Как показать происхождение данных в PowerBI с помощью Sankey
Я строил витрину данных. В рамках этого я отслеживал происхождение данных в паре таблиц Graph в SQL Server 2017 (один узел, один край). Я перенес их в PowerBI, используя следующий запрос:
SELECT
n.[table] AS [Source],
n1.[table] AS [Destination],
n.[table] + CHAR(10) + 'Description: ' + n.[description] + CHAR(10) + 'Load Type: ' + n.[loadType] + CHAR(10) + 'Loaded By: ' + n.[loadBy] AS [SourceDescrption],
n1.[table] + CHAR(10) + 'Description: ' + n1.[description] + CHAR(10) + 'Load Type: ' + n1.[loadType] + CHAR(10) + 'Loaded By: ' + n1.[loadBy] AS [SourceDescrption]
FROM
[audit].[tableMetaDataNode] n,
[audit].[tableMetaDataEdge] e,
[audit].[tableMetaDataNode] n1
WHERE
MATCH(n-(e)->n1)
Затем я визуализировал это с помощью диаграммы Санки следующим образом: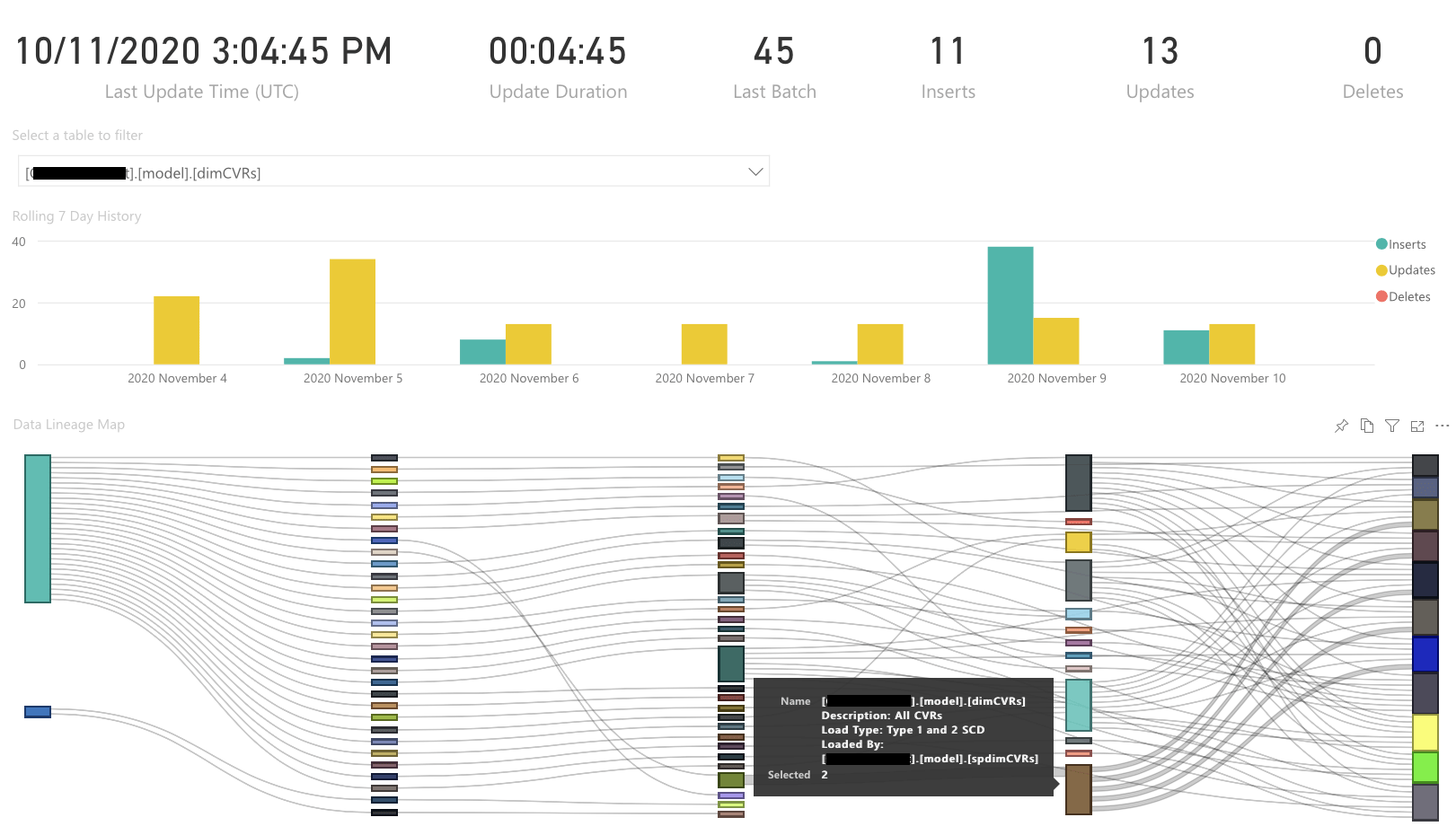
Вы можете видеть, что данные начинаются из двух систем (крайний слева) с соответствующими таблицами (второй столбец), в промежуточные таблицы в хранилище, затем в нечеткие таблицы и таблицы фактов.
Мне удалось выделить края выбранной таблицы жирным шрифтом, однако у меня есть несколько вопросов к сообществу Power BI:
- есть ли лучший способ отобразить это, чем Sankey, учитывая, что это, по сути, иерархия;
- есть ли диаграмма, которая позволила бы мне лучше выделить соответствующие строки (т.е. сделать их красными, а не жирными);
- есть ли способ показать полную родословную обратно к источнику, поскольку в настоящее время он показывает только один переход вперед или назад.
Приветствуются любые идеи.
Энди