В чем разница между терминами SSTable и LSM Tree
Используются ли эти два термина как взаимозаменяемые?
Я читал о том, как работает SSTable, и обычно в статьях просто упоминается LSM Tree. Однако, похоже, это одно и то же.
Когда я должен использовать один термин вместо другого?
4 ответа
Таблица сортированных строк (SSTable) - это файл на основе пары "ключ-значение", отсортированный по ключам.
Однако LSM Tree отличается:
В информатике дерево слияния со структурой журнала (или дерево LSM) представляет собой структуру данных с характеристиками производительности, которые делают ее привлекательной для предоставления индексированного доступа к файлам с большим объемом вставки, таким как данные журнала транзакций. Деревья LSM, как и другие деревья поиска, поддерживают пары ключ-значение. Деревья LSM поддерживают данные в двух или более отдельных структурах, каждая из которых оптимизирована для соответствующего базового носителя данных; данные синхронизируются между двумя структурами эффективно, в пакетном режиме.
https://en.wikipedia.org/wiki/Log-structured_merge-tree
Вероятно, одно из лучших объяснений SSTables и LSM-деревьев для смертных дано user121436 в его книге «Проектирование приложений, интенсивно использующих данные» . Эти структуры данных объясняются в главе 3 «Хранение и извлечение», страницы с 69 по 79. Это действительно отличное чтение, я бы порекомендовал всю книгу!
Нетерпеливые могут найти мой синопсис темы ниже
Все начинается с очень глупой базы данных ключей и значений, реализованной всего в двух функциях Bash:
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
Идея состоит в том, чтобы хранить данные в CSV-файле:
$ source database.sh
