Как преобразовать тексты, содержащиеся в подссылках ссылки в R?
Я пытаюсь прочесать этот сайт.
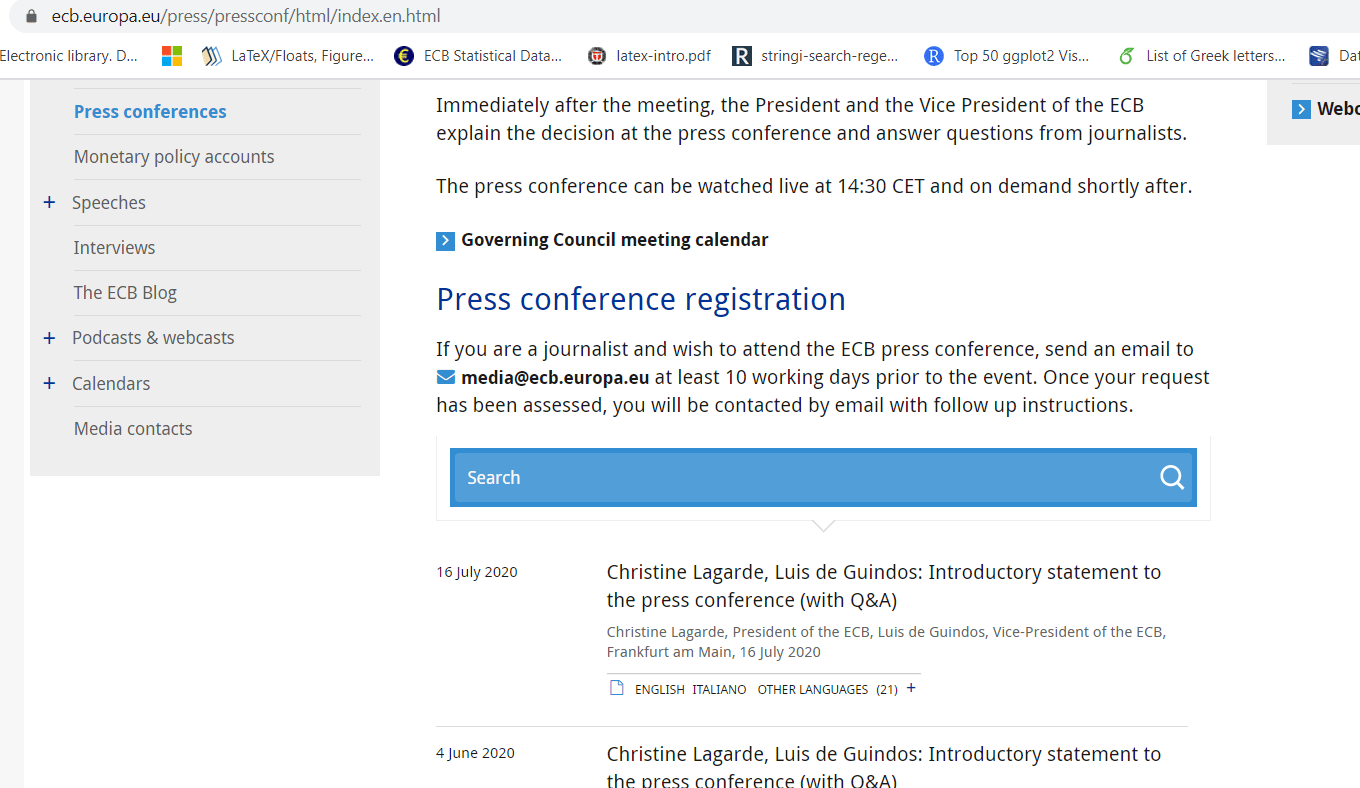
Как видите, есть одна основная ссылка и ряд заголовков, которые вы можете щелкнуть, чтобы получить доступ к тексту. В итоге я хотел бы получить текст во всех этих подссылках основной ссылки. Я не очень знаком с веб-сканированием, поэтому, оглядевшись, подумал, что что-то вроде:
library(rvest)
x <- read_html("https://www.ecb.europa.eu/press/pressconf/html/index.en.html")
x1 <- html_nodes(x, ".doc-title a") # this using selector gadget
Однако эта попытка терпит неудачу. Кто-нибудь может мне с этим помочь?
Большое спасибо!
1 ответ
Получить текст ссылок начальной страницы можно:
library(RSelenium)
library(rvest)
shell('docker run -d -p 4445:4444 selenium/standalone-firefox')
remDr <- remoteDriver(remoteServerAddr = "localhost", port = 4445L, browserName = "firefox")
remDr$open()
remDr$navigate("https://www.ecb.europa.eu/press/pressconf/html/index.en.html")
# This is useful to load all the page
for(i in 1 : 100)
{
print(i)
remDr$executeScript(paste0("scroll(0, ", i * 2000, ")"))
}
Sys.sleep(5)
html_Content <- remDr$getPageSource()[[1]]
html_Link <- str_extract_all(string = html_Content, pattern = "/press/pressconf/[^<]*html")[[1]]
html_Link_En <- html_Link[str_detect(html_Link, "\\.en\\.html")]
links_To_Remove <- c("/press/pressconf/html/index.en.html", "/press/pressconf/visual-mps/html/index.en.html" )
html_Link_En <- html_Link_En[!(html_Link_En %in% links_To_Remove)]
html_Link_En <- unique(html_Link_En)
# Extract text from first link
# It is possible to use a for loop to get the text of all links ...
html_Content <- read_html(paste0("https://www.ecb.europa.eu", html_Link_En[1]))
html_Content %>% html_text()