Как соскрести данные с Morningstar
Итак, я новичок в мире парсинга веб-сайтов, и до сих пор я действительно использовал beautifulsoup только для очистки текста и изображений с веб-сайтов. Я думал, что попробую соскрести некоторые точки данных с графика, чтобы проверить свое понимание, но этот график меня немного запутал.
После проверки элемента данных, который я хотел извлечь, я увидел следующее:<span id="TSMAIN">: 100.7490637</span>Проблема в том, что моя первоначальная идея для очистки точек данных заключалась в том, чтобы перебирать какой-то список идентификаторов, содержащий все различные точки данных (если это имеет смысл?).
Вместо этого кажется, что все точки данных содержатся в одном элементе, а значение зависит от того, где находится ваш курсор на графике.
Моя проблема в том, что если я использую функцию beautifulsoups find и набираю этот конкретный элемент с этим атрибутом id знак равно TSMAIN, Я получаю возврат без типа, потому что предполагаю, что если курсор не будет на реальном графике, там ничего не будет отображаться.
Код:
from bs4 import BeautifulSoup
import requests
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"}
url = "https://www.morningstar.co.uk/uk/funds/snapshot/snapshot.aspx?id=F0GBR050AQ&tab=13"
source=requests.get(url,headers=headers)
soup = BeautifulSoup(source.content,'lxml')
data = soup.find("span",attrs={"id":"TSMAIN"})
print(data)
Выход
None
Как я могу извлечь все точки данных этого графика?
1 ответ
Похоже, данные можно вытащить из API. Единственное, что возвращаемые значения относятся к дате начала, введенной в полезные данные. Он установит дату начала на0, то числа после даты относятся к этой дате.
import requests
import pandas as pd
from datetime import datetime
from dateutil import relativedelta
userInput = input('Choose:\n\t1. 3 Month\n\t2. 6 Month\n\t3. 1 Year\n\t4. 3 Year\n\t5. 5 Year\n\t6. 10 Year\n\n -->: ')
userDict = {'1':3,'2':6,'3':12,'4':36,'5':60,'6':120}
n = datetime.now()
n = n - relativedelta.relativedelta(days=1)
n = n - relativedelta.relativedelta(months=userDict[userInput])
dateStr = n.strftime('%Y-%m-%d')
url = 'https://tools.morningstar.co.uk/api/rest.svc/timeseries_cumulativereturn/t92wz0sj7c'
data = []
idDict = {
'Schroder Managed Balanced Instl Acc':'F0GBR050AQ]2]0]FOGBR$$ALL',
'GBP Moderately Adventurous Allocation':'EUCA000916]8]0]CAALL$$ALL',
'Mixed Investment 40-85% Shares':'LC00000012]8]0]CAALL$$ALL',
'':'F00000ZOR1]7]0]IXALL$$ALL',}
for k, v in idDict.items():
payload = {
'encyId': 'GBP',
'idtype': 'Morningstar',
'frequency': 'daily',
'startDate': dateStr,
'performanceType': '',
'outputType': 'COMPACTJSON',
'id': v,
'decPlaces': '8',
'applyTrackRecordExtension': 'false'}
temp_data = requests.get(url, params=payload).json()
df = pd.DataFrame(temp_data)
df['timestamp'] = pd.to_datetime(df[0], unit='ms')
df['date'] = df['timestamp'].dt.date
df = df[['date',1]]
df.columns = ['date', k]
data.append(df)
final_df = pd.concat(
(iDF.set_index('date') for iDF in data),
axis=1, join='inner'
).reset_index()
final_df.plot(x="date", y=list(idDict.keys()), kind="line")
Выход:
print (final_df.head(5).to_string())
date Schroder Managed Balanced Instl Acc GBP Moderately Adventurous Allocation Mixed Investment 40-85% Shares
0 2019-12-22 0.000000 0.000000 0.000000 0.000000
1 2019-12-23 0.357143 0.406784 0.431372 0.694508
2 2019-12-24 0.714286 0.616217 0.632422 0.667586
3 2019-12-25 0.714286 0.616217 0.632422 0.655917
4 2019-12-26 0.714286 0.612474 0.629152 0.664124
....
