Переупорядочиваются ли расслабленные атомные магазины перед выпуском? (аналогично загрузке / захвату)
Я прочитал в спецификациях en.cppreference.com расслабленные операции на атомике:
"[...] гарантирует только атомарность и согласованность порядка модификации ".
Итак, я спрашивал себя, будет ли работать такой "порядок модификации", когда вы работаете с одной и той же атомарной переменной или с разными.
В моем коде у меня есть атомное дерево, где поток сообщений с низким приоритетом, основанный на событиях, заполняет, какой узел должен быть обновлен, сохраняя некоторые данные на красном атомарном '1' (см. Рисунок), используя memory_order_relaxed. Затем он продолжает писать в свой родительский объект, используя fetch_or, чтобы узнать, какой дочерний атомар был обновлен. Каждый атомар поддерживает до 64 бит, поэтому я заполняю бит 1 красной операцией "2". Это продолжается до тех пор, пока корневой атомар не будет помечен с помощью fetch_or, но с использованием этого времениmemory_order_release.
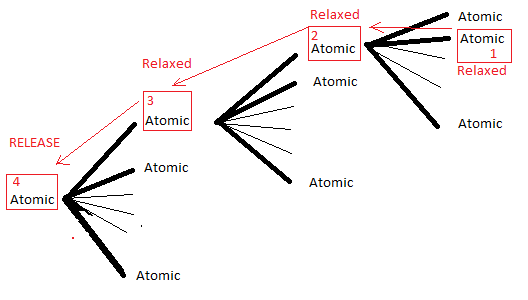
Затем быстрый неблокируемый поток в реальном времени загружает элемент управления (с memory_order_acquire) и читает, какие биты включены. Затем он рекурсивно обновляет дочерние атомы с помощьюmemory_order_relaxed. Именно так я синхронизирую свои данные с каждым циклом высокоприоритетного потока.
Поскольку этот поток обновляется, хорошо, что дочерние атомики хранятся перед его родительским. Проблема в том, что он сохраняет родителя (заполняя бит дочерних элементов для обновления) до того, как я заполню дочернюю информацию.
Другими словами, как говорится в названии, переупорядочиваются ли расслабленные магазины между ними перед выпуском? Я не возражаю против переупорядочения неатомарных переменных. Псевдокод, предположим, что [x, y, z, control] атомарны и с начальными значениями 0:
Event thread:
z = 1; // relaxed
y = 1; // relaxed
x = 1; // relaxed;
control = 0; // release
Real time thread (loop):
load control; // acquire
load x; // relaxed
load y; // relaxed
load z; // relaxed
Интересно, будет ли это всегда в потоке реального времени: x <= y <=z. Чтобы убедиться, что я написал эту небольшую программу:
#define _ENABLE_ATOMIC_ALIGNMENT_FIX 1
#include <atomic>
#include <iostream>
#include <thread>
#include <assert.h>
#include <array>
using namespace std;
constexpr int numTries = 10000;
constexpr int arraySize = 10000;
array<atomic<int>, arraySize> tat;
atomic<int> tsync {0};
void writeArray()
{
// Stores atomics in reverse order
for (int j=0; j!=numTries; ++j)
{
for (int i=arraySize-1; i>=0; --i)
{
tat[i].store(j, memory_order_relaxed);
}
tsync.store(0, memory_order_release);
}
}
void readArray()
{
// Loads atomics in normal order
for (int j=0; j!=numTries; ++j)
{
bool readFail = false;
tsync.load(memory_order_acquire);
int minValue = 0;
for (int i=0; i!=arraySize; ++i)
{
int newValue = tat[i].load(memory_order_relaxed);
// If it fails, it stops the execution
if (newValue < minValue)
{
readFail = true;
cout << "fail " << endl;
break;
}
minValue = newValue;
}
if (readFail) break;
}
}
int main()
{
for (int i=0; i!=arraySize; ++i)
{
tat[i].store(0);
}
thread b(readArray);
thread a(writeArray);
a.join();
b.join();
}
Как это работает: существует массив atomic. Один поток сохраняет с ослабленным порядком в обратном порядке и заканчивает сохранение элемента управления с порядком выпуска.
Другой поток загружает с порядком получения, который управляет атомарным, затем он загружает с расслабленным этим атомарным остальные значения массива. Поскольку родители не должны обновляться перед дочерними, newValue всегда должно быть равно или больше oldValue.
Я запускал эту программу на своем компьютере несколько раз, отлаживал и выпускал, и она не вызывает сбоя. Я использую обычный процессор Intel i7 x64.
Итак, можно ли предположить, что расслабленные хранилища для нескольких атомных модулей действительно сохраняют "порядок модификации", по крайней мере, когда они синхронизируются с управляющим атомом и получают / выпускают?
2 ответа
К сожалению, вы узнаете очень мало о том, что поддерживает Стандарт, поэкспериментируя с x86_64, потому что x86_64 очень хорошо себя ведет. В частности, если вы не укажете _seq_cst:
все чтения эффективно _acquire
все записи эффективно _release
если они не пересекают границу строки кэша. А также:
- все чтение-изменение-запись эффективно seq_cst
За исключением того, что компилятору (также) разрешено изменять порядок _релаксированных операций.
Вы упомянули об использовании _relaxed fetch_or... и, если я правильно понимаю, вы можете быть разочарованы, узнав, что это не менее дорого, чем seq_cst, и требуетLOCK префиксная инструкция, несущая все накладные расходы.
