Рабочий узел Kubernetes не готов из-за того, что плагин CNI не инициализирован
Я использую kind для запуска тестового кластера Kubernetes на моем локальном Macbook.
Я нашел один из узлов со статусом NotReady:
$ kind get clusters
mc
$ kubernetes get nodes
NAME STATUS ROLES AGE VERSION
mc-control-plane Ready master 4h42m v1.18.2
mc-control-plane2 Ready master 4h41m v1.18.2
mc-control-plane3 Ready master 4h40m v1.18.2
mc-worker NotReady <none> 4h40m v1.18.2
mc-worker2 Ready <none> 4h40m v1.18.2
mc-worker3 Ready <none> 4h40m v1.18.2
Единственное интересное в kubectl describe node mc-worker заключается в том, что плагин CNI не инициализирован:
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
MemoryPressure False Tue, 11 Aug 2020 16:55:44 -0700 Tue, 11 Aug 2020 12:10:16 -0700 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Tue, 11 Aug 2020 16:55:44 -0700 Tue, 11 Aug 2020 12:10:16 -0700 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Tue, 11 Aug 2020 16:55:44 -0700 Tue, 11 Aug 2020 12:10:16 -0700 KubeletHasSufficientPID kubelet has sufficient PID available
Ready False Tue, 11 Aug 2020 16:55:44 -0700 Tue, 11 Aug 2020 12:10:16 -0700 KubeletNotReady runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady
message:Network plugin returns error: cni plugin not initialized
У меня есть 2 похожих кластера, и это происходит только в этом кластере.
поскольку kind использует локальный демон Docker для запуска этих узлов в качестве контейнеров, я уже пытался перезапустить контейнер (это должно быть эквивалентно перезагрузке узла).
Я подумал об удалении и воссоздании кластера, но должен быть способ решить эту проблему без повторного создания кластера.
Вот версии, которые я использую:
$ kind version
kind v0.8.1 go1.14.4 darwin/amd64
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"16+", GitVersion:"v1.16.6-beta.0", GitCommit:"e7f962ba86f4ce7033828210ca3556393c377bcc", GitTreeState:"clean", BuildDate:"2020-01-15T08:26:26Z", GoVersion:"go1.13.5", Compiler:"gc", Platform:"darwin/amd64"}
Server Version: version.Info{Major:"1", Minor:"18", GitVersion:"v1.18.2", GitCommit:"52c56ce7a8272c798dbc29846288d7cd9fbae032", GitTreeState:"clean", BuildDate:"2020-04-30T20:19:45Z", GoVersion:"go1.13.9", Compiler:"gc", Platform:"linux/amd64"}
Как решить эту проблему?
3 ответа
Наиболее вероятная причина:
На виртуальной машине-докере не хватает ресурса, и она не может запустить CNI на этом узле.
Вы можете покопаться в виртуальной машине HyperKit, подключившись к ней:
Из оболочки:
screen ~/Library/Containers/com.docker.docker/Data/vms/0/tty
Если по какой-то причине это не сработает:
docker run -it --rm --privileged --pid=host alpine nsenter -t 1 -m -u -n -i sh
Попав в виртуальную машину:
# ps -Af
# free
# df -h
...
