Как уменьшить размер контекста CUDA (многопроцессорная служба)
Я последовал за Робертом Crovella в пример о том, как использовать от Nvidia Multi-Process Service. Согласно документам:
2.1.2. Уменьшенное хранилище контекста на GPU
Без MPS каждый процесс CUDA с использованием графического процессора выделяет отдельное хранилище и ресурсы планирования на графическом процессоре. Напротив, сервер MPS выделяет одну копию хранилища GPU и ресурсов планирования, совместно используемых всеми его клиентами.
что я понимал как уменьшение размеров контекста каждого из процессов, что возможно, потому что они являются общими. Это увеличит свободную память графического процессора и, таким образом, позволит запускать больше процессов параллельно.
А теперь вернемся к примеру. Без MPS:
А с MPS:
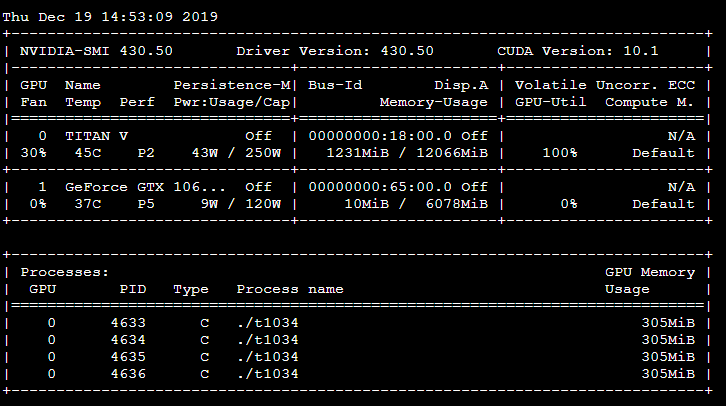
К сожалению, каждый процесс по-прежнему занимает практически такой же (~300 МБ) объем памяти. Разве это не противоречит документации? Есть ли способ уменьшить потребление памяти процессом?
2 ответа
К сожалению, я слишком настойчиво спрашивал, прежде чем проверять использование памяти на другой (до Volta) карте, и да, разница действительно есть. Позвольте мне просто опубликовать его здесь для справок в будущем, если кто-то еще наткнулся на эту проблему:
MPS выключен:
MPS на:
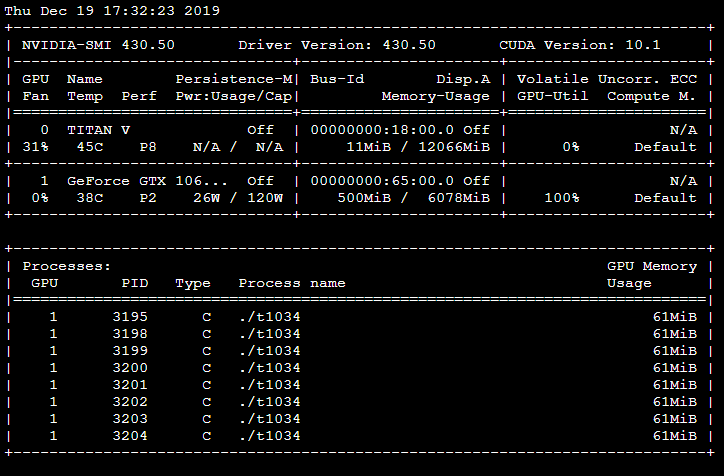
Действительно, как видно здесь, в архитектуре Volta вы можете видеть, как процессы взаимодействуют напрямую с графическим процессором, без сервера MPS посередине:
Клиенты Volta MPS отправляют работу непосредственно в GPU, минуя сервер MPS.
Это легко увидеть на вашем первом скриншоте, где t1034 процессы указаны как использующие GPU.
Напротив, в архитектурах до Volta клиентские процессы взаимодействуют с графическим процессором через сервер MPS. Это приводит к тому, что на последнем снимке экрана видно, что только процесс сервера MPS напрямую взаимодействует с графическим процессором.