Данные перекрытия CUDA не работают
Использование пар для перекрытия передачи данных с выполнением ядра не работает в моей системе.
Здравствуйте, я хочу использовать перекрывающиеся вычисления и передачи данных в CUDA, но я не могу. Справочный документ NVIDIA гласит, что при использовании потоков возможны перекрывающиеся вычисления и передача данных. но моя система не работает Пожалуйста, помогите мне.
Моя система ниже
- ОС: Windows 7 64bit
- CUDA: версия 5.0.7
- Комплект разработчика: Visual studion 2008
- GPU: GTX 680
Я получаю профиль Посмотреть это нравится 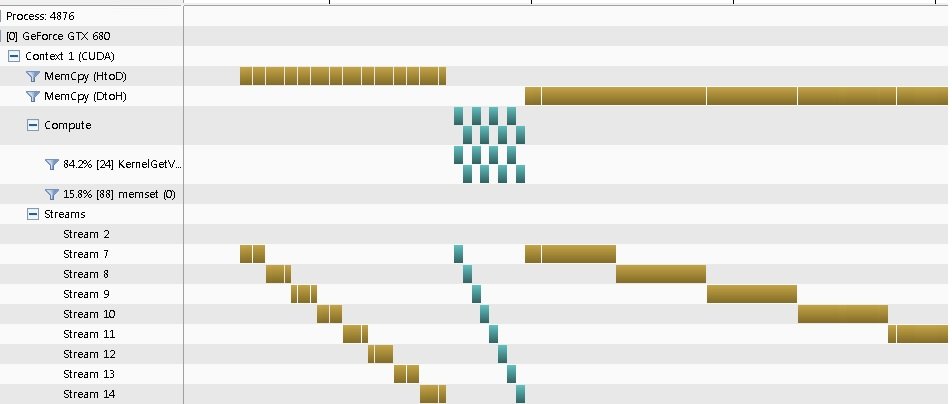
Я не получаю перекрытия, код ниже:
-new pinned memory
cudaHostAlloc((void **)&apBuffer, sizeof(BYTE)*lBufferSize,cudaHostAllocDefault);
-call function
//Input Data
for(int i=0;i<m_n3DChannelCnt*m_nBucket;++i)
{
cudaErrorChk_Return(cudaMemcpyAsync(d_ppbImg[i],ppbImg[i],sizeof(BYTE)*m_nImgWidth*m_nImgHeight,cudaMemcpyHostToDevice,m_pStream[i/m_nBucket]));
}
//Call Function
for(int i=0;i<m_n3DChannelCnt ;++i)
{KernelGetVis8uObjPhsPhs<<<nBlockCnt,nThreadCnt,0,m_pStream[i]>>>(d_ppbVis[i],d_ppbAvg[i],d_ppfPhs[i],d_ppfObj[i],d_ppbAmp[i]
,nTotalSize,d_ppstRefData[i],d_ppbImg[i*m_nBucket],d_ppbImg[i*m_nBucket+1],d_ppbImg[i*m_nBucket+2],d_ppbImg[i*m_nBucket+3]
,fSclFloatVis2ByteVis);
}
//OutputData
for(int i=0;i<m_n3DChannelCnt;++i)
{
if(ppbVis && ppbVis[i]) cudaErrorChk_Return(cudaMemcpyAsync(ppbVis[i],d_ppbVis[i],sizeof(BYTE)*m_nImgWidth*m_nImgHeight,cudaMemcpyDeviceToHost,m_pStream[i]));
if(ppbAvg && ppbAvg[i]) cudaErrorChk_Return(cudaMemcpyAsync(ppbAvg[i],d_ppbAvg[i],sizeof(BYTE)*m_nImgWidth*m_nImgHeight,cudaMemcpyDeviceToHost,m_pStream[i]));
if(ppfPhs && ppfPhs[i]) cudaErrorChk_Return(cudaMemcpyAsync(ppfPhs[i],d_ppfPhs[i],sizeof(float)*m_nImgWidth*m_nImgHeight,cudaMemcpyDeviceToHost,m_pStream[i]));
if(ppfObj && ppfObj[i]) cudaErrorChk_Return(cudaMemcpyAsync(ppfObj[i],d_ppfObj[i],sizeof(float)*m_nImgWidth*m_nImgHeight,cudaMemcpyDeviceToHost,m_pStream[i]));
if(ppbAmp && ppbAmp[i]) cudaErrorChk_Return(cudaMemcpyAsync(ppbAmp[i],d_ppbAmp[i],sizeof(BYTE)*m_nImgWidth*m_nImgHeight,cudaMemcpyDeviceToHost,m_pStream[i]));
}
Пожалуйста, дайте мне знать о том, почему профилировщик не показывает перекрытие выполнения ядра и передачи данных.
