)/(\d+)/(\d+)', '\3-\1-\2', text2)
print(text2_re)
print(text2_re1)
print(text2_re2)
print(text2_re3)
Первые два должны быть простыми. re.sub делает свое дело, сопоставляя числа и косые черты и заменяя их в другом порядке дефисами. поскольку \d не имеет никакого особого значения в Python, \d перешел на re.sub является ли выражение необработанным или нет.
Третий и четвертый происходят потому, что вы не обработали строки для выражения замены. \1, \2 а также \3 имеют специальное значение в python, представляющее белое (или незаполненное) смайлик, черное (заполненное) смайлик и сердце соответственно (если символы не могут быть отображены, вы получаете эти "рамки для символов"). Таким образом, вместо замены захваченными группами, вы заменяете строки определенными символами.

Я чувствую, что вышеупомянутые ответы слишком усложняют это. Если вы бежите re.search()отправленная вами строка анализируется через два слоя:
Python интерпретирует \ символы, которые вы пишете через этот фильтр.
Затем регулярное выражение интерпретирует символы, которые вы пишете, через свой собственный фильтр.
Они происходят в таком порядке.
Синтаксис необработанной строки r"\nlolwtfbbq" когда вы хотите обойти интерпретатор Python, это не влияет re:
>>> print "\nlolwtfbbq"
lolwtfbbq
>>> print r"\nlolwtfbbq"
\nlolwtfbbq
>>>
Обратите внимание, что новая строка печатается в первом примере, но фактические символы \ а также n напечатаны во втором, потому что это сырье.
Любые строки, которые вы отправляете re пройти через интерпретатор регулярных выражений, чтобы ответить на ваш конкретный вопрос, \d означает "цифра 0-9" в регулярном выражении.
Не все \ вызовет проблемы. Питон имеет некоторые встроенные функции, такие как \b и т. д. Теперь, если r нет, питон рассмотрит \b как свой собственный, а не word boundary для регулярных выражений. Когда это используется с r режим тогда \b оставлено как есть. Это на языке неспециалистов. Не много в технических.\d это не специальный встроенный в Python, так что это будет безопасно даже без r Режим.
Здесь вы можете увидеть список. Это список, который Python понимает и будет интерпретировать. \b,\n и не \d,
Во-первых print \d интерпретация выполняется модулем регулярных выражений, а не python. Во втором print это делается Python. Как это в r режим его поставлю как есть.