Нейронная сеть всегда предсказывает один и тот же класс
Я пытаюсь реализовать нейронную сеть, которая классифицирует изображения в одну из двух отдельных категорий. Проблема, однако, в том, что в настоящее время он всегда предсказывает 0 для любого ввода, и я не совсем уверен, почему.
Вот мой метод извлечения функций:
def extract(file):
# Resize and subtract mean pixel
img = cv2.resize(cv2.imread(file), (224, 224)).astype(np.float32)
img[:, :, 0] -= 103.939
img[:, :, 1] -= 116.779
img[:, :, 2] -= 123.68
# Normalize features
img = (img.flatten() - np.mean(img)) / np.std(img)
return np.array([img])
Вот моя процедура градиентного спуска:
def fit(x, y, t1, t2):
"""Training routine"""
ils = x.shape[1] if len(x.shape) > 1 else 1
labels = len(set(y))
if t1 is None or t2 is None:
t1 = randweights(ils, 10)
t2 = randweights(10, labels)
params = np.concatenate([t1.reshape(-1), t2.reshape(-1)])
res = grad(params, ils, 10, labels, x, y)
params -= 0.1 * res
return unpack(params, ils, 10, labels)
Вот мое прямое и обратное (градиентное) распространение:
def forward(x, theta1, theta2):
"""Forward propagation"""
m = x.shape[0]
# Forward prop
a1 = np.vstack((np.ones([1, m]), x.T))
z2 = np.dot(theta1, a1)
a2 = np.vstack((np.ones([1, m]), sigmoid(z2)))
a3 = sigmoid(np.dot(theta2, a2))
return (a1, a2, a3, z2, m)
def grad(params, ils, hls, labels, x, Y, lmbda=0.01):
"""Compute gradient for hypothesis Theta"""
theta1, theta2 = unpack(params, ils, hls, labels)
a1, a2, a3, z2, m = forward(x, theta1, theta2)
d3 = a3 - Y.T
print('Current error: {}'.format(np.mean(np.abs(d3))))
d2 = np.dot(theta2.T, d3) * (np.vstack([np.ones([1, m]), sigmoid_prime(z2)]))
d3 = d3.T
d2 = d2[1:, :].T
t1_grad = np.dot(d2.T, a1.T)
t2_grad = np.dot(d3.T, a2.T)
theta1[0] = np.zeros([1, theta1.shape[1]])
theta2[0] = np.zeros([1, theta2.shape[1]])
t1_grad = t1_grad + (lmbda / m) * theta1
t2_grad = t2_grad + (lmbda / m) * theta2
return np.concatenate([t1_grad.reshape(-1), t2_grad.reshape(-1)])
А вот моя функция прогнозирования:
def predict(theta1, theta2, x):
"""Predict output using learned weights"""
m = x.shape[0]
h1 = sigmoid(np.hstack((np.ones([m, 1]), x)).dot(theta1.T))
h2 = sigmoid(np.hstack((np.ones([m, 1]), h1)).dot(theta2.T))
return h2.argmax(axis=1)
Я вижу, что частота ошибок постепенно уменьшается с каждой итерацией, обычно сходясь где-то в районе 1.26e-05.
Что я пробовал до сих пор:
- PCA
- Различные наборы данных (радужная оболочка от sklearn и рукописные числа из курса Coursera ML, с точностью до 95% на обоих). Тем не менее, оба из них были обработаны в пакете, поэтому я могу предположить, что моя общая реализация верна, но что-то не так с тем, как я извлекаю функции, или как я обучаю классификатор.
- Попробовал SGDClassifier от sklearn, и он не работал намного лучше, давая мне точность ~50%. Так что-то не так с функциями, тогда?
Изменить: средний выходной h2 выглядит следующим образом:
[0.5004899 0.45264441]
[0.50048522 0.47439413]
[0.50049019 0.46557124]
[0.50049261 0.45297816]
Итак, очень похожие сигмоидные выходы для всех примеров валидации.
10 ответов
После полутора недель исследований, я думаю, я понимаю, в чем проблема. В самом коде нет ничего плохого. Единственные две проблемы, которые мешают моей реализации успешно классифицировать это время, потраченное на обучение, и правильный выбор скорости обучения / параметров регуляризации.
У меня уже есть учебная программа для некоторого тома, и она уже дает 75% -ную точность, хотя еще есть много возможностей для совершенствования.
Моя сеть всегда предсказывает один и тот же класс. В чем проблема?
У меня было это пару раз. Хотя в настоящее время я слишком ленив, чтобы просмотреть ваш код, я думаю, что могу дать некоторые общие советы, которые могут также помочь другим, у которых есть тот же симптом, но, возможно, другие проблемы, лежащие в основе.
