Масштабируемость многопоточной векторной суммы
Вот фрагмент кода C++11 для многопоточной векторной суммы.
#include <thread>
template<typename ITER>
void sum_partial(ITER a, ITER b, double & result) {
result = std::accumulate(a, b, 0.0);
}
template<typename ITER>
double sum(ITER begin, ITER end, unsigned int nb_threads) {
size_t len = std::distance(begin, end);
size_t size = len/nb_threads;
std::vector<std::thread> thr(nb_threads-1);
std::vector<double> r(nb_threads);
size_t be = 0;
for(size_t i = 0; i < nb_threads-1; i++) {
size_t en = be + size;
thr[i] = std::thread(sum_partial<ITER>, begin + be, begin + en, std::ref(r[i]));
be = en;
}
sum_partial(begin + be, begin + len, r[nb_threads-1]);
for(size_t i = 0; i < nb_threads-1; i++)
thr[i].join();
return std::accumulate(r.begin(), r.end(), 0.0);
}
Типичное использование будет sum(x.begin(), x.end(), n) с x вектор двойников.
Вот график, показывающий время вычислений как функцию количества потоков (среднее время суммирования значений 10⁷, на 8-ядерном компьютере, на котором больше ничего не работает - я пробовал на 32-ядерном компьютере, поведение очень похожее).
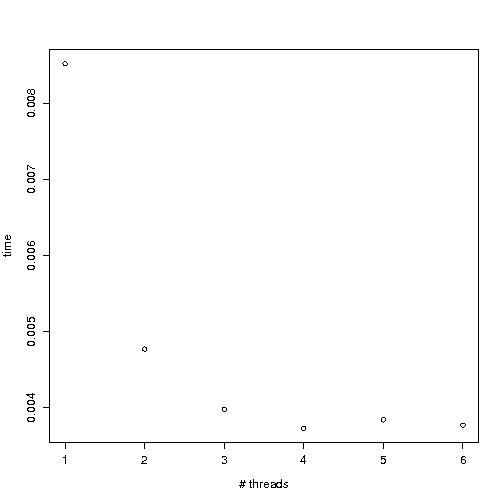
Почему масштабируемость так плоха? Можно ли это улучшить?
Мое (очень ограниченное) понимание состоит в том, что для хорошей масштабируемости потоки должны избегать записи в одной и той же строке кэша. Здесь все темы пишут в r однажды, в самом конце их вычислений, я не ожидал, что это будет ограничивающим фактором. Это проблема пропускной способности памяти?
1 ответ
accumulate имеет низкое использование арифметических единиц процессора, но пропускная способность кеша и памяти, скорее всего, будет узким местом, особенно для данных 10^7 double или 10 миллионов double = 80 МБ, что намного больше, чем размер кеша вашего ЦП.
Чтобы преодолеть узкие места в пропускной способности кеша и памяти, вы можете включить предварительную выборку с помощью -fprefetch-loop-arraysили даже вручную сделать некоторую сборку.