Ссылочные массивы в Python
Я начал изучать структуры данных и алгоритмы. Пожалуйста, помогите мне с моими сомнениями.
Можно ли сказать, что списки, кортежи и словари являются типом ссылочного массива?
Я просматривал пример в книге, где было написано, что мы хотим, чтобы медицинская информационная система отслеживала пациентов, которые в настоящее время закреплены за койками в определенной больнице. Если мы предположим, что в больнице 200 коек и что удобно, что эти койки пронумерованы от 0 до 199, мы могли бы рассмотреть возможность использования структуры на основе массива для сохранения имен пациентов, которые в настоящее время закреплены за этими кроватями. Например, в Python мы можем использовать список имен, например:
[Рене, Джозеф, Джанет, Джонас, Хелен, Вирджиния, ... ]
Чтобы представить такой список в виде массива, Python должен придерживаться требования, чтобы каждая ячейка массива использовала одинаковое количество байтов. Тем не менее, элементы являются строками, и, естественно, строки имеют разную длину. Python может попытаться зарезервировать достаточно места для каждой ячейки для хранения строки максимальной длины (не только для текущих сохраненных строк, но и для любой строки, которую мы когда-либо захотим сохранить), но это было бы расточительно. Вместо этого Python представляет список или экземпляр кортежа, используя внутренний механизм хранения массива ссылок на объекты. На самом низком уровне сохраняется последовательная последовательность адресов памяти, в которой находятся элементы этой последовательности. Диаграмма высокого уровня такого списка показана на рисунке.
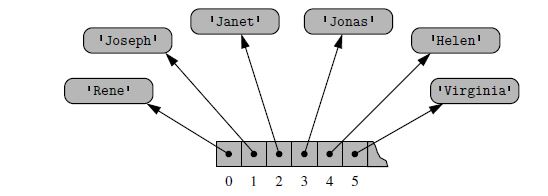
Я понял, что python хранит в памяти адрес "Рене" или "Джозефа". Но адреса памяти также будут меняться в зависимости от количества символов в имени, так как каждый Unicode занимает 2 байта пространства.
Теперь также было написано, что "Хотя относительный размер отдельных элементов может варьироваться, количество битов, используемых для хранения адреса памяти каждого элемента, является фиксированным (например, 64 бита на адрес, то есть 8 байтов). Что, если символ очень длинный и он не может хранить адрес памяти в 64 бита?
1 ответ
Можно ли сказать, что списки, кортежи и словари являются типом ссылочного массива?
Списки есть (хотя может иметь значение, что они имеют встроенное динамическое изменение размера), но в кортежах и словарях за кулисами происходит гораздо больше.
Я понял, что python хранит в памяти адрес "Рене" или "Джозефа". Но адреса памяти также будут меняться в зависимости от количества символов в имени, так как каждый Unicode занимает 2 байта пространства.
Адрес памяти - это целое число, описывающее, где найти данные, а сами данные представляют собой строку байтов, напримерb'Rene'. Я не уверен, что CPython использует, чтобы выяснить, где заканчивается структура данных, но общие подходы включают в себя нулевой терминатор (когда указан адрес, все байты, которые вы найдете, являются частью структуры данных, пока вы не достигнете нулевого байта), обеспечивая все объекты имеют одинаковый размер, так что вы можете пропустить вперед (что невозможно для строк) или имея первый (е) байт (ы), описывающий длину остальной части объекта. Сам адрес имеет фиксированный размер, например 64 бита.
На следующем рисунке "адрес", используемый в ссылочном массиве, будет равен 3, и вы узнаете, что последний байт строки произошел по адресу 6, пройдя, пока не найдете нулевой байт (другие подходы, о которых я упоминал, работают аналогично). Важно то, что 3 - единственное число, которое необходимо сохранить в ссылочном массиве, чтобы иметь возможность ссылаться на него.b'Rene'.
|3|4|5|6|7 |
|R|e|n|e|\0|
Что делать, если символ очень длинный и он не может хранить адрес памяти в 64 бита?
Фактически это было причиной того, что 32-разрядные системы не могли использовать более 4 ГБ ОЗУ - у них были только 32-разрядные идентификаторы для доступа к ОЗУ (без дополнительных методов, таких как назначение каждому процессу смещения ОЗУ, чтобы каждый процесс имел 32-разрядный идентификатор). битовое пространство памяти). Современные 64-битные системы позволяют проиндексировать 16 эксабайт ОЗУ без необходимости использования каких-либо других специальных методов - одна из основных причин перехода с 32 на 64 бит.
В любом случае, ограничения памяти - это реальная вещь, и если мы начнем нуждаться в адресе большего количества памяти, чем это, нам нужно будет использовать более сложные стратегии, чем целочисленные ссылки фиксированной ширины, или нам нужно будет снова вскочить и использовать большие целые числа.