Но да, расслабленные атомарные операции неотличимы от обычных операций в том, что касается упорядочивания. Так что да, они могут быть переупорядочены относительно других _релаксированных атомарных операций, а также не-атомарных - компилятором и / или машиной. [Хотя, как уже отмечалось, на x86_64, а не на машине.]
И да, когда операция выпуска в потоке X синхронизируется - с операцией получения в потоке Y, все записи в потоке X, которые упорядочиваются - до того, как произойдет выпуск, - до получения в потоке Y. Итак, операция выпуска является сигналом что все записи, предшествующие ему в X, являются "завершенными", и когда операция получения видит этот сигнал, Y знает, что он синхронизирован, и может читать то, что было записано X (до выпуска).
Теперь, ключевая вещь, чтобы понять, является то, что просто делает магазин _Release не хватает, то значение, которое хранится должен быть однозначный сигнал нагрузки _acquire, что в магазине произошло. В противном случае, как груз может сказать?
Обычно такая пара _release / _acquire используется для синхронизации доступа к некоторой коллекции данных. Как только эти данные "готовы", store _release сигнализирует об этом. Любая загрузка _acquire, которая видит сигнал (или все нагрузки _acquire, которые видят сигнал), знает, что данные "готовы", и они могут их прочитать. Конечно, любые записи в данные, которые происходят после store _release, могут (в зависимости от времени) также быть замечены load (s) _acquire. Я пытаюсь сказать здесь, что может потребоваться другой сигнал, если будут внесены дальнейшие изменения в данные.
Ваша маленькая тестовая программа:
инициализирует
tsyncдо 0в писателе: в конце концов
tat[i].store(j, memory_order_relaxed), делаетtsync.store(0, memory_order_release)так что ценность
tsyncне меняется!в читателе: делает
tsync.load(memory_order_acquire)прежде чем делатьtat[i].load(memory_order_relaxed)и игнорирует значение, прочитанное из
tsync
Я здесь, чтобы сказать вам, что _Release / _acquire пары не синхронизатор - все эти магазины / нагрузка может также быть _relaxed. [Я думаю, что ваш тест пройдет успешно, если писателю удастся опередить читателя. Потому что на x86-64 все записи выполняются в порядке инструкций, как и все чтения.]
Для проверки семантики _release / _acquire я предлагаю:
инициализирует
tsyncдо 0 иtat[]на все ноль.в писателе: запустить
j = 1..numTriesв конце концов
tat[i].store(j, memory_order_relaxed), записыватьtsync.store(j, memory_order_release)это означает, что проход завершен, и что все
tat[]сейчасj.в читателе: делать
j = tsync.load(memory_order_acquire)переход через
tat[]должен найтиj <= tat[i].load(memory_order_relaxed)и после перевала
j == numTriesсигнализирует о том, что писатель закончил.
где сигнал, посланный писателем, заключается в том, что он только что завершил запись j, и продолжу с j+1, если только j == numTries. Но это не гарантирует порядок, в которомtat[] написаны.
Если вы хотели, чтобы писатель останавливался после каждого прохода и ждал, пока читатель его увидит и сигнализирует о том же, тогда вам нужен другой сигнал, и вам нужно, чтобы потоки ожидали своего соответствующего сигнала "вы можете продолжить".
Цитата о расслабленном предоставлении согласованности порядка модификации. только означает, что все потоки могут согласовать порядок модификации для этого одного объекта. т.е. заказ существует. Более позднее хранилище релизов, которое синхронизируется с загрузкой в другом потоке, гарантирует, что оно будет видимым. https://preshing.com/20120913/acquire-and-release-semantics/ имеет красивую диаграмму.
Каждый раз, когда вы сохраняете указатель, который другие потоки могут загружать и отменять, используйте как минимум mo_releaseесли какие-либо из указанных данных также были недавно изменены, если необходимо, чтобы читатели также видели эти обновления. (Это включает все, что косвенно достижимо, например уровни вашего дерева.)
В любом виде структуры данных на основе дерева / связанного списка / указателя в значительной степени единственный раз, когда вы могли бы использовать Relaxed, это были бы недавно выделенные узлы, которые еще не были "опубликованы" для других потоков. (В идеале вы можете просто передавать аргументы конструкторам, чтобы их можно было инициализировать, даже не пытаясь быть атомарными; конструктор дляstd::atomic<T>()не является атомарным. Таким образом, вы должны использовать хранилище релизов при публикации указателя на вновь созданный атомарный объект.)
На x86 / x86-64, mo_releaseне имеет дополнительных затрат; Простые хранилища asm уже имеют такой же строгий порядок, как и выпуск, поэтому компилятору нужно только заблокировать переупорядочение времени компиляции для реализацииvar.store(val, mo_release); Это также довольно дешево на AArch64, особенно если вы вскоре не будете загружать данные.
Это также означает, что вы не можете тестировать на небезопасность, используя оборудование x86; компилятор выберет один порядок для расслабленных хранилищ во время компиляции, пригвоздив их к операциям выпуска в любом выбранном порядке. (И операции x86 atomic-RMW всегда являются полными барьерами, по сути seq_cst. Ослабление их в исходном коде позволяет только переупорядочить во время компиляции. Некоторые ISA, отличные от x86, могут иметь более дешевые RMW, а также загружать или сохранять для более слабых заказов, хотя, даже acq_rel немного дешевле на PowerPC.)