итерация, вычисление и объединение двух списков с несколькими кортежами
Я работаю с набором данных проекции координат, который содержит данные x,y,z (432 строки csv с заголовками X Y Z, не прикреплены). Я хочу импортировать этот набор данных, рассчитать новую сетку на основе ввода данных пользователем, а затем начать выполнение некоторой статистики по точкам, которые попадают в новую сетку. Я дошел до того, что у меня есть два списка (raw_lst с 431(x,y,z) и grid_lst с 16(x,y) (вызов n,e)), но когда я пытаюсь выполнить итерацию, чтобы начать вычисление среднего и плотность для новой сетки все разваливается. Я пытаюсь вывести окончательный список, содержащий значения x и y grid_lst, а также вычисленные средние значения z и плотности.
Я искал библиотеки numpy и scipy, думая, что у них, возможно, уже было что-то делать то, что я хочу, но не смог ничего найти. Дайте мне знать, если у кого-нибудь из вас есть какие-нибудь мысли.
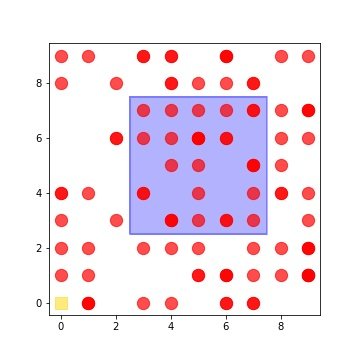
sample_xyz_reddot_is_newgrid_pictoral_presentation
import pandas as pd
import math
df=pd.read_csv("Sample_xyz.csv")
N=df["X"]
E=df["Y"]
Z=df["Z"]
#grid = int(input("Specify grid value "))
grid = float(0.5) #for quick testing the grid value is set to 0.5
#max and total calculate the input area extents
max_N = math.ceil(max(N))
max_E = math.ceil(max(E))
min_E = math.floor(min(E))
min_N = math.floor(min(N))
total_N = max_N - min_N
total_E = max_E - min_E
total_N = int(total_N/grid)
total_E = int(total_E/grid)
#N_lst and E_lst calculate the mid points based on the input file extents and the specified grid file
N_lst = []
n=float(max_N)-(0.5*grid)
for x in range(total_N):
N_lst.append(n)
n=n-grid
E_lst = []
e=float(max_E)-(0.5*grid)
for x in range(total_E):
E_lst.append(e)
e=e-grid
grid_lst = []
for n in N_lst:
for e in E_lst:
grid_lst.append((n,e))
#converts the imported dataframe to list
raw_lst = df.to_records(index=False)
raw_lst = list(raw_lst)
#print(grid_lst) # grid_lst is a list of 16 (n,e) tuples for the new grid coordinates.
#print(raw_lst) # raw_lst is a list of 441 (n,e,z) tuples from the imported file - calling these x,y,z.
#The calculation where it all falls apart.
t=[]
average_lst = []
for n, e in grid_lst:
for x, y, z in raw_lst:
if n >= x-(grid/2) and n <= x+(grid/2) and e >= y-(grid/2) and e <= y+(grid/2):
t.append(z)
average = sum(t)/len(t)
density = len(t)/grid
average_lst = (n,e,average,density)
print(average_lst)
# print("The length of this list is " + str(len(average_lst)))
# print("The length of t is " + str(len(t)))
ОБРАЗЕЦ КОДА ДЛЯ РАБОТЫ
import random
grid=5
raw_lst = [(random.randrange(0,10), random.randrange(0,10), random.randrange(0,2))for i in range(100)]
grid_lst = [(2.5,2.5),(2.5,7.5),(7.5,2.5),(7.5,7.5)]
t=[]
average_lst = []
for n, e in grid_lst:
for x, y, z in raw_lst:
if n >= x-(grid/2) and n <= x+(grid/2) and e >= y-(grid/2) and e <= y+(grid/2):
t.append(z)
average = sum(t)/len(t)
density = len(t)/grid
average_lst = (n,e,average,density)
print(average_lst)
1 ответ
Некоторые советы
- при работе с массивами используйте numpy. Он имеет больше функций
- при работе с сетками часто удобнее использовать координаты x, координаты y как отдельные массивы
Комментарии к решению
- Очевидно, что у вас есть сетка, а точнее ящик grd_lst. Мы генерируем его как numpy meshgrid (gx,gy)
- у вас есть ряд очков raw_list. Мы генерируем каждый элемент в виде одномерных массивов numpy
- вы хотите выбрать r_points, которые находятся в g_box. Для этого мы используем процентную формулу: tx = (rx-gxMin)/(gxMax-gxMin)
- если tx, ty находятся в пределах [0..1], мы сохраняем индекс
- в качестве промежуточного результата мы получаем все индексы raw_list, которые находятся в g_box
- с этим индексом вы можете извлекать элементы raw_list, которые находятся в g_box, и делать некоторую статистику
- обратите внимание, что я пропустил z-координату. Вам придется улучшить это решение.
-
import numpy as np
from matplotlib import pyplot as plt
import matplotlib.colors as mclr
from matplotlib import cm
f10 = 'C://gcg//picStack_10.jpg' # output file name
f20 = 'C://gcg//picStack_20.jpg' # output file name
def plot_grid(gx,gy,rx,ry,Rx,Ry,fOut):
fig = plt.figure(figsize=(5,5))
ax = fig.add_subplot(111)
myCmap = mclr.ListedColormap(['blue','lightgreen'])
ax.pcolormesh(gx, gy, gx, edgecolors='b', cmap=myCmap, lw=1, alpha=0.3)
ax.scatter(rx,ry,s=150,c='r', alpha=0.7)
ax.scatter(Rx,Ry,marker='s', s=150,c='gold', alpha=0.5)
ax.set_aspect('equal')
plt.savefig(fOut)
plt.show()
def get_g_grid(nx,ny):
ix = 2.5 + 5*np.linspace(0,1,nx)
iy = 2.5 + 5*np.linspace(0,1,ny)
gx, gy = np.meshgrid(ix, iy, indexing='ij')
return gx,gy
def get_raw_points(N):
rx,ry,rz,rv = np.random.randint(0,10,N), np.random.randint(0,10,N), np.random.randint(0,2,N), np.random.uniform(low=0.0, high=1.0, size=N)
return rx,ry,rz,rv
N = 100
nx, ny = 2, 2
gx,gy = get_base_grid(nx,ny)
rx,ry,rz,rv = get_raw_points(N)
plot_grid(gx,gy,rx,ry,0,0,f10)
def get_the_points_inside(gx,gy,rx,ry):
#----- run throuh the g-grid -------------------------------
nx,ny = gx.shape
N = len(rx)
index = []
for jx in range(0,nx-1):
for jy in range(0,ny-1):
#--- run through the r_points
for jr in range(N):
test_x = (rx[jr]-gx[jx,jy]) / (gx[jx+1,jy] - gx[jx,jy])
test_y = (ry[jr]-gy[jx,jy]) / (gy[jx,jy+1] - gy[jx,jy])
if (0.0 <= test_x <= 1.0) and (0.0 <= test_y <= 1.0):
index.append(jr)
return index
index = get_the_points_inside(gx,gy,rx,ry)
Rx, Ry, Rz, Rv = rx[index], ry[index], rz[index], rv[index]
plot_grid(gx,gy,rx,ry,Rx,Ry,f20)