Профилирование памяти в искровом режиме DirectRunner
Я выполняю профилирование памяти с помощью YourKit и, чтобы упростить задачу для приложения Spark, я запускаю приложение в режиме DirectRunner. Машина, на которой я тестирую, имеет 32 ядра. Захваченный снимок выглядит так:
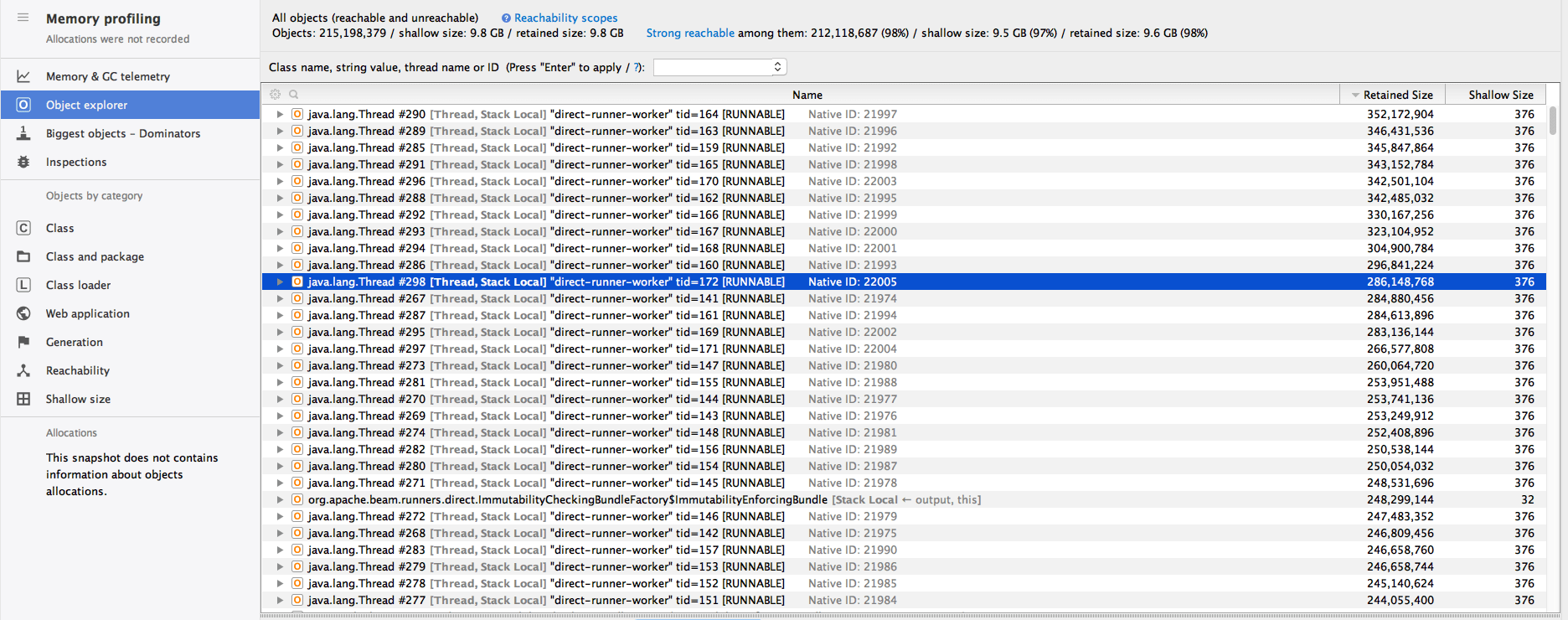
"Прямой-исполнитель-рабочий" имеет 32 потока, и мне кажется, что я ошибочно полагал, что прямой исполнитель занимает только один поток. У меня вопрос: а не должно ли быть ограничений на количество потоков распараллеливания? В моментальном снимке поток занимает от 250 до 350 МБ, и это неизбежно взорвется.
Другой вопрос: я не уверен, следует ли мне следовать http://spark.apache.org/developer-tools.html в моем случае, документация, похоже, предназначена для приложения, работающего с SparkCluster, но поскольку я использую DirectRunner (для целей отладки) тогда, может быть, все, что я делаю, достаточно хорошо - есть ли у кого-нибудь опыт в этом?
Любые указатели приветствуются!:)
PS: мой ум ошеломлен созданием 215 миллионов объектов, но это должно уменьшиться с количеством потоков. Однако ~6 миллионов объектов на поток кажутся много.