Разделитель Hadoop
Я хочу спросить о разделителе Hadoop, реализован ли он в Mappers? Как измерить производительность при использовании стандартного хеш-разделителя - Есть ли лучший разделитель для уменьшения перекоса данных?
Спасибо
2 ответа
Partitioner не находится в Mapper.
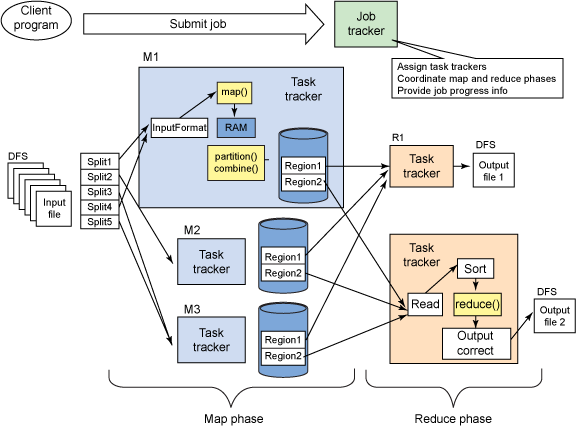
Ниже описан процесс, который происходит в каждом Mapper -
- Каждая задача карты записывает свой вывод в кольцевую буферную память (а не на диск). Когда буфер достигает порогового значения, фоновый поток начинает проливать содержимое на диск. [Размер буфера регулируется свойством mapreduce.task.io.sort.mb и по умолчанию составляет 100 МБ, а разлив регулируется свойством mapreduce.io.sort.spill.percent и по умолчанию составляет 0,08 или 80%]. Перед разливом на диск данные разбиты на разделы в соответствии с редукторами, которые они будут отправлены Выполнить сортировку в памяти по ключам в каждом разделе
- Запустите функцию объединителя для результатов каждого сорта (чтобы меньше данных можно было записывать и передавать, это необходимо сделать специально)
- Сжатие (необязательно) [mapred.compress.map.output=true; mapred.map.output.compression.codec=CodecName]
- Записывает на диск и разделы выходного файла становятся доступными для редукторов по HTTP.
Ниже приведен процесс, который происходит в каждом редукторе
Теперь каждый Редуктор собирает все файлы из каждого преобразователя, он переходит в фазу сортировки / слияния (сортировка уже выполнена на стороне преобразователя), которая объединяет все выходные данные карты с сохранением порядка сортировки.
Во время фазы уменьшения функция вызова вызывается для каждой клавиши в отсортированном выводе.
Ниже приведен код, иллюстрирующий фактический процесс разделения ключей. getpartition() вернет номер раздела / редуктор, на который должен быть отправлен конкретный ключ, на основе его хеш-кода. Хэш-код должен быть уникальным для каждого ключа, и по всему ландшафту Хэш-код должен быть уникальным и одинаковым для ключа. Для этой цели hadoop реализует свой собственный хэш-код для своего ключа вместо использования хеш-кода по умолчанию в java.
Partition keys by their hashCode().
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
Partitioner является ключевым компонентом между Mappers и Reducers. Распределяет испускаемые данные карт по редукторам.
Partitioner работает в каждой JVM Map Task (процесс Java).
Разделитель по умолчанию HashPartitioner работает на основе хэш-функции, и это очень быстро по сравнению с другими разделителями, как TotalOrderPartitioner, Он запускает хеш-функцию для каждого ключа вывода карты, т.е.
Reduce_Number = (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
Чтобы проверить производительность Hash Partitioner, используйте счетчики задач Reduce и посмотрите, как произошло распределение среди редукторов.
Hash Partitioner является базовым разделителем и не подходит для обработки данных с высокой асимметрией.
Для решения проблем перекоса данных нам нужно написать собственный класс разделителя, расширяющий Partitioner.java класс из MapReduce API.
Пример для пользовательского разделителя похож на RandomPartitioner, Это один из лучших способов равномерного распределения искаженных данных между редукторами.