Обучение с подкреплением. Объезд объектов с PPO
Я работаю над управлением промышленными роботами с помощью нейронных сетей, и пока это работает хорошо. Я использую алгоритм PPO из базовой версии OpenAI, и пока я могу легко ездить от точки к точке, используя следующую стратегию вознаграждения:
Я вычисляю нормализованное расстояние между целью и позицией. Затем я рассчитываю вознаграждение за расстояние с помощью.
rd = 1-(d/dmax)^a
За каждый временной шаг я даю агенту штраф в размере.
yt = 1-(t/tmax)*b
a и b - гиперпараметры для настройки.
Как я уже сказал, это очень хорошо работает, если я хочу проехать от точки к точке. Но что, если я хочу что-то объехать? Для моей работы мне нужно избегать коллизий, и поэтому агент должен объезжать объекты. Если объект не находится прямо на пути ближайшего пути, он работает нормально. Тогда робот сможет адаптироваться и объехать его. Но становится все труднее или невозможнее объезжать объекты, которые прямо мешают.
Смотрите это изображение:
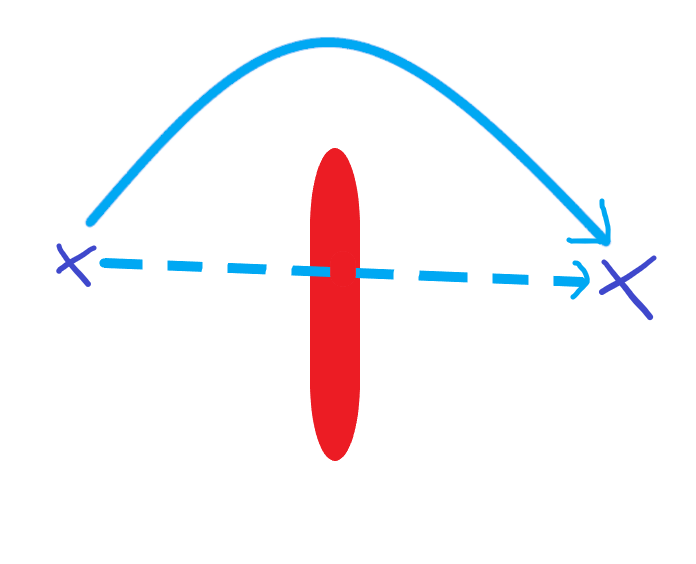
Я уже читал статью, в которой PPO сочетается с NES для создания некоторого гауссовского шума для параметров нейронной сети, но я не могу реализовать это самостоятельно.
Есть ли у кого-нибудь опыт добавления дополнительных исследований в алгоритм PPO? Или у кого-нибудь есть общие идеи, как я могу улучшить свою стратегию вознаграждения?
1 ответ
То, что вы описываете, на самом деле является одной из самых важных областей исследования Deep RL: проблема разведки.
Алгоритм PPO (как и многие другие "стандартные" алгоритмы RL) пытается максимизировать отдачу, которая представляет собой (обычно со скидкой) сумму вознаграждений, предоставляемых вашей средой:
В вашем случае у вас есть проблема с обманчивым градиентом, градиент вашего возврата указывает непосредственно на точку вашей цели (потому что ваша награда - это расстояние до вашей цели), что препятствует вашему агенту исследовать другие области.
Вот иллюстрация проблемы обманчивого градиента из этой статьи, вознаграждение вычисляется так же, как и ваше, и, как вы можете видеть, градиент вашей функции возврата указывает прямо на вашу цель (маленький квадрат в этом примере). Если ваш агент начинает работу в правой нижней части лабиринта, вы, скорее всего, застрянете в локальном оптимуме.
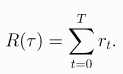
Есть много способов справиться с проблемой исследования в RL, например, в PPO вы можете добавить немного шума к своим действиям, некоторые другие подходы, такие как SAC, пытаются максимизировать как вознаграждение, так и энтропию вашей политики в пространстве действий, но в В конце концов, у вас нет гарантии, что добавление шума исследования в ваше пространство действий приведет к эффективному использованию вашего пространства состояний (что на самом деле вы хотите исследовать, позиции (x,y) вашего env).
Я рекомендую вам прочитать литературу о качественном разнообразии (QD), которая является очень многообещающей областью, направленной на решение проблемы разведки в RL.
Вот два замечательных ресурса:
Наконец, я хочу добавить, что проблема заключается не в вашей функции вознаграждения, вам не следует пытаться разработать сложную функцию вознаграждения, чтобы ваш агент мог вести себя так, как вы хотите. Цель состоит в том, чтобы иметь агента, способного решить вашу среду, несмотря на такие подводные камни, как проблема обмана с градиентом.