Распространение неожиданных действий для пользовательской среды RL
Я работаю над созданием настраиваемой среды и обучаю на ней агента RL.
Я использую стабильные базовые показатели, потому что они, кажется, реализуют все новейшие алгоритмы RL и, кажется, максимально приближены к принципу "подключи и работай" (я хотел бы сосредоточиться на создании среды и функции вознаграждения, а не на деталях реализации самой модели)
В моей среде есть пространство действий размером 127, и я интерпретирую его как горячий вектор: принимая индекс самого высокого значения в векторе в качестве входного значения. Для отладки я создаю гистограмму, показывающую, сколько раз каждое значение было "вызвано"
Перед тренировкой я ожидал, что график покажет примерно равномерное распределение "событий":
но вместо этого "события" в нижней части спецификации действия гораздо более вероятны, чем другие: 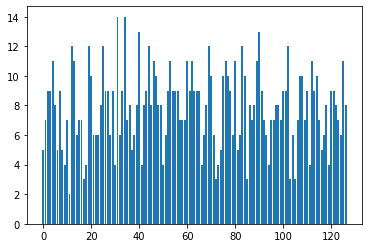
Я создал колаб, чтобы объяснить и воспроизвести проблему
Я задал этот вопрос в проблеме с github, но они рекомендовали опубликовать вопрос здесь
1 ответ
В model.predict(obs) фиксирует каждое действие в диапазоне [-1, 1](потому что именно так вы определили свое пространство действий). Таким образом, ваш массив значений действий выглядит примерно так
print(action)
# [-0.2476, 0.7068, 1., -1., 1., 1.,
# 0.1005, -0.937, -1. , ...]
То есть все действия, которые были больше 1, усекаются / обрезаются до 1, и, таким образом, существует несколько максимальных действий. В своей среде вы вычисляете numpy argmaxpitch = np.argmax(action), который возвращает индекс первого максимального значения, а не случайно выбранного (если есть несколько максимумов).
Вы можете выбрать "случайный argmax" следующим образом.
max_indeces = np.where(action == action.max())[0]
any_argmax = np.random.choice(max_indeces)
Я соответствующим образом изменил ваш env здесь.