Как очистить данные с веб-сайта и записать в CSV в указанном формате в R?
Я пытаюсь очистить данные с https://www.booking.com/country.html.
Идея состоит в том, чтобы извлечь все числа, касающиеся любого типа жилья, указанного для конкретной страны.
Выходные данные должны содержать список всех стран в столбце A файла Excel и соответствующее количество списков для различных типов собственности (например, апартаменты, хостелы, курорты и т. Д.) В каждой соответствующей стране, рядом с названиями стран. в отдельные столбцы.
Мне нужно собрать все детали для всех типов собственности в данной стране.

На изображении выше описан выходной формат, необходимый в Excel. Я могу получить страну, используя приведенный ниже код, но не типы собственности и соответствующие данные.
Как получить данные итеративно в функции для всех стран и записать в CSV.
library(rvest)
library(reshape2)
library(stringr)
url <- "https://www.booking.com/country.html"
bookingdata <- read_html(url)
#extracting the country
country <- html_nodes(bookingdata, "h2 > a") %>%
html_text()
write.csv(country, 'D:\\web scraping\\country.csv' ,row.names = FALSE)
print(country)
#extracting the data inside the inner div
html_nodes(bookingdata, "div >div > div > ul > li > a")%>%
html_text()
for (i in country) {
print(i)
html_nodes(pg, "ul > li > a") %>%
html_text()
print(accomodation)
}
#getting all the data
accomodation <- html_nodes(pg, "ul > li > a") %>%
html_text()
#separating the numbers
accomodation.num <- (str_extract(accomodation, "[0-9]+"))
#separating the characters
accomodation.char <- (str_extract(accomodation,"[aA-zZ]+"))
#separating unique characters
unique(accomodation.char)
1 ответ
import requests
from bs4 import BeautifulSoup
import pandas as pd
r = requests.get('https://www.booking.com/country.html')
soup = BeautifulSoup(r.text, 'html.parser')
data = []
for item in soup.findAll('div', attrs={'class': 'block_third block_third--flag-module'}):
country = [(country.text).replace('\n', '')
for country in item.findAll('a')]
data.append(country)
final = []
for item in data:
final.append(item)
df = pd.DataFrame(final)
df.to_csv('output.csv')
Просмотреть выходные данные в Интернете: нажмите здесь
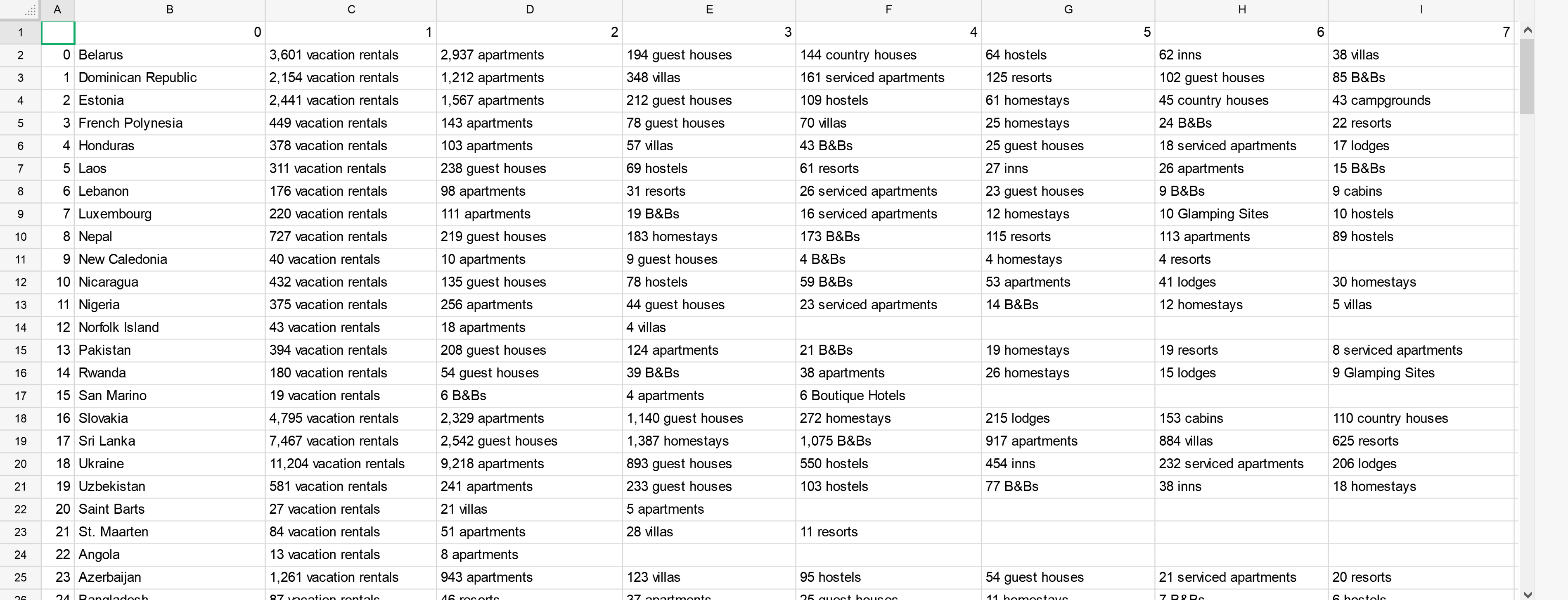
Другая версия для требований пользователя через ЧАТ:
import requests
from bs4 import BeautifulSoup
import pandas as pd
r = requests.get('https://www.booking.com/country.html')
soup = BeautifulSoup(r.text, 'html.parser')
data = []
for item in soup.select('div.block_third.block_third--flag-module'):
country = [(country.text).replace('\n', '')
for country in item.select('a')]
data.append(country)
final = []
for item in data:
final.append(item)
df = pd.DataFrame(final).set_index(0)
df.index.name = 'location'
split = df.stack().str.extract('^(?P<freq>[\d,]+)\s+(?P<category>.*)').reset_index(level=1, drop=True)
pvt = split.pivot(columns='category', values='freq')
pvt.sort_index(axis=1, inplace=True)
pvt.reset_index().to_csv('output2.csv', index=False)