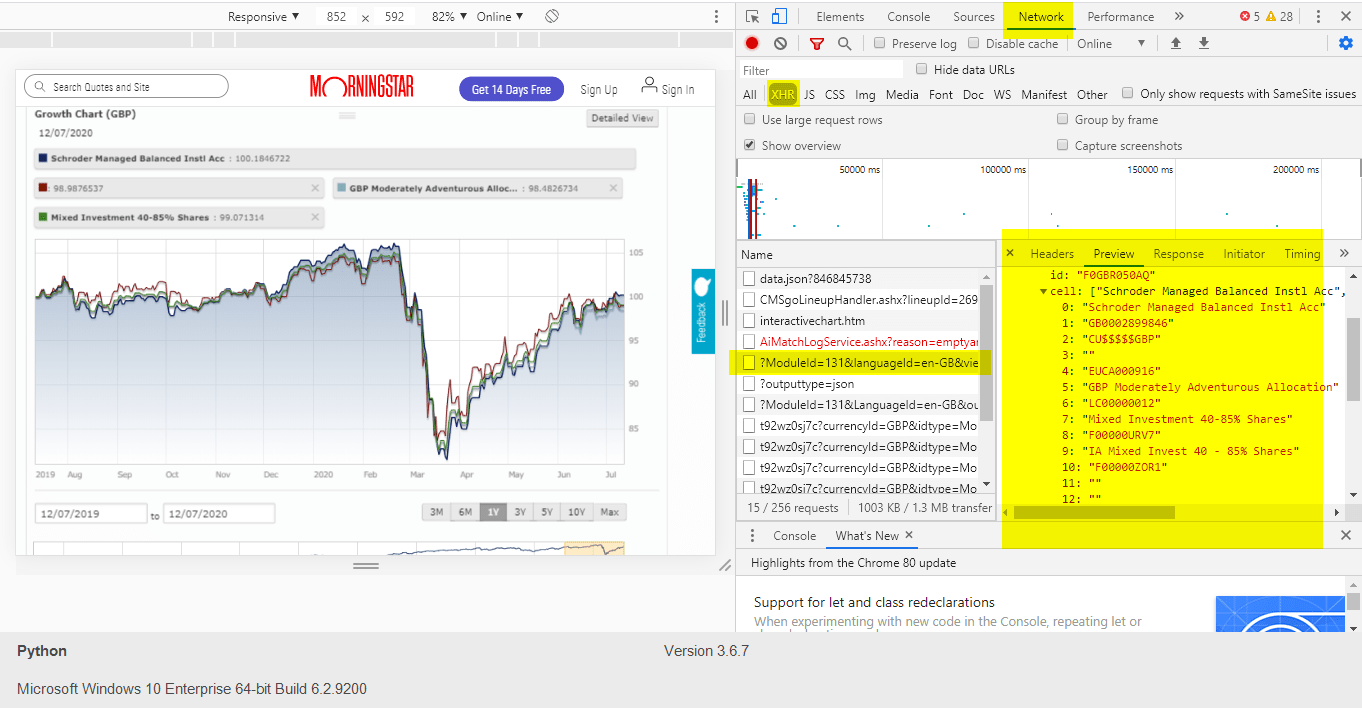
Чтобы получить эти идентификаторы, потребовалось небольшое исследование запросов. Просматривая их, я смог найти соответствующие значения id и с помощью небольшого количества проб и ошибок выяснить, какие значения и что означают.
Используемые "альтернативные" идентификаторы. И откуда эти линейные графики берут данные (в этом 4 запросе, посмотрите на панель предварительного просмотра, и вы увидите там данные.
Вот окончательный результат / график: