Чтение данных из нескольких pubusb в один и тот же большой запрос
Этот вопрос больше связан с пониманием синтаксиса для подключения конвейера gcp в apache beam. вот как настроен мой текущий конвейер
options = dataflow_options(project_id=project_id, topic_name=topic_name, job_name=job_name)
p = apache_beam.Pipeline(options=options)
(p
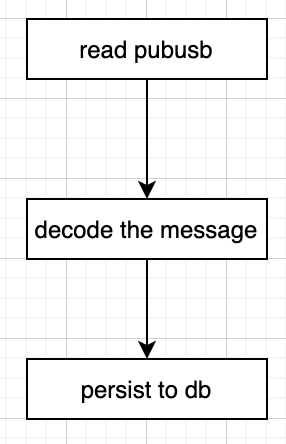
| 'read pubusb' >> apache_beam.io.ReadFromPubSub(topic=topic_path, with_attributes=True)
| 'decode the message' >> apache_beam.ParDo(mydecoder())
| 'persist to db' >> apache_beam.io.WriteToBigQuery(
output_table,
create_disposition=apache_beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
write_disposition=apache_beam.io.BigQueryDisposition.WRITE_APPEND
))
p.run()
Благодаря этому я могу создать конвейер, который выглядит так же.
Теперь, что я действительно хочу сделать (учитывая, что мой декодер такой же), это подключить несколько pubsub к одному и тому же декодеру, т.е.
Как я могу добиться этого в Apache Beam
Несколько вещей, которые я забыл упомянуть
- Все темы в основном представляют собой поток байтов.
- Нет общего ключа между данными при чтении из тем
- У каждой темы будет своя логика декодирования
Я смотрел на CoGroupby но для этого нужен общий ключ.
1 ответ
Решение
Используйте Свести объединить несколько PCollections в одно:
# Flatten takes a tuple of PCollection objects.
# Returns a single PCollection that contains all of the elements in the PCollection objects in that tuple.
merged = (
(pcoll1, pcoll2, pcoll3)
# A list of tuples can be "piped" directly into a Flatten transform.
| beam.Flatten())