Затем вы всегда можете обновить настройку в пользовательском интерфейсе докера:
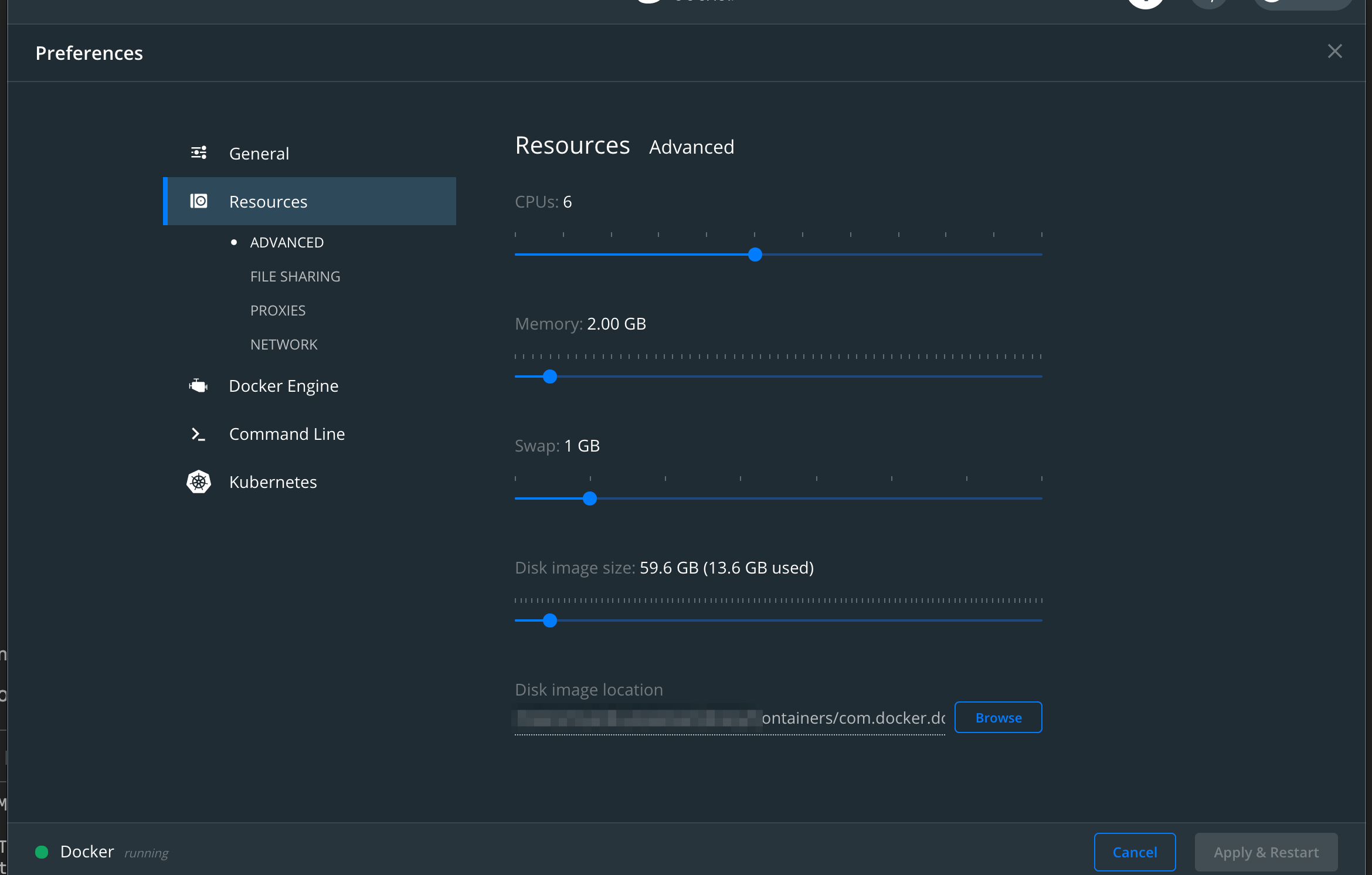
Наконец, ваш узел все-таки работает в контейнере. Итак, вы можете подключиться к этому контейнеру и посмотреть, чтоkubelet ошибки, которые вы видите:
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6d881be79f4a kindest/node:v1.18.2 "/usr/local/bin/entr…" 32 seconds ago Up 29 seconds 127.0.0.1:57316->6443/tcp kind-control-plane
docker exec -it 6d881be79f4a bash
root@kind-control-plane:/# systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/kind/systemd/kubelet.service; enabled; vendor preset: enabled)
Drop-In: /etc/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since Wed 2020-08-12 02:32:16 UTC; 35s ago
Docs: http://kubernetes.io/docs/
Main PID: 768 (kubelet)
Tasks: 23 (limit: 2348)
Memory: 32.8M
CGroup: /docker/6d881be79f4a8ded3162ec6b5caa8805542ff9703fabf5d3d2eee204a0814e01/system.slice/kubelet.service
└─768 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet
/config.yaml --container-runtime=remote --container-runtime-endpoint=/run/containerd/containerd.sock --fail-swap-on=false --node-ip= --fail-swap-on=false
...
✌️
Остановите и отключите apparmor и перезапустите службу containerd на этом узле, чтобы решить вашу проблему :~# systemctl stop apparmor :~# systemctl отключить apparmor [email protected][email protected][email protected] :~# systemctl перезапустить containerd.service
Я столкнулся с таким сценарием. Мастер готов, а статус рабочего узла - нет. После некоторого расследования я обнаружил, что /opt/cni/bin пуст - нет сетевого плагина для хостов моих рабочих узлов. Таким образом, я установил этот "kubernetes-cni.x86_64" и перезапустил службу kubelet. Это решило статус "NotReady" моих рабочих узлов.