Как реализовать мета-круговой анализатор для синтаксического анализа `[1..10]` в JavaScript?
Я хочу реализовать мета-круговой оценщик на JS с поддержкой функционального программирования.
Как я могу это разобрать?
[1..10]
Я хочу получить 1 и 10
3 ответа
Это базовая реализация создания диапазона.
Цель, о которой вы говорите, будет слишком сложной для регулярного выражения (крепко иронично).
Использование синтаксиса тегированного литерала шаблона.
Regex находит двухзначные последовательности и преобразует их в числа. Заполняет массив.
range = (str,...args) =>
(([,min,max])=>
Array(Math.abs(max-min)+1).fill(+min).map((_,i)=>_+i*(min>max?-1:1)))
((Array.isArray(str) ? str.map((s,i)=>s+args[i]).join('') : str)
.match(/\[\s*(-?\d+)\s*\.\.\s*(-?\d+)\s*\]/))
x=-3, y=0
console.log(
range`[5..1]`,
range`[1..10]`,
range("[ 5 .. -2 ]"),
range`[${x}.. ${y}]`
)Я так давно хотел попробовать nearley.js. Это может быть то, что вы хотели, а может и не быть!
Обратите внимание: я предположил, что то, что вы хотите получить от [1..10] все числа из 1 к 10 (в комплекте), например [1,2,3,4,5,6,7,8,9,10].
Давайте определим грамматику для этого мини-языка
grammar.ne
# Given the string "[1..10]", AST is ['[', 1, '..', 10, ']']
# We define a postprocessor that immediately interprets the expression
range -> "[" number ".." number "]" {%
function range(ast) {
const [,a,,b,] = ast; // extracts the number from the ast
const len = Math.abs(a - b) + 1;
const inc = a < b ? (_, i) => a + i : (_, i) => a - i;
return Array.from(Array(len), inc);
}
%}
# Given the string "1", AST is [['1']]
# Given the string "10", AST is [['1','0']]
# We define a postprocessor that joins the characters together and coerce them into a number.
number -> [0-9]:+ {% ([chars]) => Number(chars.join('')) %}
Что мне нравится в nearley.js, так это то, что он позволяет вам встраивать постпроцессоры для ваших правил прямо в грамматику. Это может выглядеть некрасиво, но на самом деле я считаю его довольно изящным!
Еще одна замечательная вещь - это то, что nearley.js поставляется с набором полезных инструментов. Один из них создает диаграмму для вашей грамматики:
yarn run -s nearley-railroad grammar.ne > grammar.html
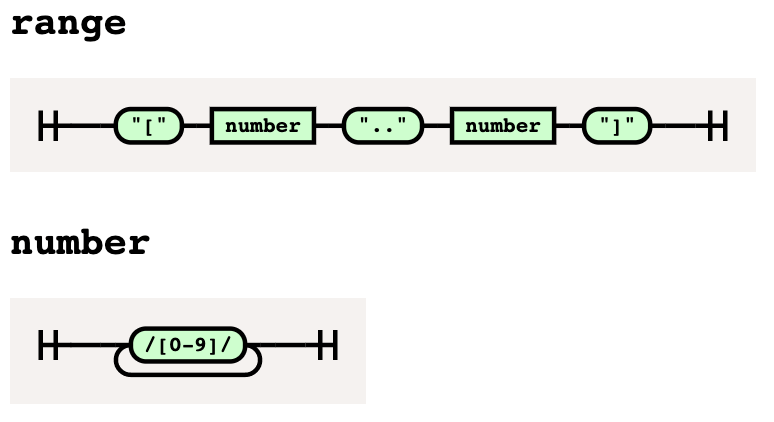
Вот результат:
Как видите, диапазон представляет собой последовательность:
- Начинается с
"[" - За ним следует число
- С последующим
".." - За ним следует число
- Заканчивается на
"]"
Теперь нам нужно скомпилировать эту грамматику
yarn run -s nearleyc grammar.ne > grammar.js
Этот код нужно загрузить в парсер. Я просто показываю скомпилированную грамматику для иллюстрации:
grammar.js
// Generated automatically by nearley, version 2.19.3
// http://github.com/Hardmath123/nearley
(function () {
function id(x) { return x[0]; }
var grammar = {
Lexer: undefined,
ParserRules: [
{"name": "range$string$1", "symbols": [{"literal":"."}, {"literal":"."}], "postprocess": function joiner(d) {return d.join('');}},
{"name": "range", "symbols": [{"literal":"["}, "number", "range$string$1", "number", {"literal":"]"}], "postprocess":
function range(ast) {
const [,a,,b,] = ast; // extracts the number from the ast
const len = Math.abs(a - b) + 1;
const inc = a < b ? (_, i) => a + i : (_, i) => a - i;
return Array.from(Array(len), inc);
}
},
{"name": "number$ebnf$1", "symbols": [/[0-9]/]},
{"name": "number$ebnf$1", "symbols": ["number$ebnf$1", /[0-9]/], "postprocess": function arrpush(d) {return d[0].concat([d[1]]);}},
{"name": "number", "symbols": ["number$ebnf$1"], "postprocess": ([chars]) => Number(chars.join(''))}
]
, ParserStart: "range"
}
if (typeof module !== 'undefined'&& typeof module.exports !== 'undefined') {
module.exports = grammar;
} else {
window.grammar = grammar;
}
})();
Теперь создадим парсер и воспользуемся им!
index.js
const nearley = require("nearley");
const grammar = require("./grammar"); // loads the compiled grammar!
const parser = new nearley.Parser(nearley.Grammar.fromCompiled(grammar));
parser.feed("[1..10]");
console.log(parser.results[0]);
//=> [1,2,3,4,5,6,7,8,9,10]
Регулярное выражение: \[([0-9]+)\.\.([0-9]+)\]
Я подтвердил регулярное выражение через regex101.com и позволил ему сгенерировать образец кода.
const regex = /\[([0-9]+)\.\.([0-9]+)\]/gm;
const str = `[1..10]`;
let m;
while ((m = regex.exec(str)) !== null) {
// This is necessary to avoid infinite loops with zero-width matches
if (m.index === regex.lastIndex) {
regex.lastIndex++;
}
// The result can be accessed through the `m`-variable.
m.forEach((match, groupIndex) => {
console.log(`Found match, group ${groupIndex}: ${match}`);
});
}Результат:
Found match, group 0: 1..10
Found match, group 1: 1
Found match, group 2: 10