Задача mlr3$feature_names - это переупорядочивание переменных в R?
Итак, моя проблема в том, что когда у меня есть фрейм данных, а затем я создаю задачу, используя mlr3с task$feature_namesфункция, она возвращает переменные в алфавитном порядке или в (своего рода) неправильном числовом порядке, тогда как я хотел бы сохранить порядок, в котором имена функций отображаются во фрейме данных. Ниже я привел 2 примера того, что я имею в виду. 1-й пример представляет собой (несколько) числовой пример, а 2-й пример - алфавитный.
Пример 1 (числовой):
library(mlr3)
# Set Values
n <- 10 # No of rows
p <- 10 # No of cols
e <- rnorm(n) # used for noise
b <- 10
# Create matrix of values
xValues <- matrix(rnorm(n*p), nrow=n) # Create matrix wt 3 columns
colnames(xValues)<- paste0(1:p) # Name columns
df <- data.frame(xValues) # Create dataframe
# Equation
y <- (b + b*df$X1 - b*df$X2 + (b*df$X3)*(b*df$X2) + e) # Equation
# Adding y to df
df$y <- y
# mlr3 TASK
test_T = TaskRegr$new(id = "test", backend = df, target = "y")
test_T$feature_names
Итак, в приведенном выше примере я создаю некоторые данные (например, от X1 до X11), а затем создаю mlr3задача. Однако когда я бегуtest_T$feature_names он возвращает это:
[1] "X1" "X10" "X2" "X3" "X4" "X5" "X6" "X7" "X8" "X9"
Итак, из-за ведущей 1 в X10, mlr3 считает, что X10 должен появиться перед X2.
Пример 2 (по алфавиту):
library(mlr3)
a <-rnorm(10)
b <-rnorm(10)
ab <-rnorm(10)
ba <-rnorm(10)
c <-rnorm(10)
myData <- data.frame(a, b, ab, ba, c)
t_T = TaskRegr$new(id = "test", backend = myData, target = "c")
t_T$feature_names
Итак, на этот раз порядок переменных в моем фрейме данных описывается следующим образом: myData(то есть a, b, ab, ba, c). Однако когда я бегуt_T$feature_names, он возвращает это:
[1] "a" "ab" "b" "ba"
Он изменил порядок на алфавитный. Я не уверен, намеренно это или недосмотрmlr3... но есть ли способ извлечь имена функций из mlr3создал задачу, где не меняет порядок имен переменных?
Я все еще застрял в этом вопросе, есть ли у кого-нибудь предложения?
РЕДАКТИРОВАТЬ: я добавляю (плохой) графический пример, чтобы проиллюстрировать проблему. Итак, продолжая численный пример, если бы я хотел создать график стиля тепловой карты, но используя$feature_names чтобы получить имена функций, я получаю что-то вроде этого:
nam <- test_T$feature_names
var_int2 = df %>% as_tibble %>%
mutate(var_num1 = 1:length(nam)) %>%
pivot_longer(cols = 1:length(nam),
values_to = 'values') %>%
mutate(var_num2 = rep(1:length(nam), length(nam)),
alpha_imp = as.integer(var_num1 == var_num2),
alpha_int = 1 - alpha_imp)
p <- ggplot(data = var_int2,
mapping = aes(x = var_num1, y = var_num2)) +
scale_x_continuous(breaks = 1:length(nam), labels = nam, position = "top") +
scale_y_reverse(breaks = 1:length(nam), labels = nam) +
geom_raster(aes(fill = y),
alpha = var_int2$alpha_int)
p
В результате получится что-то вроде этого:
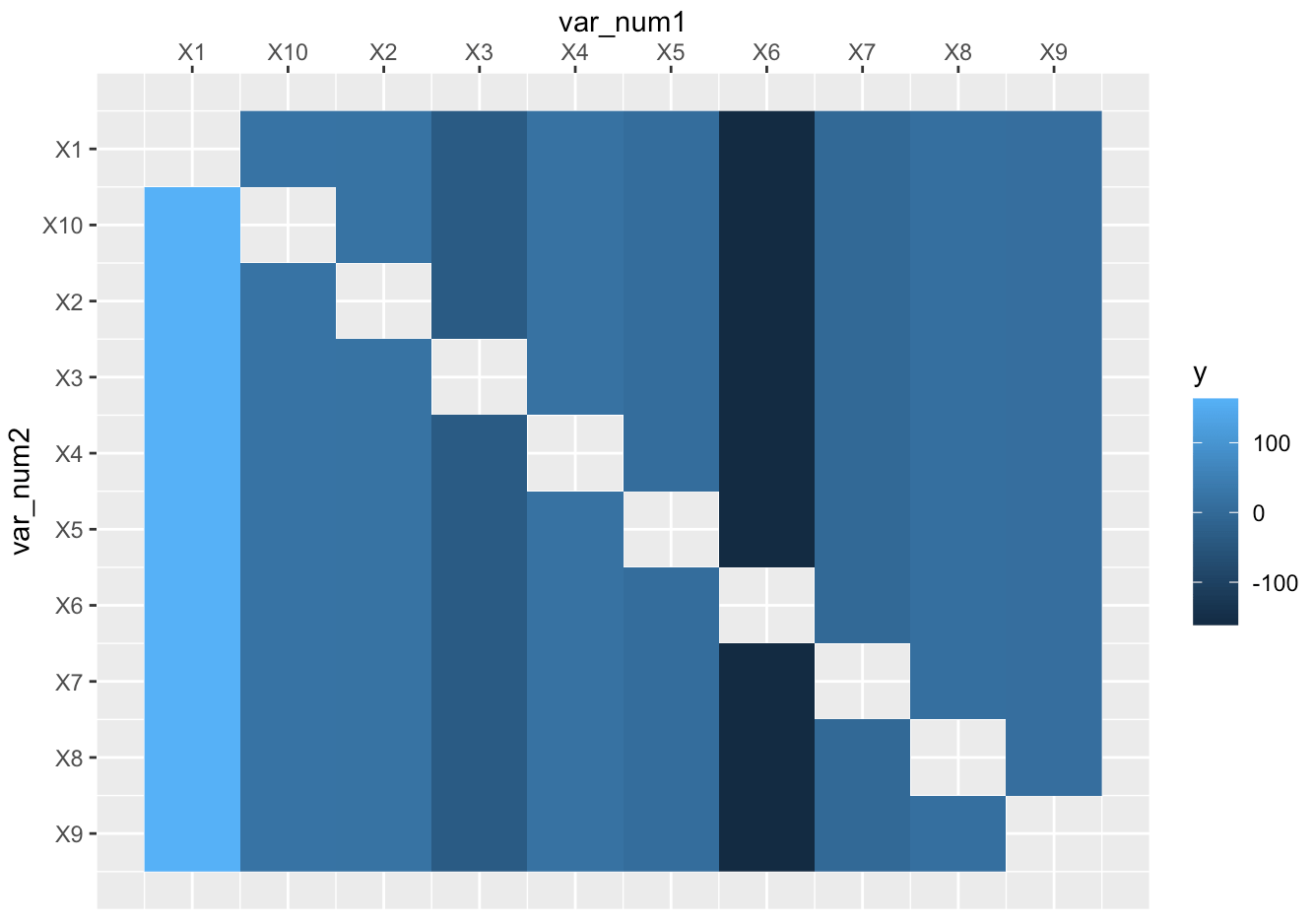
Как можно видеть, он отображает X10 между X1 и X2. В идеале я хотел бы сохранить порядок функций в том порядке, в котором они появляются во фрейме данных. Я знаю, что могут быть другие способы изменить порядок сюжета, однако я полагался на$feature_namesв большой функции построения графиков, которую я создал. Изначально я использовалgetTaskFeatureNames(task) от mlr, который сохраняет имена функций в исходном порядке... но я недавно обновился до mlr3 и это, кажется, меняет порядок.
2 ответа
Если вы можете привести пример или вариант использования, в котором важен порядок функций, мы можем попытаться сохранить его.
У нас было короткое обсуждение, и мы не считаем это ошибкой. Вы также можете просмотреть данные в задаче и получить имена столбцов.
task = tsk("mtcars")
task$feature_names
# [1] "am" "carb" "cyl" "disp" "drat" "gear" "hp" "qsec" "vs" "wt"
colnames(task$data())
# [1] "mpg" "am" "carb" "cyl" "disp" "drat" "gear" "hp" "qsec" "vs" "wt"
Обратите внимание, что это содержит целевой столбец. Кроме того, он может замедлиться, если вы используете другой сервер, а затем простоdata.table потому что данные будут извлечены, тогда как $feature_names не зависит от данных.
Подводя итог, можно было бы использовать это решение порядка важности
setdiff(colnames(task$data()), task$target_names)