$ db_set 1 'Anakin Skywalker'
$ db_set 2 'Luke Skywalker'
$ db_set 1 'Darth Vader'
$ cat database
1,Anakin Skywalker
2,Luke Skywalker
1,Darth Vader
$ db_get 1
Darth Vader
Обратите внимание, что первое значение ключа
Эта база данных имеет довольно хорошую производительность записи:
Далее вводятся индексы. Индекс — это структура данных, полученная из самих данных. Поддержка индекса всегда влечет за собой дополнительные затраты, поэтому индексы всегда снижают производительность записи в пользу улучшения чтения.
Одним из самых простых возможных индексов является хэш-индекс. Этот индекс представляет собой не что иное, как словарь, содержащий байтовые смещения записей в базе данных. Продолжая предыдущий пример, предполагая, что каждый символ представляет собой один байт, хэш-индекс будет выглядеть так:
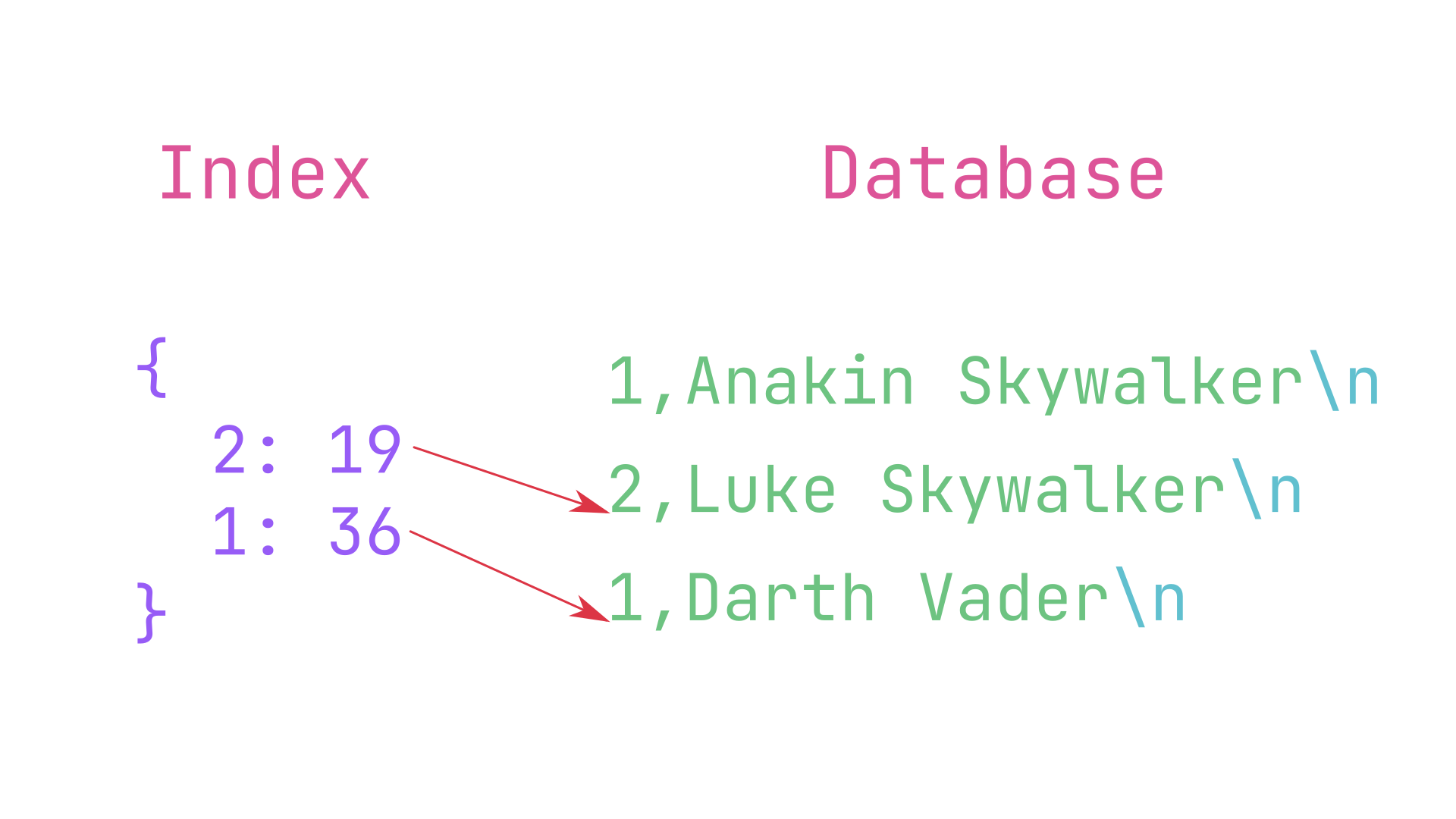
Всякий раз, когда вы записываете данные в базу данных, вы также обновляете индекс. Когда вы хотите прочитать значение для данного ключа, вы можете быстро найти смещение в файле базы данных. Имея смещение, вы можете использовать операцию «поиск», чтобы перейти прямо к местоположению данных. В зависимости от конкретной реализации индекса вы можете ожидать логарифмическую сложность как для чтения, так и для записи.
Затем Мартин занимается эффективностью хранения. Добавление данных в файл базы данных быстро исчерпывает место на диске. Чем меньше у вас отдельных ключей, тем неэффективнее этот механизм хранения только для добавления. Решение этой проблемы — уплотнение:
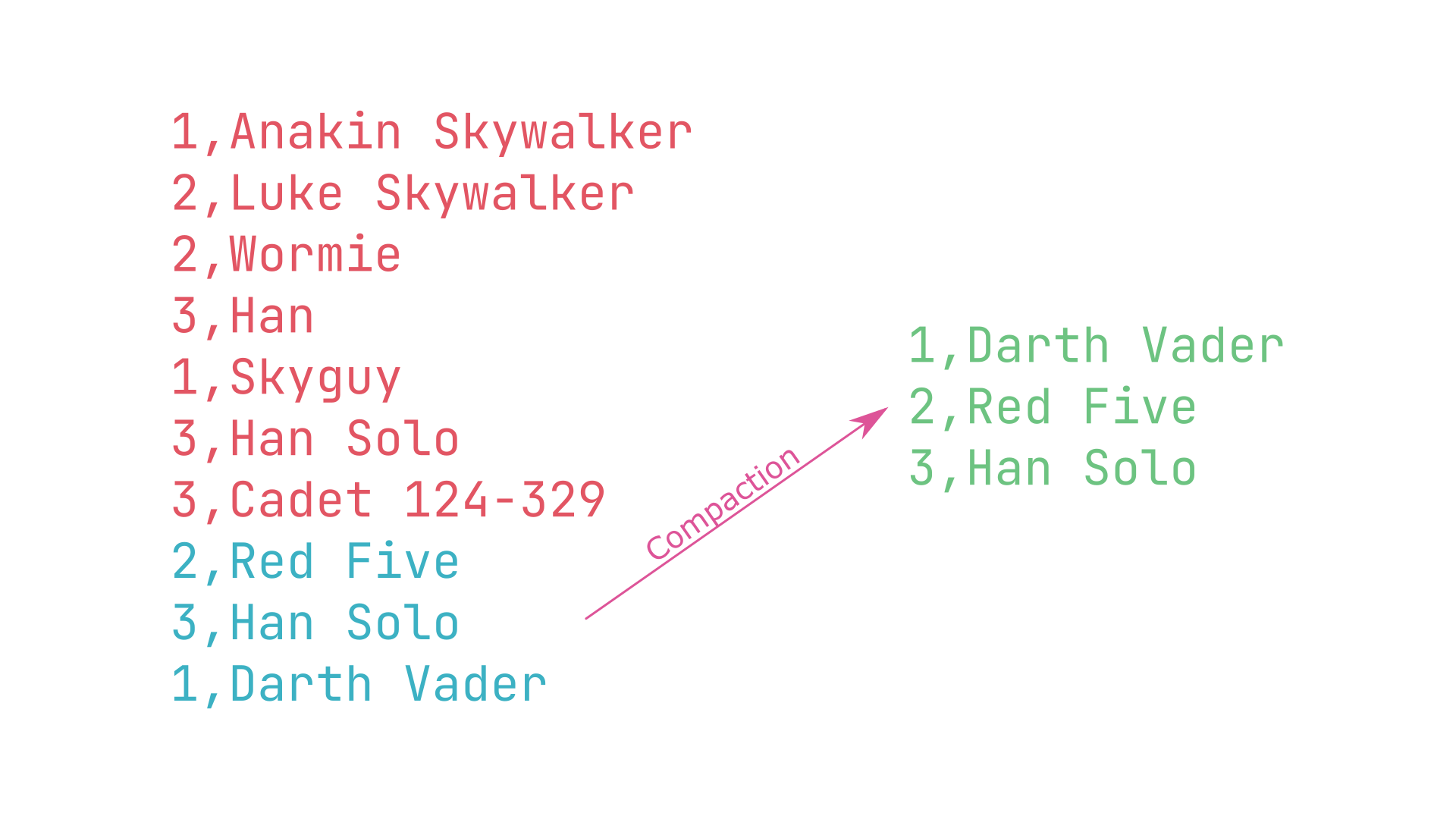
Когда файл базы данных увеличивается до определенного размера, вы прекращаете добавление к нему, создаете новый файл (называемый сегментом) и перенаправляете все операции записи в этот новый файл.