Отладка нейронных сетей
Подгонка наборов данных одного предмета
Для каждого класса, в котором должна быть возможность предсказывать сеть, попробуйте следующее:
- Создайте набор данных только из одной точки данных класса i.
- Подгоните сеть к этому набору данных.
- Научится ли сеть предсказывать "класс i"?
Если это не работает, есть четыре возможных источника ошибок:
- Алгоритм обучения багги: попробуйте меньшую модель, напечатайте множество значений, которые рассчитываются между ними, и посмотрите, соответствуют ли они вашим ожиданиям.
- Деление на 0: добавить небольшое число к знаменателю
- Логарифм 0 / отрицательное число: как деление на 0
- Данные. Возможно, ваши данные имеют неправильный тип. Например, может потребоваться, чтобы ваши данные имели тип
float32но на самом деле это целое число. - Модель. Также возможно, что вы только что создали модель, которая не может предсказать, что вы хотите. Это должно быть выявлено, когда вы попробуете более простые модели.
- Инициализация / оптимизация: в зависимости от модели ваша инициализация и алгоритм оптимизации могут играть решающую роль. Я бы сказал, что для начинающих, использующих стандартный стохастический градиентный спуск, в основном важно случайным образом инициализировать веса (у каждого веса свое значение). - см. также: этот вопрос / ответ
Кривая обучения
Смотрите sklearn для деталей.
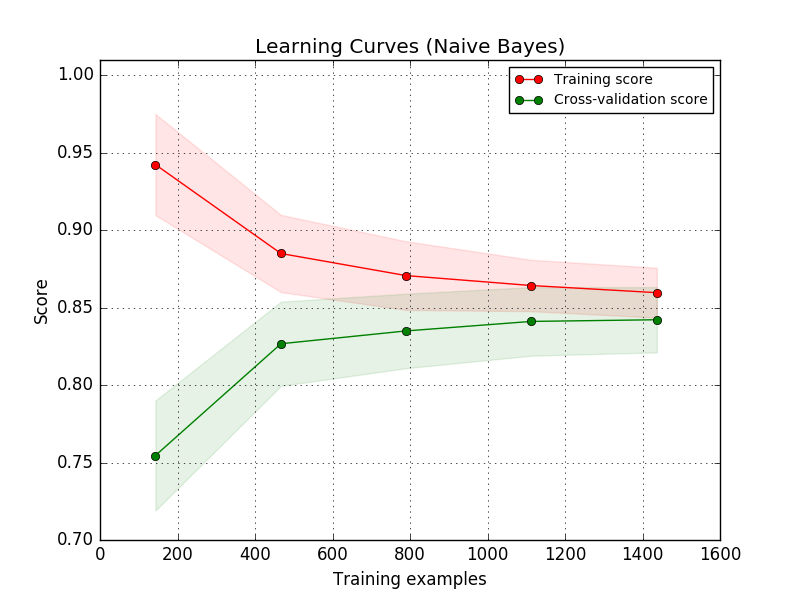
Идея состоит в том, чтобы начать с крошечного учебного набора данных (вероятно, только одного элемента). Тогда модель должна быть в состоянии соответствовать данным идеально. Если это работает, вы делаете немного больший набор данных. Ваша ошибка тренировки должна немного увеличиться в какой-то момент. Это показывает способность ваших моделей моделировать данные.
Анализ данных
Проверьте, как часто появляются другие классы. Если один класс доминирует над другими (например, один класс составляет 99,9% данных), это проблема. Ищите методы "обнаружения выбросов".
Больше
- Скорость обучения: если ваша сеть не улучшается и становится чуть лучше случайного, попробуйте уменьшить скорость обучения. Для компьютерного зрения, скорость обучения
0.001часто используется / работает. Это также актуально, если вы используете Адама в качестве оптимизатора. - Предварительная обработка: убедитесь, что вы используете одну и ту же предварительную обработку для обучения и тестирования. Вы можете увидеть различия в путанице (см. Этот вопрос)
Распространенные ошибки
Это вдохновлено Reddit:
- Вы забыли применить предварительную обработку
- Умирающий ReLU
- Слишком маленькая / слишком большая скорость обучения
- Неправильная функция активации в последнем слое:
- Ваши цели не в сумме один? -> Не используйте softmax
- Отдельные элементы ваших целей отрицательны -> Не используйте Softmax, ReLU, Sigmoid. tanh может быть вариантом
- Слишком глубокая сеть: вы не можете тренироваться. Попробуйте сначала более простую нейронную сеть.
То же случилось и со мной. У меня был несбалансированный набор данных (примерно 66%-33% распределения выборки между классами 0 и 1 соответственно), и сеть всегда выводила0.0 для всех образцов после первой итерации.
Моя проблема заключалась в слишком высокой скорости обучения. Переключение на1e-05 решил вопрос.
