RegEx - от 1 до 10 буквенно-цифровых пробелов Хорошо
Новое в регулярных выражениях. Заранее спасибо!
Необходимо подтвердить поле 1-10 буквенно-цифровых символов в смешанном регистре и допускаются пробелы. Первый символ должен быть буквенно-цифровым, а не пробелом.
Хорошие примеры:
"Ларри Кинг"
"L King1"
"1larryking"
"L"
Плохой пример:
"ЛарриКинг"
Это то, что у меня есть, и оно работает, пока данные ровно 10 символов. Проблема в том, что он не допускает менее 10 символов.
[0-9a-zA-Z] [0-9a-zA-Z] [0-9a-zA-Z] [0-9a-zA-Z] [0-9a-zA-Z] [0-9a- zA-Z] [0-9a-zA-Z] [0-9a-zA-Z] [0-9a-zA-Z] [0-9a-zA-Z]
Я читал и пробовал много разных вещей, но просто не понимаю.
Спасибо,
Джастин
7 ответов
Я не знаю, какую среду вы используете и какой движок. Поэтому я предполагаю, что PCRE (обычно для PHP)
это маленькое регулярное выражение делает именно то, что вы хотите: ^(?i)(?!\s)[a-z\d ]{1,10}$
В чем дело?!
^отмечает начало строки (удалите его, если выражение не должно соответствовать всей строке)(?i)говорит, что движок нечувствителен к регистру, поэтому нет необходимости писать все буквы в нижнем и верхнем регистре в выражении позже(?!\s)гарантирует, что следующий символ не будет пустым пространством (\s) (это так называемый негативный взгляд)[a-z\d ]{1,10}соответствует любой букве (a-z), любая цифра (\d) и пробелы () подряд с минимальным 1 и максимальным 10 вхождениями ({1,10})$в конце отмечает конец строки (удалите его, если выражение не должно соответствовать всей строке)
Вот также небольшая визуализация для лучшего понимания.
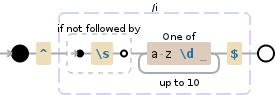
Попробуй это: ^[(^\s)a-zA-Z0-9][a-z0-9A-Z ]*
Не пробел и буквенно-цифровой для первого символа, а затем ноль или более буквенно-цифровых символов. Он не ограничен 10 символами, но будет работать для любого набора из 1-10 символов.
Вы хотите что-то вроде этого.
[a-zA-Z0-9][a-zA-Z0-9 ]{0,9}
Эта первая часть гарантирует, что это буквенно-цифровой. Вторая часть получает ваш буквенно-цифровой с пробелом. {0,9} допускает от 0 до 9 вхождений второй части. Это даст вам 1-10
Я думаю, что самый простой способ это пойти с \w[\s\w]{0,9}
Обратите внимание, что \w для [A-Za-z0-9_] так что замени его [A-Za-z0-9] если ты не хочешь _ Обратите внимание, что \s для любого белого символа, поэтому замените его если ты не хочешь других
Ниже, вероятно, наиболее семантически правильно:
(?=^[0-9a-zA-Z])(?=.*[0-9a-zA-Z]$)^[0-9a-zA-Z ]{1,10}$
Он утверждает, что первый и последний символы являются буквенно-цифровыми и что вся строка имеет длину от 1 до 10 символов (включая пробелы).
Я предполагаю, что место не разрешено в конце тоже.
^[a-zA-Z0-9](?:[a-zA-Z0-9 ]{0,8}[a-zA-Z0-9])?$
или с классами символов posix:
^[[:alnum:]](?:[[:alnum:] ]{0,8}[[:alnum:]])?$
Попробуй это: [0-9a-zA-Z][0-9a-zA-Z ]{0,9}
{x,y} синтаксис означает между x а также y раз включительно. {x,} означает по крайней мере x раз.