Сегменты неизменяемы в том смысле, что они никогда не используются для добавления новых данных. Единственный способ изменить сегмент — записать его содержимое в новый файл, возможно, с некоторыми промежуточными преобразованиями.
Таким образом, сжатие создает новые сегменты, содержащие только самые последние записи для каждого ключа. Еще одно возможное усовершенствование на этом этапе — объединение нескольких сегментов в один. Сжатие и слияние можно было бы, конечно, сделать в фоновом режиме. Старые сегменты просто выбрасываются.
Каждый сегмент, в том числе тот, в который выполняется запись, имеет свой собственный индекс. Итак, когда вы хотите найти значение для данного ключа, вы ищете эти индексы в обратном хронологическом порядке: от самого последнего к самому старому.
На данный момент у нас есть структура данных, имеющая следующие плюсы:
✔️ Последовательная запись, как правило, быстрее, чем случайная
✔️ Параллелизм легко контролировать, имея один процесс
записи ✔️ Восстановление после сбоя легко реализовать: просто последовательно считывайте все сегменты и сохраняйте смещения в индексе в памяти
✔️ Помощь по слиянию и сжатию чтобы избежать фрагментации данных
Однако есть и некоторые ограничения:
❗ Восстановление после сбоя может занять много времени, если сегменты большие и многочисленные
. ❗ Хэш-индекс должен помещаться в памяти. Реализация хеш-таблиц на диске намного сложнее
❗ Запросы диапазона (
Теперь, на этом фоне, давайте перейдем к SSTables и LSM-деревьям. Кстати, эти аббревиатуры означают соответственно «Таблицы сортированных строк» и «Деревья слияния с логарифмической структурой».
