Сортировать одну и ту же звезду в таблицах нескольких цифр Photutils DAOStarFinder
У меня есть серия
.fitДанные наблюдения телескопа CCD, я использую DAOStarFinder в фотоприемниках для фотометрии. Я хочу узнать данные об одних и тех же звездах и построить их кривые блеска. Таблица звезд, полученная из одного рисунка, выглядит так:
id xcentroid ycentroid sharpness roundness1 roundness2 npix sky peak flux mag JD-HELIO
1 7.2507764 7.1405824 0.25877792 -0.27655266 -0.014479976 361 0 422 12.624582 -2.7530425 2458718.4
2 2740.913 7.1539345 0.30025149 0.25451119 0.018093909 361 0 458 13.467545 -2.8232211 2458718.4
3 2515.323 43.807826 0.44318308 -0.69941143 0.2041087 361 0 626 5.5224866 -1.8553367 2458718.4
4 1284.7828 53.552295 0.980886 -0.1667419 -0.59773071 361 0 480 1.0122505 -0.013219984 2458718.4
5 1249.1764 149.95127 0.49822284 0.27794038 0.72191121 361 0 463 1.0285458 -0.030559111 2458718.4
6 2376.8957 202.02747 0.82856798 -0.42128731 0.30015708 361 0 653 4.7224348 -1.6854149 2458718.4
7 59.982356 215.6136 0.54354939 -0.65521898 -0.00056722803 361 0 497 1.6563912 -0.5479073 2458718.4
8 1661.3238 220.14951 0.42552567 -0.6035932 -0.089775238 361 0 686 7.9859189 -2.2558122 2458718.4
9 1601.4266 229.47563 0.34847327 -0.60959051 0.10700081 361 0 2380 68.697859 -4.592358 2458718.4
10 2559.8217 236.60404 0.2231161 -0.013164036 0.54360116 361 0 490 2.1546284 -0.83343095 2458718.4
... ... ... ... ... ... ... ... ...
Length = 104 rows
Таблица второго рисунка выглядит так:
id xcentroid ycentroid sharpness roundness1 roundness2 npix sky peak flux mag JD-HELIO
1 7.157499 7.0229365 0.29484857 -0.25416309 -0.018748812 361 0 458 12.940807 -2.7799034 2458718.4
2 2740.8166 7.2593662 0.27311183 0.24388127 0.029043824 361 0 448 12.755378 -2.7642333 2458718.4
3 2495.8085 45.142195 0.64182883 -0.48598172 0.70072363 361 0 649 4.7000496 -1.6802561 2458718.4
4 2679.6403 62.327031 0.80391292 -0.62284532 0.13309338 361 0 524 1.6688956 -0.55607294 2458718.4
5 2467.7183 101.15541 0.64006186 -0.14660082 -0.6205186 361 0 500 1.465029 -0.41461552 2458718.4
6 1094.7268 107.11982 0.59849809 -0.62182068 0.27247315 361 0 476 1.051774 -0.054806086 2458718.4
7 28.506992 145.07421 0.64028434 0.2210654 0.012627233 361 0 474 1.0149705 -0.016133536 2458718.4
8 1876.9044 186.59285 0.82846693 -0.37091888 0.14646202 361 0 515 1.3318741 -0.31115797 2458718.4
9 2358.642 202.09716 0.51573138 -0.31333346 0.88458938 361 0 588 3.6688261 -1.4113178 2458718.4
10 1641.9716 221.59273 0.62435574 -0.56225884 0.25546345 361 0 715 6.4287534 -2.0203169 2458718.4
... ... ... ... ... ... ... ... ...
Length = 84 rows
Я проделал то же самое с несколькими фигурами, вот что интересно, так как
xcentroid и
ycentroid одних и тех же звезд имеют некоторые смещения, как я могу определить одну и ту же звезду на разных рисунках?
Найденные решения
Я столкнулся с той же проблемой и нашел решение, сравнивая цифры наблюдений ПЗС-звезд, основная идея состоит в том, чтобы найти наилучшее совпадение треугольников двух наборов точек.