3 ответа
Вы должны призвать cudaMemcpyAsync() и ядро запускается в правильном порядке. До возможности вычисления 3.5 существовала только одна очередь для запуска операций на стороне устройства, и они не переупорядочивались. Объедините фазы "Call Function" и "OutputData" в нечто вроде
//Call Function and OutputData
for(int i=0;i<m_n3DChannelCnt ;++i)
{KernelGetVis8uObjPhsPhs<<<nBlockCnt,nThreadCnt,0,m_pStream[i]>>>(d_ppbVis[i],d_ppbAvg[i],d_ppfPhs[i],d_ppfObj[i],d_ppbAmp[i]
,nTotalSize,d_ppstRefData[i],d_ppbImg[i*m_nBucket],d_ppbImg[i*m_nBucket+1],d_ppbImg[i*m_nBucket+2],d_ppbImg[i*m_nBucket+3]
,fSclFloatVis2ByteVis);
if(ppbVis && ppbVis[i]) cudaErrorChk_Return(cudaMemcpyAsync(ppbVis[i],d_ppbVis[i],sizeof(BYTE)*m_nImgWidth*m_nImgHeight,cudaMemcpyDeviceToHost,m_pStream[i]));
if(ppbAvg && ppbAvg[i]) cudaErrorChk_Return(cudaMemcpyAsync(ppbAvg[i],d_ppbAvg[i],sizeof(BYTE)*m_nImgWidth*m_nImgHeight,cudaMemcpyDeviceToHost,m_pStream[i]));
if(ppfPhs && ppfPhs[i]) cudaErrorChk_Return(cudaMemcpyAsync(ppfPhs[i],d_ppfPhs[i],sizeof(float)*m_nImgWidth*m_nImgHeight,cudaMemcpyDeviceToHost,m_pStream[i]));
if(ppfObj && ppfObj[i]) cudaErrorChk_Return(cudaMemcpyAsync(ppfObj[i],d_ppfObj[i],sizeof(float)*m_nImgWidth*m_nImgHeight,cudaMemcpyDeviceToHost,m_pStream[i]));
if(ppbAmp && ppbAmp[i]) cudaErrorChk_Return(cudaMemcpyAsync(ppbAmp[i],d_ppbAmp[i],sizeof(BYTE)*m_nImgWidth*m_nImgHeight,cudaMemcpyDeviceToHost,m_pStream[i]));
}
Вы сможете перекрывать запуск ядра только первой или последней копией памяти, так как у вас есть пять cudaMemcpyAsync() звонки внутри потока, которые снова не переупорядочиваются. Выделите все пять массивов непрерывно в памяти, чтобы вы могли передавать их одним cudaMemcpyAsync(),
Однако в целом я замечаю, что передача данных занимает гораздо больше времени, чем ядро, поэтому перекрывающиеся вычисления и копирование обеспечат лишь незначительное ускорение в вашем случае.
Возможно, вы захотите проверить, работает ли ваш код должным образом (т.е. с перекрытием) в LINUX. Я только что столкнулся с той же проблемой и обнаружил, что в WINDOWS могут быть некоторые проблемы (либо в драйвере NVIDIA, либо в самой Windows), которые мешают перекрытию потоковой передачи CUDA.
Вы можете попробовать и проверить, работает ли пример "simpleStreams" в SDK с перекрытием на вашем компьютере. В моем случае "simpleStream", работающий в Windows, вообще не перекрывается, но отлично работает в Linux. Если быть точным, я использую CUDA 5.0 + VS2010 на Fermi GTX570.
TL;DR: проблема вызвана опцией задержки WDDM TDR в Nsight Monitor! Если установлено значение false, проблема появляется. Вместо этого, если вы установите значение задержки TDR на очень большое число, а для опции "enabled" установлено значение true, проблема исчезнет.
Читайте ниже о других (более старых) шагах, которые следовали до тех пор, пока я не пришел к решению выше, и некоторых других возможных причинах.
Я только недавно смог в основном решить эту проблему! Это специфично для окон и аэро, я думаю. Пожалуйста, попробуйте эти шаги и опубликуйте свои результаты, чтобы помочь другим! Я попробовал это на GTX 650 и GT 640.
Прежде чем что-либо предпринять, рассмотрите возможность использования встроенного gpu (в качестве дисплея) и дискретного gpu (для вычислений), поскольку существуют определенные проблемы с драйвером nvidia для windows! Когда вы используете встроенный gpu, указанные драйверы загружаются не полностью, поэтому многие ошибки устраняются. Также во время работы поддерживается отзывчивость системы!
- Убедитесь, что проблема параллелизма не связана с другими проблемами, такими как старые драйверы (в том числе версия BIOS), неправильный код, неработоспособное устройство и т. Д.
- Перейти к компьютеру> свойства
- Выберите дополнительные настройки системы на левой стороне
- Перейти на вкладку "Дополнительно"
- В настройках производительности нажмите
- На вкладке "Визуальные эффекты" выберите маркер "настроить для лучшей производительности".
Это отключит аэро и почти все визуальные эффекты. Если эта конфигурация работает, вы можете попробовать включить один за другим поля для визуальных эффектов, пока не найдете точную, которая вызывает проблемы!
Кроме того, вы можете:
- Щелкните правой кнопкой мыши на рабочем столе, выберите персонализировать
- Выберите тему из основных тем, которые не имеют аэро.
Это также будет работать, как указано выше, но с включенными дополнительными визуальными параметрами. Для моих двух устройств этот параметр также работает, поэтому я сохранил его.
Пожалуйста, когда вы попробуете эти решения, вернитесь сюда и опубликуйте результаты!
Для меня это решило проблему в большинстве случаев (плиточный dgemm, который я сделал), но ОБРАТИТЕ ВНИМАНИЕ, что я все еще не могу правильно запустить "simpleStreams" и достичь параллелизма...
ОБНОВЛЕНИЕ: проблема полностью решена с новой установкой Windows!! Предыдущие шаги улучшили поведение в некоторых случаях, но новая установка решила все проблемы!
Я постараюсь найти менее радикальный способ решения этой проблемы, возможно, достаточно будет просто восстановить реестр.