Эквивалентны ли эти две разные формулы для обновления Value-Iteration?
Изучая MDP из разных источников, я наткнулся на две разные формулы для обновления значения в алгоритме Value-Iteration.
Первый (тот, что есть в Википедии и пара книг):
.
И второй (в некоторых вопросах здесь, в стеке и на слайдах моего курса): 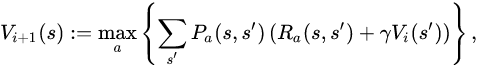
Для конкретной итерации они, похоже, не дают одинаковый ответ. Один из них быстрее подходит к решению?
1 ответ
На самом деле разница заключается в функциях вознаграждения R(s, s') или R(s) во второй формуле.
Первое уравнение является обобщенным.
В первом вознаграждении будет Ra(s, s') при переходе из состоянияs государству s' должное действие a'. Награда могла быть разной за разные состояния и действия.
Но если для каждого штата s у нас есть заранее определенная награда (независимо от предыдущего состояния и действия, которое приводит к s), то мы можем упростить формулу до второй.
Окончательные значения не обязательно равны, но политика одинакова.