Измените жесткий код на более гибкий, используя цикл Python for
Я пишу код для построения графиков. Я пишу с использованием жесткого кода, поэтому мой код недостаточно гибкий.
Я знаю, что можно использовать цикл for для решения проблем с жестким кодом. Но мои способности к Python недостаточно сильны.
Вот мой код.
df1 = df[df.cluster==0]
df2 = df[df.cluster==1]
df3 = df[df.cluster==2]
plt.scatter(df1.Age,df1['Income($)'],color='green')
plt.scatter(df2.Age,df2['Income($)'],color='red')
plt.scatter(df3.Age,df3['Income($)'],color='black')
В этом случае есть 3 кластера. Если cluster = 4, то нужно написать больше. df4 = ...
Могу ли я написать цикл for, например, этот
n = number of cluster
for i in range(n):
df(random) = df[df.cluster==i]
for j in range(n):
plt.scatter(df(n).Age,df(n)['Income($)'],color='RANDOM')
Мой вопрос в том, чтобы написать код всего в несколько строк, не используя жесткие коды.
3 ответа
Решение
Если вы ищете простое решение, это может быть оно. (Я повторно использовал ваш образец кода)
n = num_of_clusters
my_colors = ['green', 'red', 'black', ...]
for i in range(n):
df_i = df[df.cluster == i]
plt.scatter(df_i.Age, df_i['Income($)'], color=my_colors[i])
Одна возможность:
colors = ['green', 'red', 'black']
for i in range(3):
df_temp = df[df.cluster==i]
plt.scatter(df_temp.Age, df_temp['Income($)'], color=colors[i])
Это классическая групповая операция в pandas.
Взгляните на некоторые сообщения об использовании groupby. Ты мог бы...
- использовать
groupbyсоздавать группы на основе значения кластера - Используйте цикл for, чтобы перебрать группы и...
- поместите каждую группу в контейнер групп.
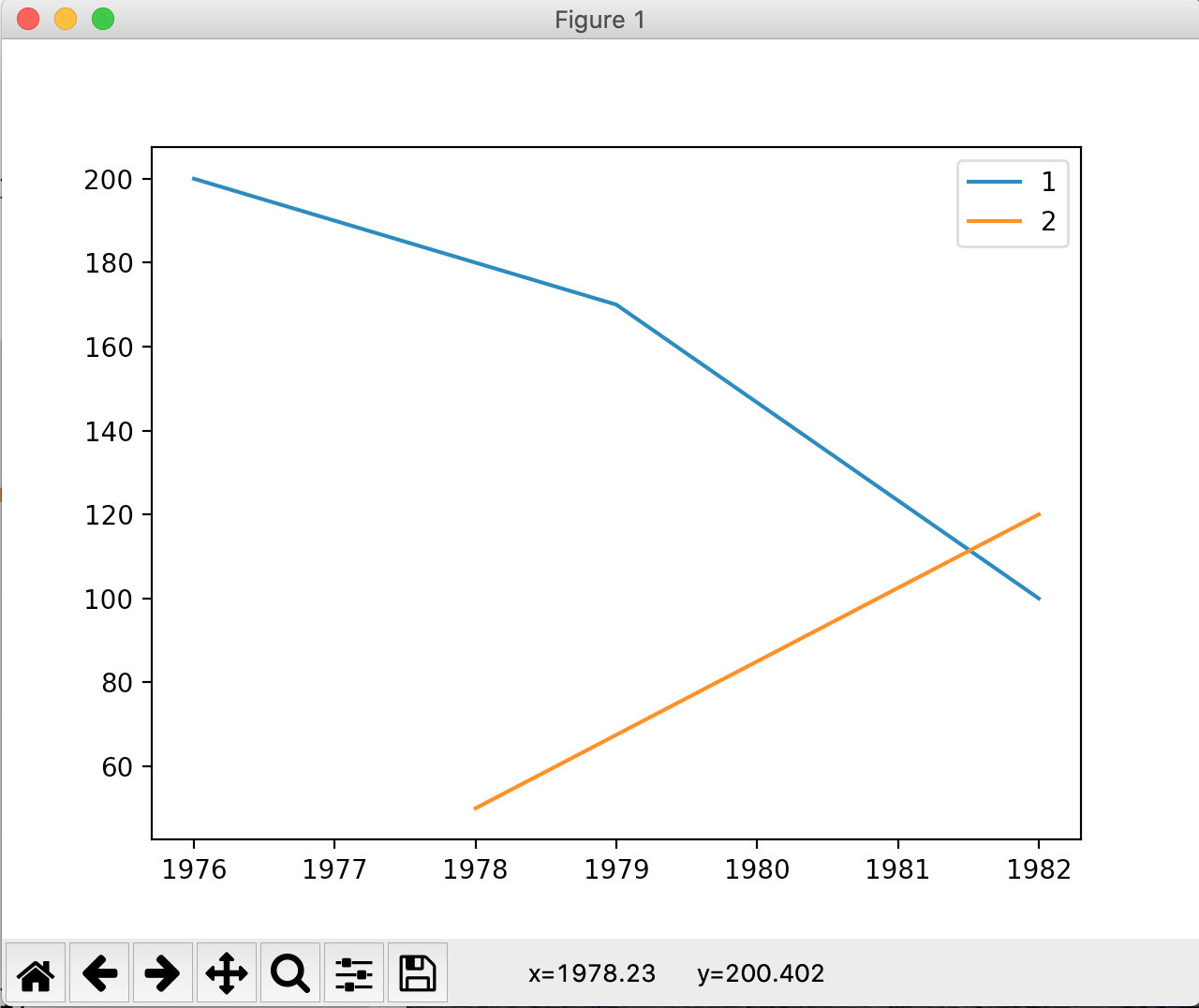
Вот пример использования groupby
In [57]: from matplotlib import pyplot as plt
In [58]: import pandas as pd
In [59]: data = {'year':[1976, 1979, 1982, 1978, 1982], 'income':[200, 170, 100,
...: 50, 120], 'cluster': [1, 1, 1, 2, 2]}
In [60]: df = pd.DataFrame(data)
In [61]: df
Out[61]:
year income cluster
0 1976 200 1
1 1979 170 1
2 1982 100 1
3 1978 50 2
4 1982 120 2
In [62]: for label, df in df.groupby('cluster'):
...: plt.plot(df['year'], df['income'], label=label)
...:
In [63]: plt.legend()
Out[63]: <matplotlib.legend.Legend at 0x7fe792601e80>
In [64]: plt.show()
производит: