ВниманиеQKV от Trax
Уровень AttentionQKV, реализованный Trax, выглядит следующим образом: AttentionQKV
def AttentionQKV(d_feature, n_heads=1, dropout=0.0, mode='train'):
"""Returns a layer that maps (q, k, v, mask) to (activations, mask).
See `Attention` above for further context/details.
Args:
d_feature: Depth/dimensionality of feature embedding.
n_heads: Number of attention heads.
dropout: Probababilistic rate for internal dropout applied to attention
activations (based on query-key pairs) before dotting them with values.
mode: One of `'train'`, `'eval'`, or `'predict'`.
"""
return cb.Serial(
cb.Parallel(
core.Dense(d_feature),
core.Dense(d_feature),
core.Dense(d_feature),
),
PureAttention( # pylint: disable=no-value-for-parameter
n_heads=n_heads, dropout=dropout, mode=mode),
core.Dense(d_feature),
)
В частности, какова цель трех параллельных плотных слоев? Вход в этот слой - q, k, v, маска. Почему q, k, v проходят через плотный слой?
1 ответ
Решение
Этот фрагмент кода является реализацией уравнения в верхней части страницы 5 документа " Внимание" - это все, что вам нужно в статье, в которой представлены модели Transformer в 2017 году. Вычисления показаны на рисунке 2 документа:
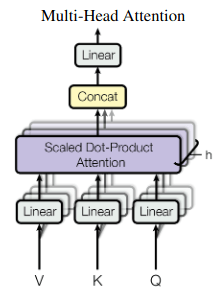
Скрытые состояния проецируются в h головы внимания, которые параллельно делают масштабируемое скалярное произведение. Проекцию можно интерпретировать как извлечение информации, актуальной для головы. Затем каждая головка выполняет вероятностный поиск на основе различных (изученных) критериев.