В более общем плане я предлагаю распечатать перед обновлением параметров:
- ваш чистый выпуск (за одну партию)
- соответствующая этикетка (для той же партии)
- величина потерь (для одной и той же партии) либо по выборке, либо в совокупности.
А затем проверьте те же три пункта после обновления параметра. В следующей партии вы должны увидеть постепенное изменение чистого выпуска. Когда моя скорость обучения была слишком высокой, уже на второй итерации чистый результат достигал всех1.0s или все 0.0s для всех образцов в партии.
То же случилось и со мной. Мой был вdeeplearning4j JAVAбиблиотека для классификации изображений, которая давала окончательный результат последней обучающей папки для каждого теста. Я смог решить эту проблему, снизив скорость обучения.
Подходы могут быть использованы:
- Снижение скорости обучения. (Первая мина была 0,01 - понижение до 1e-4 и все заработало)
- Увеличение размера пакета (иногда стохастический градиентный спуск не работает, тогда вы можете попробовать увеличить размер пакета (32,64,128,256,..)
- Перемешивание обучающих данных
То же самое случилось со мной. Модель предсказывала один класс только для семи классов CNN. Я пытался изменить функцию активации, размер пакета, но ничего не помогло. Затем изменение скорости обучения сработало и для меня.
opt = keras.optimizers.Adam(learning_rate=1e-06)
Как видите, мне пришлось выбрать очень низкую скорость обучения. Мое количество обучающих выборок — 5250, а проверочных — 1575.
Я столкнулся с проблемой, что модель всегда предсказывает одну и ту же метку. Это сбивало меня с толку на неделю. Наконец, я решил ее, заменив RELU другой функцией активации. RELU вызовет проблему "Dying ReLU".
Прежде чем я решил проблему, я пробовал:
- проверьте частоту положительных и отрицательных отсчетов от 1:25 до 1:3. Но не работает
- изменить размер пакета и скорость обучения и другие потери, но это не работает
Наконец, я обнаружил, что уменьшение скорости обучения от 0,005 до 0,0002 уже допустимо.
Попробовав множество решений, выяснилось, что проблема для меня была связана с фазой прогнозирования, а не с архитектурой обучения или модели. Метод, который я использовал для прогнозирования, показывал нули во всех случаях, хотя у меня относительно высокая точность проверки, потому что эта строка:
predicted_class_indices=np.argmax(scores,axis=1)
Если вы имеете дело с бинарной классификацией, попробуйте:
predict = model.predict(
validation_generator, steps=None, callbacks=None, max_queue_size=10, workers=1,
use_multiprocessing=False, verbose=0
)
У меня тоже была такая же проблема, я делаю двоичную классификацию с использованием трансферного обучения с ResNet50, я смог решить ее, заменив:
Dense(output_dim=2048, activation= 'relu')
с участием
Dense(output_dim=128, activation= 'relu')
а также путем удаления Keras Augmentation и переобучения последних слоев RestNet50
Просто если кто-нибудь еще столкнется с этой проблемой. Мой был с deeplearning4j Архитектура Lenet(CNN). Она давала окончательный вывод последней обучающей папки для каждого теста. Я смог решить это increasing my batchsize а также shuffling the training data поэтому каждая партия содержала как минимум образец из нескольких папок. Мой класс данных имел размер пакета 1, который был действительно dangerous,
Редактировать: Хотя еще одна вещь, которую я наблюдал в последнее время, это иметь ограниченные наборы тренировочных образцов на класс, несмотря на большой dataset, например, обучение neural-network узнавать human faces но иметь только максимум скажем 2 разных лиц на 1 person значит, в то время как набор данных состоит из, скажем, 10000 persons таким образом dataset из 20000 faces в целом. Лучше dataset будет 1000 разных faces за 10 000 persons таким образом dataset из 10 000 000 faces в целом. Это относительно необходимо, если вы хотите избежать перенастройки данных в один класс, чтобы ваш network может легко обобщать и производить более предсказуемые.
Ответ TOPUP действительно работает для меня. Мое обстоятельство состоит в том, что пока я обучаю модель bert4reco с большим набором данных ( 4 миллиона + выборок), acc и log_loss всегда остаются между 0,5 и 0,8 в течение всей эпохи (это стоит 8 часов, я печатаю результат каждые 100 шагов). Затем я использую очень мелкий набор данных и меньшую модель, наконец, это работает! модель начинает что-то узнавать, acc и log_loss начинают увеличиваться и достигают конвергенции через 300 эпох!
В конце концов, ответ TOPUP - хороший контрольный список для таких вопросов. А иногда, если вы не видите никаких изменений в начале поезда, возможно, вашей модели потребуется много времени, чтобы действительно чему-то научиться. Было бы лучше, если бы пользователь мини-набор данных подтвердил это, и после этого вы можете подождать, пока он изучит или использует какое-либо эффективное оборудование, такое как графические процессоры или TPU.