count_words из Graphlab в ipynb
Я хожу на курс по созданию задач машинного обучения. Тема про анализ настроений. Нам поручено анализировать слова с помощью text_analytics. Это дает нам указания о том, как действовать, но я застрял. Я вижу, что некоторые вопросы уже подняты в SO, но я не нашел нужного мне решения.
Python: количество вхождений в dict из другого списка
Как посчитать количество вхождений слова в столбец
Итак, мы пытаемся оценить отзывы от Amazon. Использование текстовой аналитики count_word в graphlab, но не всех слов, а только выбранных. Мы должны проверить, есть ли в отзывах такие слова:
selected_words = ['awesome', 'great', 'fantastic', 'amazing', 'love', 'horrible', 'bad', 'terrible', 'awful', 'wow', 'hate']
Мне как-то удается извлекать данные. Увидеть ниже.
Но для этого нам потребовалось получить доступ к этим подсчетам и создать другой столбец, используя базу.apply() из имеющегося подсчета. См. Изображение ниже.
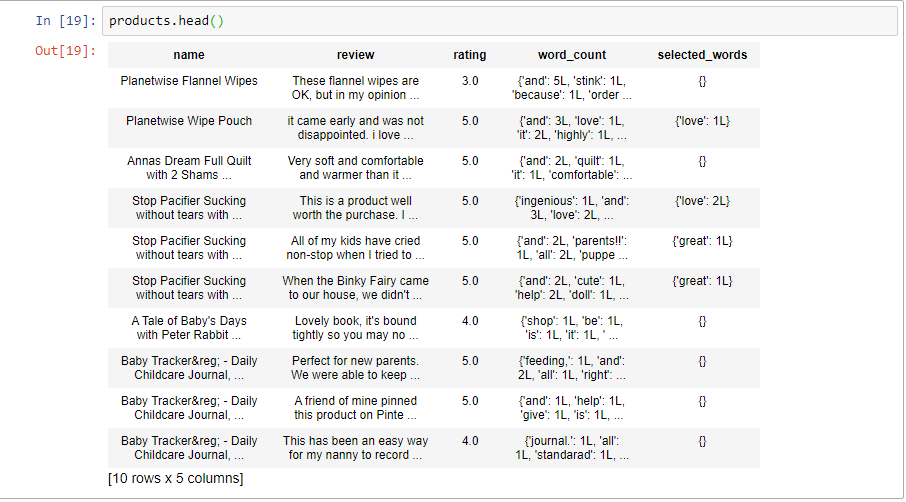
Как мне получить доступ к количеству слов и числовой части. Пожалуйста, предложите несколько способов их обойти.
Затем я смогу использовать love.sum(), чтобы подсчитать, сколько раз это слово "любовь" появлялось во всех обзорах и продолжалось с другими словами в selected_words.