Ошибка подключения Databricks из-за отсутствия файловой системы для схемы: abfss
У меня есть настройка Databricks Connect, чтобы я мог разрабатывать локально и получать полезности Intellij, в то же время используя мощь большого кластера Spark на Azure Databricks.
Когда я хочу читать или писать в Azure Data Lakespark.read.csv("abfss://blah.csv)
Я получаю следующее
xception in thread "main" java.io.IOException: No FileSystem for scheme: abfss
at org.apache.hadoop.fs.FileSystem.getFileSystemClass(FileSystem.java:2586)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2593)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:91)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2632)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2614)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:370)
at org.apache.hadoop.fs.Path.getFileSystem(Path.java:296)
at org.apache.spark.sql.execution.datasources.DataSource$$anonfun$org$apache$spark$sql$execution$datasources$DataSource$$checkAndGlobPathIfNecessary$1.apply(DataSource.scala:547)
at org.apache.spark.sql.execution.datasources.DataSource$$anonfun$org$apache$spark$sql$execution$datasources$DataSource$$checkAndGlobPathIfNecessary$1.apply(DataSource.scala:545)
at scala.collection.TraversableLike$$anonfun$flatMap$1.apply(TraversableLike.scala:241)
at scala.collection.TraversableLike$$anonfun$flatMap$1.apply(TraversableLike.scala:241)
at scala.collection.immutable.List.foreach(List.scala:392)
at scala.collection.TraversableLike$class.flatMap(TraversableLike.scala:241)
at scala.collection.immutable.List.flatMap(List.scala:355)
at org.apache.spark.sql.execution.datasources.DataSource.org$apache$spark$sql$execution$datasources$DataSource$$checkAndGlobPathIfNecessary(DataSource.scala:545)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:359)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:223)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:211)
at org.apache.spark.sql.DataFrameReader.csv(DataFrameReader.scala:618)
at org.apache.spark.sql.DataFrameReader.csv(DataFrameReader.scala:467)
Из этого у меня сложилось впечатление, что локально сослаться на Azure Data Lake не составит труда, поскольку код выполняется удаленно. Видимо ошибаюсь.
У кого-нибудь есть решение этой проблемы?
1 ответ
Причина проблемы заключалась в том, что я хотел иметь исходные коды Spark и иметь возможность выполнять рабочие нагрузки на Databricks. К сожалению, jar-файлы для подключения блоков данных не содержат исходников. Это означает, что мне нужно вручную импортировать их в проект. И вот загвоздка - в точности как написано в документации:
... If this is not possible, make sure that the JARs you add are at the front of the classpath. In particular, they must be ahead of any other installed version of Spark (otherwise you will either use one of those other Spark versions and run locally ...
Я так и сделал.
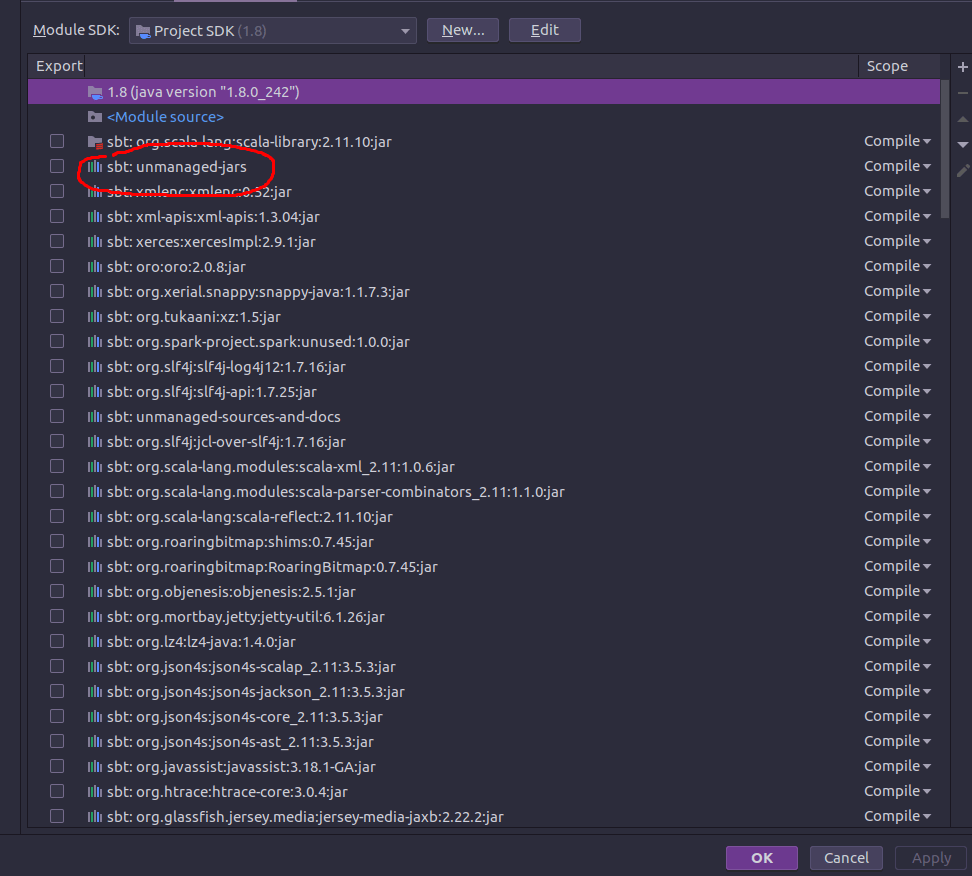
Теперь я могу испечь торт и съесть его!
Единственная проблема заключается в том, что если я добавлю новые зависимости, мне придется снова переупорядочить это.