Tensorflow Quantum: PQC не оптимизируется
Я следил за учебником, доступным по адресу: https://www.tensorflow.org/quantum/tutorials/mnist. Я изменил это руководство на простейший пример, который мог придумать: набор входных данных, в котором x линейно увеличивается от 0 до 1 и y = x < 0,3. Затем я использую PQC с одним вентилем Rx с символом и считывание с использованием Z-ворот.
При извлечении оптимизированного символа и его настройке вручную я легко могу найти значение, обеспечивающее 100% точность, но когда я запускаю оптимизатор Adam, он сходится, чтобы либо всегда прогнозировать 1, либо всегда прогнозировать -1. Кто-нибудь замечает, что я делаю не так? (и я прошу прощения за то, что не смог разбить код на меньший пример)
import tensorflow as tf
import tensorflow_quantum as tfq
import cirq
import sympy
import numpy as np
# used to embed classical data in quantum circuits
def convert_to_circuit_cont(image):
"""Encode truncated classical image into quantum datapoint."""
values = np.ndarray.flatten(image)
qubits = cirq.GridQubit.rect(4, 1)
circuit = cirq.Circuit()
for i, value in enumerate(values):
if value:
circuit.append(cirq.rx(value).on(qubits[i]))
return circuit
# define classical dataset
length = 1000
np.random.seed(42)
# create a linearly increasing set for x from 0 to 1 in 1/length steps
x_train_sorted = np.asarray([[x/length] for x in range(0,length)], dtype=np.float32)
# p is used to shuffle x and y similarly
p = np.random.permutation(len(x_train_sorted))
x_train = x_train_sorted[p]
# y = x < 0.3 in {-1, 1} for Hinge loss
y_train_sorted = np.asarray([1 if (x/length)<0.30 else -1 for x in range(0,length)])
y_train = y_train_sorted[p]
# test == train for this example
x_test = x_train_sorted[:]
y_test = y_train_sorted[:]
# convert classical data into quantum circuits
x_train_circ = [convert_to_circuit_cont(x) for x in x_train]
x_test_circ = [convert_to_circuit_cont(x) for x in x_test]
x_train_tfcirc = tfq.convert_to_tensor(x_train_circ)
x_test_tfcirc = tfq.convert_to_tensor(x_test_circ)
# define the PQC circuit, consisting out of 1 qubit with 1 gate (Rx) and 1 parameter
def create_quantum_model():
data_qubits = cirq.GridQubit.rect(1, 1)
circuit = cirq.Circuit()
a = sympy.Symbol("a")
circuit.append(cirq.rx(a).on(data_qubits[0])),
return circuit, cirq.Z(data_qubits[0])
model_circuit, model_readout = create_quantum_model()
# Build the Keras model.
model = tf.keras.Sequential([
# The input is the data-circuit, encoded as a tf.string
tf.keras.layers.Input(shape=(), dtype=tf.string),
# The PQC layer returns the expected value of the readout gate, range [-1,1].
tfq.layers.PQC(model_circuit, model_readout),
])
# used for logging progress during optimization
def hinge_accuracy(y_true, y_pred):
y_true = tf.squeeze(y_true) > 0.0
y_pred = tf.squeeze(y_pred) > 0.0
result = tf.cast(y_true == y_pred, tf.float32)
return tf.reduce_mean(result)
# compile the model with Hinge loss and Adam, as done in the example. Have tried with various learning_rates
model.compile(
loss = tf.keras.losses.Hinge(),
optimizer=tf.keras.optimizers.Adam(learning_rate=0.1),
metrics=[hinge_accuracy])
EPOCHS = 20
BATCH_SIZE = 32
NUM_EXAMPLES = 1000
# fit the model
qnn_history = model.fit(
x_train_tfcirc, y_train,
batch_size=32,
epochs=EPOCHS,
verbose=1,
validation_data=(x_test_tfcirc, y_test),
use_multiprocessing=False)
results = model.predict(x_test_tfcirc)
results_mapped = [-1 if x<=0 else 1 for x in results[:,0]]
print(np.sum(np.equal(results_mapped, y_test)))
После 20 эпох оптимизации получаю следующее:
1000/1000 [==============================] - 0s 410us/sample - loss: 0.5589 - hinge_accuracy: 0.6982 - val_loss: 0.5530 - val_hinge_accuracy: 0.7070
В результате получается 700 выборок из 1000, предсказанных правильно. При просмотре сопоставленных результатов это связано с тем, что все результаты прогнозируются как -1. Если посмотреть на необработанные результаты, они линейно увеличиваются от -0,5484014 до -0,99996257.