SSTables очень похожи на «базу данных», которую мы видели ранее. Единственное улучшение состоит в том, что мы требуем, чтобы записи в сегментах сортировались по ключу. Может показаться, что это нарушает возможность использования записи только для добавления, но для этого и нужны LSM-деревья. Мы увидим через мгновение!
SSTables имеют некоторые преимущества по сравнению с теми простыми сегментами, которые были у нас ранее:
✔️ Объединение сегментов более эффективно благодаря предварительной сортировке записей. Все, что вам нужно сделать, это сравнить «головы» сегментов на каждой итерации и выбрать самую низкую. Если несколько сегментов содержат один и тот же ключ, преимущество имеет значение из самого последнего сегмента. Этот компактный процесс слияния также содержит сортировку ключей.

✔️ С отсортированными ключами вам больше не нужно иметь каждый ключ в индексе. Если ключ
Последний вопрос: как вы получаете данные, отсортированные по ключу?
Идея, описанная Патриком О'Нилом и соавт. в их «Журнально-структурированном дереве слияния (LSM-дереве)» просто: существуют структуры данных в памяти, такие как красно-черные деревья или AVL-деревья, которые хорошо сортируют данные. Итак, вы разделили запись на два этапа. Сначала вы записываете данные в сбалансированное дерево в памяти. Во-вторых, вы сбрасываете это дерево на диск. На самом деле может быть более двух этапов, причем более глубокие из них больше и «медленнее», чем верхние (как показано в другом ответе ).
- Когда приходит запись, вы добавляете ее в сбалансированное дерево в памяти, называемое memtable.
- Когда memtable становится большим, он сбрасывается на диск. Он уже отсортирован, поэтому естественным образом создает сегмент SSTable.
- Тем временем записи обрабатываются свежей памятью.
- Чтения сначала ищутся в memtable, затем в сегментах, начиная с самого последнего и заканчивая самым старым.
- Сегменты время от времени уплотняются и объединяются в фоновом режиме, как описано ранее.
Схема не идеальна, она может страдать от внезапных сбоев: memtable, будучи структурой данных в памяти, теряется. Эту проблему можно решить, поддерживая другой файл только для добавления, который в основном дублирует содержимое memtable. Базе данных нужно только прочитать его после сбоя, чтобы воссоздать memtable.
Вот и все! Обратите внимание, что все проблемы простого хранилища только для добавления, описанные выше, теперь решены:
✔️ Теперь есть только один файл для чтения в случае сбоя: резервная копия
памяти
TLDR: SSTable — это хранилище ключей и значений с сортировкой по ключу только для добавления. LSM-дерево — это многоуровневая структура данных, основанная на сбалансированном дереве, которое позволяет SSTable существовать без разногласий по поводу одновременной сортировки и добавления.
Поздравляем, вы закончили это длинное чтение! Если вам понравилось объяснение, не забудьте проголосовать не только за этот пост, но и за некоторые user121436 . Помните: все кредиты достаются ему!
Это очень хорошо объясняется в методах хранения на основе LSM: обзорный документ в разделах 1 и 2.2.1.
LSM-дерево состоит из некоторых компонентов памяти и некоторых компонентов диска. По сути, SSTable - это всего лишь одна из реализаций дискового компонента для LSM-дерева.
SSTable объясняется в упомянутой выше статье:
SSTable (таблица сортированных строк) содержит список блоков данных и индексный блок; блок данных хранит пары ключ-значение, упорядоченные по ключам, а индексный блок хранит диапазоны ключей всех блоков данных.
На самом деле, термин LSM-дерево был официально введен Патриком О'Нилом в статье The Log-Structured Merge-Tree (LSM-Tree) , опубликованной в 1996 году.
Термин SSTable был придуман компанией Google Bigtable: распределенная система хранения структурированных данных в 2006 году .
Концептуально SSTable - это то, что обеспечивает индексирование механизма хранения на основе LSM Tree (в основном) (например, Lucene). Дело не в разнице, а в том, что в академических кругах понятия могут существовать давно, но как-то называться позже. Прохождение двух вышеупомянутых статей расскажет о многом.