Как мне получить значение из строки, содержащей два интересующих ключевых слова, чтобы создать новый столбец на R?
У меня есть таблица данных, которая выглядит так:
И что я в основном хочу сделать, так это создать новый столбец в таблице, содержащий изменение кратности в моем "показании" для каждого образца, который будет, например,
Образец 1 на НЕДЕЛЕ 0/ Образец 1 на НЕДЕЛЕ 0
Образец 1 на НЕДЕЛЕ 4/ Образец 1 на НЕДЕЛЕ 0
Образец 1 на 14-й НЕДЕЛЕ / Образец 1 на 0-й НЕДЕЛЕ
и так далее, и так далее для всех временных точек для Образца 1, а затем рассчитайте то же самое для остальных моих образцов, используя их соответствующие "отсчеты" из НЕДЕЛИ 0.
Пока что я пробовал что-то вроде,
r
SampleIDs<-as.character(unique(table$ID))
table$FC<-for(i in table[i,]){
for(j in SampleIDs){
if(table[i,"ID"]==j){
table[i,3]/table[(("WEEK"==0)&("ID"==j)),3]
}
}
}
}
При запуске код возвращает ошибку,
Error in if (table[i, "SampleID"] == j) { : argument is of length zero
Что я пытался сделать, так это создать отдельный вектор с уникальными идентификаторами и использовать его в функции for, чтобы переходить строка за строкой, чтобы убедиться, что строка содержит образец с тем же идентификатором, а затем попытаться получить ячейку, которая содержит данные для образца с ID j И за НЕДЕЛЮ 0 для расчета моего значения кратного изменения. Любая помощь в том, как это сделать, будет принята с благодарностью! Спасибо
2 ответа
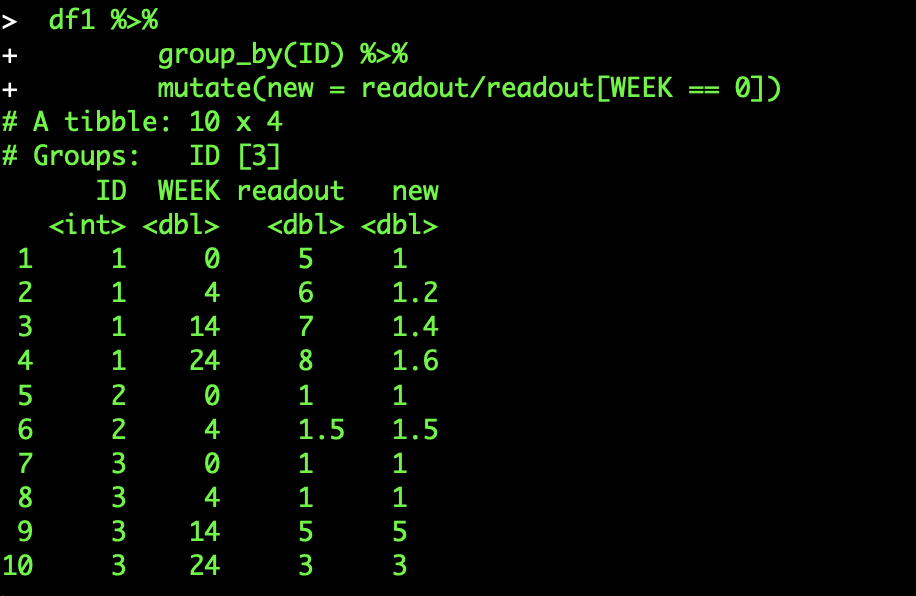
Может быть, мы могли бы сгруппировать по "ID" и создать новый столбец, разделив "показания" на "показания", где "WEEK" равно 0.
library(dplyr)
df1 %>%
group_by(ID) %>%
mutate(new = readout/readout[WEEK == 0])
Если НЕДЕЛЯ уже заказана
df1 %>%
group_by(ID) %>%
mutate(new = readout/readout[1])
Или с data.table
library(data.table)
setDT(df1)[, new := readout/readout[WEEK == 0], by = ID]
Если это уже заказано
setDT(df1)[, new := readout/readout[1], by = ID]
Или используя base R
df1$new <- with(df1, readout/setNames(readout[WEEK == 0], unique(ID))[ID])
Что касается показа консоли +, это просто символ, показывающий, что выражение не завершено
Это мы получаем и на других консолях, например, в Julia REPL не будет отображать никаких символов, но будет выдавать результат после завершения полного выражения
данные
df1 <- structure(list(ID = c(1L, 1L, 1L, 1L, 2L, 2L, 3L, 3L, 3L, 3L),
WEEK = c(0, 4, 14, 24, 0, 4, 0, 4, 14, 24), readout = c(5,
6, 7, 8, 1, 1.5, 1, 1, 5, 3)), class = "data.frame", row.names = c(NA,
-10L))
Вы не должны использовать forцикл для операций, которые должны выполняться группой. Есть функции, которые помогут вам выполнить такой сгруппированный расчет.
Если данные еще не упорядочены WEEK, вы можете сделать это в первую очередь.
df <- df1[with(df1, order(ID, WEEK)),]
а затем разделить readout по первому значению в каждой группе.
Это можно сделать в базе R:
df$result <- with(df, readout/ave(readout, ID, FUN = function(x) x[1]))
dplyr
library(dplyr)
df %>% group_by(ID) %>% mutate(result = readout/first(readout))
а также data.table
library(data.table)
setDT(df)[, result := readout/first(readout), ID]