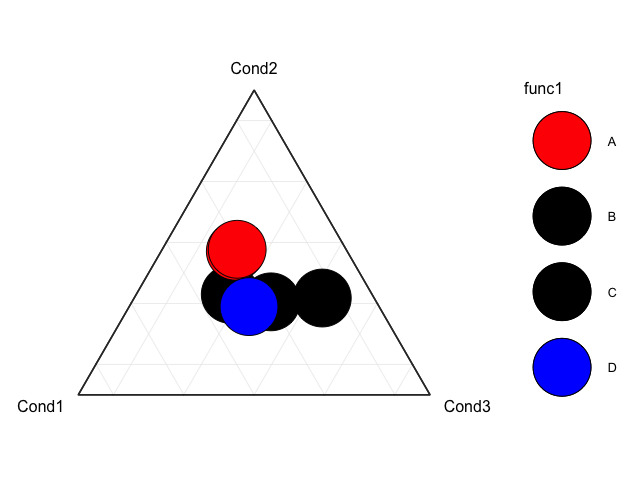
Что делает точечный график поверх другого на geom_point? А как это поменять?
Что заставляет график точек значений накладываться друг на друга и наносить поверх другого графика ggtern? А как его поменять? Я бы хотел, чтобы мои выбранные цветные наблюдения были нанесены поверх черных. (По моим данным, у меня есть 1400 наблюдений, и даже с меньшим размером точки это все равно происходит)
obs <- c("Gene1", "Gene2", "Gene3", "Gene4","Gene5", "Gene6")
func1 <- c("A", "B", "C", "D", "C", "A")
func2 <- c("A1", "B1", "C1", "D1", "C2", "A2")
Cond1 <- c(0.007623561, 0.004639893, 0.000994121, 0.017494429, 0.000366445, 0.006663334)
Cond2 <- c(0.011299941, 0.009994388, 0.001012428, 0.013695669, 0.000299771, 0.010287904)
Cond3 <- c(0.005055458, 0.016826251, 0.001311254, 0.016115009, 0.000242897, 0.004583889)
df <- data.frame(obs, func1, func2, Cond1, Cond2, Cond3)
col<-rep("black", length(unique(df$func1)))
names(col) <- unique(df$func1)
col[which(names(col)=="A")] <- 'red'
col[which(names(col)=="D")] <- 'blue'
library(ggtern)
g <- ggtern(data=df, aes(x=Cond1,y=Cond2,z=Cond3)) +
theme_bw() +
geom_point(aes(fill=func1), shape=21, size = 20, colour="black") +
scale_fill_manual(values=col) +
labs(x="Cond1",y="Cond2",z="Cond3") +
scale_T_continuous(breaks=unique(df$x))+
scale_L_continuous(breaks=unique(df$y))+
scale_R_continuous(breaks=unique(df$z))
print(g)
В настоящее время: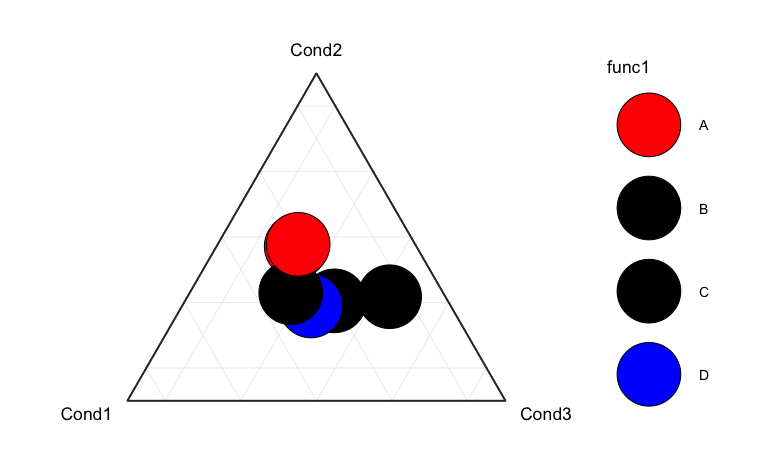
Я пробовал изменить цвет на белый
col<-rep("white", length(unique(df$func1)))Или другой вариант - сделать черные точки белыми / прозрачными? в
col?
1 ответ
Решение
Возможно, прозрачность "B" и "C" решит вашу проблему, например
library(tidyverse)
obs <- c("Gene1", "Gene2", "Gene3", "Gene4","Gene5", "Gene6")
func1 <- c("A", "B", "C", "D", "C", "A")
func2 <- c("A1", "B1", "C1", "D1", "C2", "A2")
Cond1 <- c(0.007623561, 0.004639893, 0.000994121, 0.017494429, 0.000366445, 0.006663334)
Cond2 <- c(0.011299941, 0.009994388, 0.001012428, 0.013695669, 0.000299771, 0.010287904)
Cond3 <- c(0.005055458, 0.016826251, 0.001311254, 0.016115009, 0.000242897, 0.004583889)
df <- data.frame(obs, func1, func2, Cond1, Cond2, Cond3)
col<-rep("black", length(unique(df$func1)))
names(col) <- unique(df$func1)
col[which(names(col)=="A")] <- 'red'
col[which(names(col)=="D")] <- 'blue'
col[which(names(col)=="B" | names(col)=="C")] <- 'transparent'
#install.packages("ggtern")
library(ggtern)
g <- ggtern(data=df, aes(x=Cond1,y=Cond2,z=Cond3)) +
theme_bw() +
geom_point(aes(fill=func1), shape=21, size = 20, colour="black") +
scale_fill_manual(values=col) +
labs(x="Cond1",y="Cond2",z="Cond3") +
scale_T_continuous(breaks=unique(df$x))+
scale_L_continuous(breaks=unique(df$y))+
scale_R_continuous(breaks=unique(df$z))
print(g)
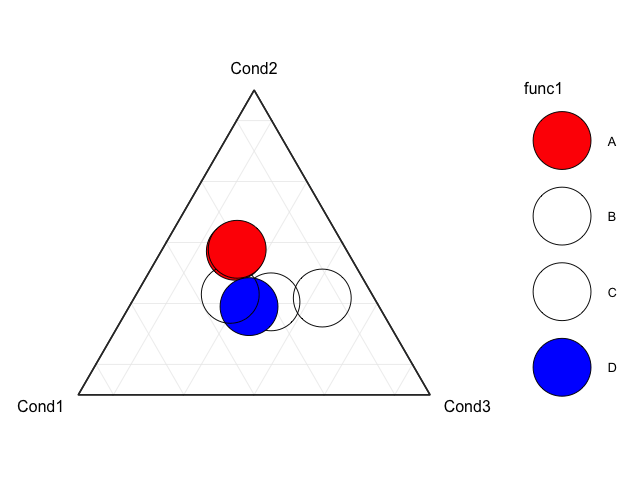
В противном случае вы можете указать порядок построения следующим образом (в соответствии с порядком управления точками в ggplot2 в R?):
library(tidyverse)
obs <- c("Gene1", "Gene2", "Gene3", "Gene4","Gene5", "Gene6")
func1 <- c("A", "B", "C", "D", "C", "A")
func2 <- c("A1", "B1", "C1", "D1", "C2", "A2")
Cond1 <- c(0.007623561, 0.004639893, 0.000994121, 0.017494429, 0.000366445, 0.006663334)
Cond2 <- c(0.011299941, 0.009994388, 0.001012428, 0.013695669, 0.000299771, 0.010287904)
Cond3 <- c(0.005055458, 0.016826251, 0.001311254, 0.016115009, 0.000242897, 0.004583889)
df <- data.frame(obs, func1, func2, Cond1, Cond2, Cond3)
col<-rep("black", length(unique(df$func1)))
names(col) <- unique(df$func1)
col[which(names(col)=="A")] <- 'red'
col[which(names(col)=="D")] <- 'blue'
#install.packages("ggtern")
library(ggtern)
library(tidyverse)
g <- ggtern(data=df, aes(x=Cond1,y=Cond2,z=Cond3)) +
theme_bw() +
geom_point(data = subset(df, !(func1 %in% c("A", "D"))),
aes(fill=func1), shape=21, size = 20, colour="black") +
geom_point(data = subset(df, func1 %in% c("A", "D")),
aes(fill=func1), shape=21, size = 20, colour="black") +
scale_fill_manual(values=col) +
labs(x="Cond1",y="Cond2",z="Cond3") +
scale_T_continuous(breaks=unique(df$x))+
scale_L_continuous(breaks=unique(df$y))+
scale_R_continuous(breaks=unique(df$z))
print(g)