При получении веса с помощью w = model.layers[0].get_weights(), вычитании 0,8 и повторной установке его с помощью model.layers[0].set_weights(w) я получаю 920/1000 правильно. Тонкая настройка этого процесса позволяет мне достичь 1000/1000.
Обновление 1: я также распечатал обновление веса за разные эпохи:
4.916246, 4.242602, 3.3765688, 2.6855211, 2.3405066, 2.206207, 2.1734586, 2.1656137, 2.1510274, 2.1634471, 2.1683235, 2.188944, 2.1510284, 2.1591303, 2.1632445, 2.1542525, 2.1677444, 2.1702878, 2.163104, 2.1635907
Я установил вес 1,36, значение, которое дает 908/1000 (в отличие от 700/100). Оптимизатор уходит от него:
1.7992111, 2.0727847, 2.1370323, 2.15711, 2.1686404, 2.1603785, 2.183334, 2.1563332, 2.156857, 2.169908, 2.1658351, 2.170673, 2.1575692, 2.1505954, 2.1561477, 2.1754034, 2.1545155, 2.1635509, 2.1464484, 2.1707492
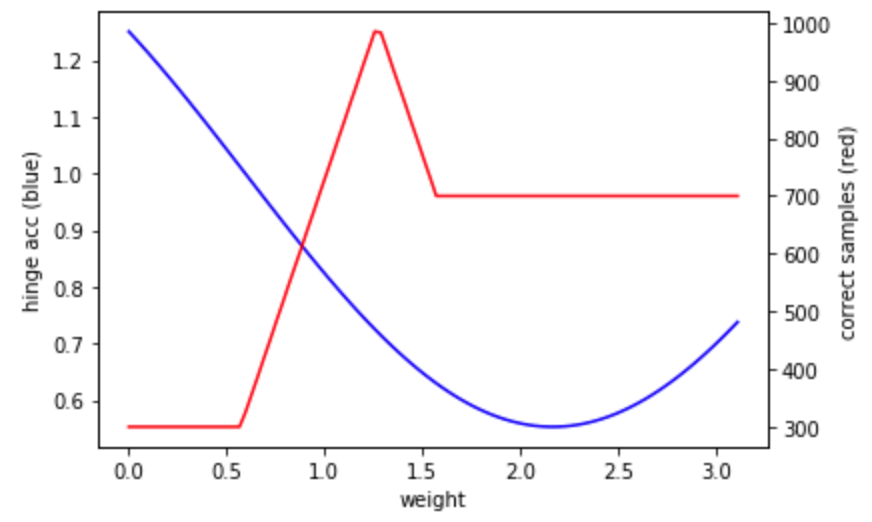
Я заметил одну вещь: точность шарнира составила 0,75 при весе 1,36, что выше 0,7 для 2,17. Если это так, то я либо нахожусь в неудачной части ландшафта оптимизации, где глобальный минимум не соответствует минимуму ландшафта потерь, либо значение потерь определяется неправильно. Это то, что я буду исследовать дальше.
1 ответ
Минимумы функции потерь шарнира для этих примеров не соответствуют максимальным значениям количества правильно классифицированных примеров. См. График этих значений относительно значения параметра. Учитывая, что оптимизатор работает в направлении минимума потерь, а не максимума числа классифицированных примеров, код (и фреймворк / оптимизатор) делают то, что они должны делать. В качестве альтернативы можно использовать другую функцию потерь, чтобы попытаться найти более подходящую. Например, бинаризованная потеря l1. Эта функция будет иметь такой же глобальный оптимум, но, вероятно, будет иметь очень плоский ландшафт.