Как создать вафельную диаграмму со словарем?
Я изучаю Python в лаборатории Jupyter, и у меня возникла проблема с вафельной диаграммой.
У меня есть следующий словарь, который я хочу отобразить в виде вафельной диаграммы:
import pandas as pd
import matplotlib.pyplot as plt
from pywaffle import Waffle
dic = {'Xemay':150,'Xedap':20,'Oto':180,'Maybay':80,'Tauthuy':135,'Xelua':5}
df = pd.DataFrame.from_dict(dic, orient='index')
plt.figure(FigureClass=Waffle,rows=5,values=dic,legend={'loc': 'upper left', 'bbox_to_anchor': (1, 1)})
plt.title('Số lượng xe bán được của một công ty')
plt.show()
Результат, однако, неожиданный:

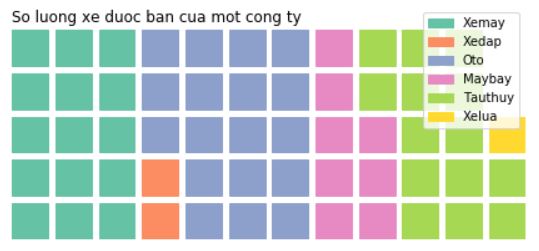
Вместо этого диаграмма должна выглядеть так. Что я делаю неправильно?

2 ответа
На самом деле, ваш код правильный, и Waffle правильно отображает ваши данные (увеличьте масштаб графика, чтобы увидеть квадраты...)
Однако для достижения желаемого результата вы должны поиграть с параметрами "строки" и "столбцы", которые определяют размеры вашей вафельной диаграммы.
nRows=5
countsPerBlock=10 # 1 block = 10 counts
plt.figure(FigureClass=Waffle,
rows=nRows,
columns=int(np.ceil(sum(dic.values())/nRows/countsPerBlock)),
values=dic,
legend={'loc': 'upper left', 'bbox_to_anchor': (1, 1.1)})
plt.show()
Обратите внимание, что внутри waffle применяется некоторое округление (см. Параметр rounding_rule), поэтому countsPerBlockне совсем верно, если вы сами не масштабируете данные. Чтобы точно воспроизвести желаемый результат, используйте следующий код:
nRows = 5
countsPerBlock = 10
keys = ['Xemay', 'Xedap', 'Oto', 'Maybay', 'Tauthuy', 'Xelua']
vals = np.array([150, 20, 180, 80, 135, 5])
vals = np.ceil(vals/countsPerBlock)
data = dict(zip(keys, vals))
plt.figure(FigureClass=Waffle,
rows=5,
values=data,
legend={'loc': 'upper left', 'bbox_to_anchor': (1, 1)})
plt.show()
В качестве альтернативы вы можете нормализовать ваши данные так, чтобы сумма значений была 100. В квадрате 5x20 один квадрат будет представлять 1% ваших данных.
# Create a dict of normalized data. There are plenty of
# ways to do this. Here is one approach:
keys = ['Xemay', 'Xedap', 'Oto', 'Maybay', 'Tauthuy', 'Xelua']
vals = np.array([150, 20, 180, 80, 135, 5])
vals = vals/vals.sum()*100
data = dict(zip(keys, vals))
nRows = 5
# ...

Эти 2 варианта кода могут решить мою проблему:
1. По материалам г-на Норманиуса:
nRows = 5
countsPerBlock = 10
keys = ['Xemay', 'Xedap', 'Oto', 'Maybay', 'Tauthuy', 'Xelua']
vals = np.array([150, 20, 180, 80, 135, 5])
vals = np.ceil(vals/countsPerBlock)
data = dict(zip(keys, vals))
plt.figure(FigureClass=Waffle,
rows=5,
values=data,
legend={'loc': 'upper left', 'bbox_to_anchor': (1, 1)})
plt.show()
2. Из того, что я узнал:
fig = plt.figure(
FigureClass=Waffle,
rows=5,
values=df[0]/10,
title={'label': 'So luong xe duoc ban cua mot cong ty', 'loc': 'left'},
labels=df.index.tolist(),
legend={'loc': 'lower right', 'bbox_to_anchor': (1, 0.5)}
)
plt.show()
Результат, как показано ниже: https://i.st ack.imgur.com/gojBU.jpg
{kind=link}