Затем я использую astroalignпакет для вычисления матрицы преобразования и выравнивания по всем точкам. Слава богу, неплохо работает.
import itertools
import numpy as np
import matplotlib.pyplot as plt
import astroalign as aa
def getTriangles(set_X, X_combs):
"""
Inefficient way of obtaining the lengths of each triangle's side.
Normalized so that the minimum length is 1.
"""
triang = []
for p0, p1, p2 in X_combs:
d1 = np.sqrt((set_X[p0][0] - set_X[p1][0]) ** 2 +
(set_X[p0][1] - set_X[p1][1]) ** 2)
d2 = np.sqrt((set_X[p0][0] - set_X[p2][0]) ** 2 +
(set_X[p0][1] - set_X[p2][1]) ** 2)
d3 = np.sqrt((set_X[p1][0] - set_X[p2][0]) ** 2 +
(set_X[p1][1] - set_X[p2][1]) ** 2)
d_min = min(d1, d2, d3)
d_unsort = [d1 / d_min, d2 / d_min, d3 / d_min]
triang.append(sorted(d_unsort))
return triang
def sumTriangles(ref_triang, in_triang):
"""
For each normalized triangle in ref, compare with each normalized triangle
in B. find the differences between their sides, sum their absolute values,
and select the two triangles with the smallest sum of absolute differences.
"""
tr_sum, tr_idx = [], []
for i, ref_tr in enumerate(ref_triang):
for j, in_tr in enumerate(in_triang):
# Absolute value of lengths differences.
tr_diff = abs(np.array(ref_tr) - np.array(in_tr))
# Sum the differences
tr_sum.append(sum(tr_diff))
tr_idx.append([i, j])
# Index of the triangles in ref and in with the smallest sum of absolute
# length differences.
tr_idx_min = tr_idx[tr_sum.index(min(tr_sum))]
ref_idx, in_idx = tr_idx_min[0], tr_idx_min[1]
print("Smallest difference: {}".format(min(tr_sum)))
return ref_idx, in_idx
set_ref = np.array([[2511.268821,44.864124],
[2374.085032,201.922566],
[1619.282942,216.089335],
[1655.866502,221.127787],
[ 804.171659,2133.549517], ])
set_in = np.array([[1992.438563,63.727282],
[2285.793346,255.402548],
[1568.915358, 279.144544],
[1509.720134, 289.434629],
[1914.255205, 349.477788],
[2370.786382, 496.026836],
[ 482.702882, 508.685952],
[2089.691026, 523.18825 ],
[ 216.827439, 561.807396],
[ 614.874621, 2007.304727],
[1286.639124, 2155.264827],
[ 729.566116, 2190.982364]])
# All possible triangles.
ref_combs = list(itertools.combinations(range(len(set_ref)), 3))
in_combs = list(itertools.combinations(range(len(set_in)), 3))
# Obtain normalized triangles.
ref_triang, in_triang = getTriangles(set_ref, ref_combs), getTriangles(set_in, in_combs)
# Index of the ref and in triangles with the smallest difference.
ref_idx, in_idx = sumTriangles(ref_triang, in_triang)
# Indexes of points in ref and in of the best match triangles.
ref_idx_pts, in_idx_pts = ref_combs[ref_idx], in_combs[in_idx]
print ('triangle ref %s matches triangle in %s' % (ref_idx_pts, in_idx_pts))
print ("ref:", [set_ref[_] for _ in ref_idx_pts])
print ("input:", [set_in[_] for _ in in_idx_pts])
ref_pts = np.array([set_ref[_] for _ in ref_idx_pts])
in_pts = np.array([set_in[_] for _ in in_idx_pts])
transf, (in_list,ref_list) = aa.find_transform(in_pts, ref_pts)
transf_in = transf(set_in)
print(f'transformation matrix: {transf}')
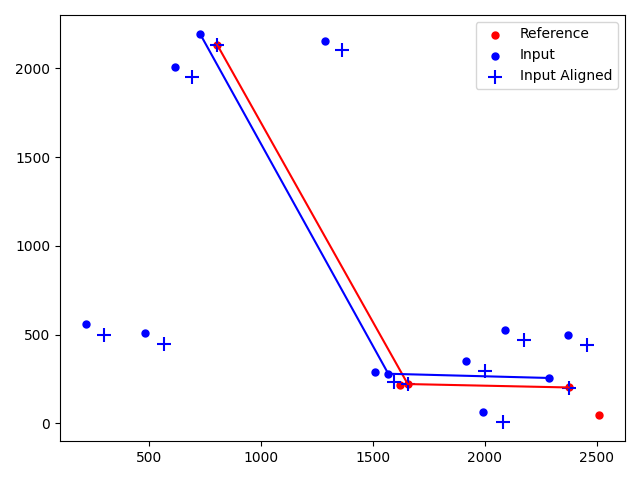
plt.scatter(set_ref[:,0],set_ref[:,1], s=100,marker='.', c='r',label='Reference')
plt.scatter(set_in[:,0],set_in[:,1], s=100,marker='.', c='b',label='Input')
plt.scatter(transf_in[:,0],transf_in[:,1], s=100,marker='+', c='b',label='Input Aligned')
plt.plot(ref_pts[:,0],ref_pts[:,1], c='r')
plt.plot(in_pts[:,0],in_pts[:,1], c='b')
plt.legend()
plt.tight_layout()
plt.savefig( 'align_coordinates.png', format = 'png')
plt.show()
1 ответ
В настоящее время я использую простой способ справиться с этим: если координата находится в допустимом диапазоне, добавьте ее.
if (xcentroid-offset < x < xcentroid +offset) and (ycentroid-offset < y < ycentroid+offset):
onestar.append(data[j,:])
Практически весь сценарий выглядит так:
#===================================================================
#
# STARS SORTING
#
# This script is used to sorting stars from the table file of each figure.
#
# WARNING:
#
# VERSION: 24 Sep 2020
# AUTHOER: QIANG CHEN chen@camk.edu.pl
#
# PYTHON ENVIRONMENT REQUIREMENT:
# - pip install astropy
# - pip install --no-deps ccdproc
# - pip install photutils
# alternatively can use (CAMK):
# source /home/chen/python-chen/chen3.6/bin/activate
#
# REFERENCE:
# - COMPARISION STARS https://nbviewer.jupyter.org/gist/dokeeffe/416e214f134d39db696c7fdac261964b
#===================================================================
import os
import glob
import numpy as np
PATH = '/work/chuck/chen/obs'
folder = '20190822/reduced'
name = 'ap'
name = 'stars'
offset = 50
filters = ['V','U','B','I']
#filters = ['U']
for filt in filters:
print('SORTING STARS BY EVERY FILTER TYPE:',filt)
files = glob.glob(f'{PATH}/{folder}/{name}_light_*{filt}*.dat')
print(' reading data, setting the most stars file as a reference frame')
line_ref = 0
datas = []
data_ref = np.array([])
for fil in files:
f = open(fil,'r')
next(f) # skip header line
data = np.array([[float(data) for data in line.split()] for line in f.readlines()])
f.close()
datas.append(data)
row,col = data.shape
if (row >= line_ref):
line_ref = row
data_ref = data
if (data_ref.size):
pass
else:
print(' NO RESULTS')
continue
print(' pick up each star in the reference frame, compare x y within all the files')
ii = 0
for i in range(row):
onestar = []
print(' row',i+1,'/',row)
xcentroid = data_ref[i,1]
ycentroid = data_ref[i,2]
for data in datas:
row,col = data.shape
for j in range(row):
x = data[j,1]
y = data[j,2]
if (xcentroid-offset < x < xcentroid +offset) and (ycentroid-offset < y < ycentroid+offset):
onestar.append(data[j,:])
if(len(onestar)<10):
continue
else:
ii+=1
onestar = np.array(onestar)
onestar = onestar[onestar[:,-1].argsort()]
np.savetxt(f'{PATH}/{folder}/sorted_{name}_{filt}{ii}.dat', onestar, fmt='%f ', newline='\n')