Запись на шину PCIe атомарна?
Я новичок в PCIe, поэтому это может быть глупый вопрос. Это кажется довольно простой информацией об интерфейсах PCIe, но мне не удается найти ответ, поэтому я предполагаю, что мне не хватает некоторой информации, которая делает ответ очевидным.
У меня есть система, в которой у меня есть процессор ARM (хост), связывающийся с Xilinx SoC через PCIe (устройство). Конечная точка в SoC также является процессором ARM.
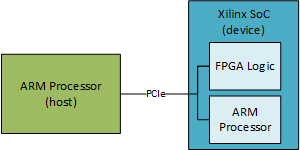
Внешний процессор ARM (хост) будет записывать в регистровое пространство процессора ARM (устройства) SoC через PCIe. Это заставит SoC делать разные вещи. Это регистровое пространство будет доступно только для чтения для SoC (устройства). Внешний процессор ARM (хост) выполнит запись в это пространство регистров, а затем подаст сигнал прерывания, чтобы указать SoC, что были записаны новые параметры, и он должен их обработать.
Мой вопрос: гарантированно ли записи, сделанные внешним ARM (хостом), будут атомарными по сравнению с чтениями SoC (устройством)? В обычных ситуациях с общей памятью запись в один байт гарантированно будет атомарной операцией (т.е. вы никогда не окажетесь в ситуации, когда читатель прочитал первые 2 бита байта, но прежде, чем он прочитает последние 6 бит, Writer заменяет их новым значением, что приводит к мусору данных). То же самое и с PCIe? И если да, то какова "единица" атомности? Все ли байты в одной транзакции атомарны по отношению ко всей транзакции, или каждый байт атомарен только по отношению к себе?
Имеет ли смысл этот вопрос?
В основном я хочу знать, в какой степени защита памяти необходима в моей ситуации. Если это вообще возможно, я бы хотел избежать блокировки областей памяти, поскольку оба процессора работают с ОСРВ, и отказ от блокировок памяти упростил бы дизайн.
1 ответ
Так что по вопросу об атомарности спецификация PCIe 3.0 (только одна у меня) упоминается несколько раз.
Сначала у вас есть РАЗДЕЛ 6.5 Заблокированные транзакции, это, вероятно, не то, что вам нужно, но я все равно хочу задокументировать это. По сути, это наихудший сценарий того, что вы описывали ранее.
Поддержка заблокированных транзакций необходима для предотвращения взаимоблокировки в системах, использующих устаревшее программное обеспечение, которое вызывает доступ к устройствам ввода-вывода.
Но вам все равно нужно правильно проверить это, как он отмечает.
Если какое-либо чтение, связанное с заблокированной последовательностью, завершается неудачно, запрашивающая сторона должна предположить, что атомарность блокировки больше не гарантирована и что путь между запрашивающей стороной и завершителем больше не заблокирован.
С учетом вышесказанного Раздел 6.15. Атомарные операции (AtomicOps) намного больше похож на то, что вас интересует. Есть 3 типа операций, которые вы можете выполнять с помощью инструкции AtomicOps.
FetchAdd (выборка и добавление): запрос содержит единственный операнд, значение "добавить".
Своп (безусловный своп): запрос содержит единственный операнд, значение "своп".
CAS (сравнение и своп): запрос содержит два операнда, значение "сравнить" и значение "своп".
Читая Раздел 6.15.1, мы видим упоминание о том, что эти инструкции в основном реализованы для случаев, когда на одной шине существует несколько производителей / потребителей.
AtomicOps включает расширенные механизмы синхронизации, которые особенно полезны при наличии нескольких производителей и / или нескольких потребителей, которые необходимо синхронизировать без блокировки. Например, несколько производителей могут безопасно помещаться в общую очередь без явной блокировки.
Просматривая остальную часть спецификации, я нахожу мало упоминаний об атомарности вне разделов, относящихся к этим AtomicOps. Для меня это означало бы, что спецификация обеспечивает такое поведение только при использовании этих операций, однако контекст вокруг того, почему это было реализовано, предполагает, что они ожидают таких вопросов только тогда, когда существует среда с несколькими производителями / потребителями, чего в вашей явно нет.
Последнее место, где я бы посоветовал ответить на ваш вопрос, - это Раздел 2.4. Порядок транзакций. Обратите внимание, что я вполне уверен, что идея передачи транзакций другим имеет смысл только с переключателями посередине, поскольку эти переключатели могут принимать такие решения, как только вы поместите биты в автобусе в твоем случае пути назад нет. Так что это, вероятно, применимо только в том случае, если вы поместите там переключатель.
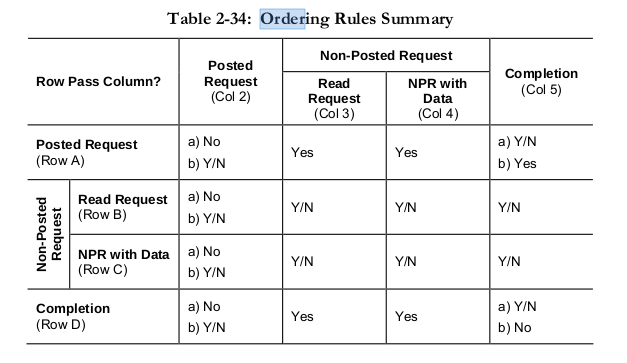
Вас беспокоит, может ли запись обойти чтение. Пишите, когда пишите, читайте, когда не пишите
A3, A4 A Posted Request must be able to pass Non-Posted Requests to avoid deadlocks.
Так что, как правило, записи разрешается обходить чтение, чтобы избежать взаимоблокировок.
Учитывая возникшую обеспокоенность, я не верю, что запись может обойти чтение в вашей системе, поскольку на шине нет устройства, которое могло бы переупорядочить эту транзакцию. Поскольку у вас есть ОСРВ, я очень сомневаюсь, что они запрашивают транзакции PCIe и меняют их порядок перед отправкой, хотя я лично не изучал это.