Объединение таблиц при выборе того, из какого столбца извлекается
РЕДАКТИРОВАТЬ: Я использую версию 10.4.11-MariaDB. Вот код для создания графических таблиц
CREATE TABLE cats (
c_id INT PRIMARY KEY AUTO_INCREMENT,
c_name VARCHAR(255) NOT NULL UNIQUE
);
CREATE TABLE stock (
p_id INT PRIMARY KEY AUTO_INCREMENT,
c_id INT NOT NULL,
level DECIMAL(10,2) NOT NULL,
rating DECIMAL(10,2) NOT NULL DEFAULT 0.00
);
CREATE TABLE orders (
p_id INT NOT NULL,
sales INT NOT NULL
);
INSERT INTO cats (c_id, c_name) VALUES
(1, 'Boat'),
(2, 'Plane'),
(3, 'Car'),
(4, 'Bike');
INSERT INTO stock (p_id, c_id, level, rating) VALUES
(1, 1, 145.65, 41),
(2, 1, 915.06, 49),
(3, 1, 981.36, 64),
(4, 1, 727.81, 29),
(5, 2, 678.19, 51),
(6, 2, 808.13, 43),
(7, 2, 711.10, 17),
(8, 3, 503.34, 92),
(9, 4, 292.41, 19),
(10, 4, 15.67, 36);
INSERT INTO orders (p_id, sales) VALUES
(1, 2),
(2, 4),
(9, 4),
(3, 2),
(8, 4),
(6, 3),
(2, 1),
(10, 2),
(8, 3),
(1, 4);
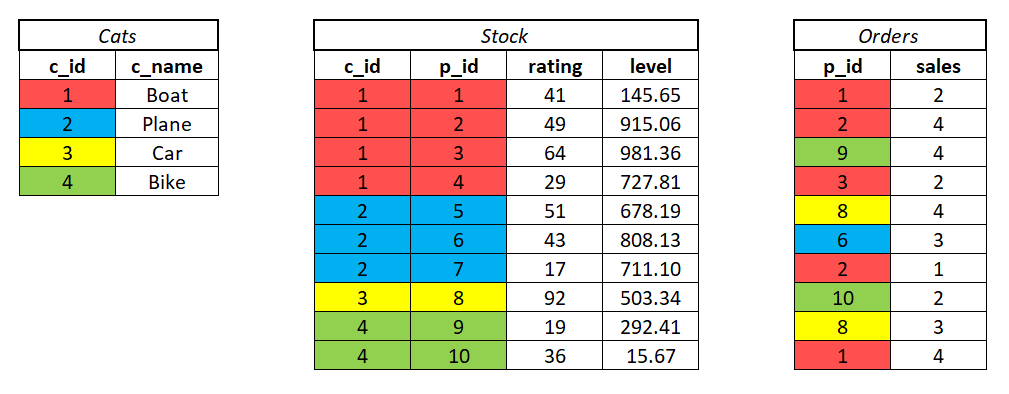
Я постараюсь быть очень внимательным с этим, поскольку я уже закрыл этот вопрос раньше, поэтому, пожалуйста, дайте мне знать, если мне нужно предоставить дополнительную информацию. Я начну с трех типовых таблиц, представляющих данные, с которыми я работаю, под названиемcats, stock, а также orders (все строчные буквы, если это важно).
Основная идея заключается в том, что каждый p_id имеет связанный rating, level, а также sales значение и p_id ценности можно классифицировать по их общим c_id. Каждыйp_id в stock уникален и принадлежит только одному c_id. Моя цель - создать таблицу, которая выполняет простые вычисления для агрегированияrating, level, а также sales столбцы, сгруппированные по c_name. Я обозначил каждый цветp_id чем c_idони принадлежат, чтобы упростить интерпретацию. Ниже приведен пример таблицы, которую я хотел бы составить:
РЕДАКТИРОВАТЬ: минимальный рейтинг для автомобиля должен быть 92, а не 8
Как видите, я хочу выделить четыре столбца:
- Каждое значение в
c_name - Количество
p_idценности, разделяющиеc_idсоответствующийc_name - Минимум
ratingлюбойp_idсодержится в каждой категории - Среднее
levelиз всехp_idзначения в каждой категории - Общее количество
salesдля всехp_idзначения в каждой категории
Я также хотел бы, чтобы внизу была строка с теми же вычислениями, выполненными для всего населения p_idзначения, игнорируя категории. То есть строка с суммой# of P_id's, минимальное значение min rating, среднее значение avg level, а сумма # of sales. Обратите внимание, чтоordersне включает все p_id в stock, и немного p_idзначения повторяются; важно, чтобы средние три ряда включали каждыйp_id только один раз, независимо от того, сколько раз они появляются в orders. Аналогичным образом, последний столбец должен суммировать продажиp_id ценности представлены и сгруппированы по категориям.
Я написал этот запрос, чтобы попытаться произвести это:
SELECT c_name, COUNT(p_id), MIN(rating), FORMAT(AVG(level),2), (SELECT SUM(sales) FROM orders JOIN stock USING(p_id))
FROM stock
JOIN cats USING(c_id)
GROUP BY c_name ASC WITH ROLLUP
Это дает почти то, что я хочу, за исключением проблемы с последним столбцом, где просто отображается общая сумма продаж для всех p_idценности вместе, независимо от категории. Я хотел вычислить этот столбец с помощью подзапроса в операторе SELECT, как если бы я вместо LEFT JOINorders с stock после присоединения stock с cats, каждый столбец будет выполнять свои вычисления только на основеp_id значения найдены в orders. Я думал, чтобы избежать этого, просто выбрав значения, которые мне нужны для последнего столбца, который мне нужен в подзапросе, но я изо всех сил пытаюсь понять, как я могу сгруппировать свои результаты по category_id, когда карта изproduct_id к category_id существует только внутри stock.
По сути, я думаю, что моя проблема сводится к тому, что я не знаю, как получить агрегированные данные в трех средних столбцах на основе p_id столбец в stock при этом убедитесь, что последний столбец берет только из orders. Кто-нибудь может дать мне совет?
Пожалуйста, дайте мне знать, если мне нужно уточнить детали.
2 ответа
Для ваших образцов данных это будет работать:
SELECT c.c_name, t.`# of p_ids`, t.`min rating`, t.`avg level`,
COALESCE(
SUM(o.sales),
(SELECT SUM(sales) FROM orders)
) `# of sales`
FROM (
SELECT c_id,
COUNT(p_id) `# of p_ids`,
MIN(rating) `min rating`,
FORMAT(AVG(level), 2) `avg level`
FROM stock
GROUP BY c_id WITH ROLLUP
) t
LEFT JOIN cats c ON c.c_id = t.c_id
LEFT JOIN stock s ON s.c_id = t.c_id
LEFT JOIN orders o ON o.p_id = s.p_id
GROUP BY t.c_id, c.c_name, t.`# of p_ids`, t.`min rating`, t.`avg level`
ORDER BY c.c_name IS NULL, c.c_id
Смотрите демо.
Полученные результаты:
| c_name | # of p_ids | min rating | avg level | # of sales |
| ------ | ---------- | ---------- | --------- | ---------- |
| Boat | 4 | 29 | 692.47 | 13 |
| Plane | 3 | 17 | 732.47 | 3 |
| Car | 1 | 92 | 503.34 | 7 |
| Bike | 2 | 19 | 154.04 | 6 |
| | 10 | 17 | 577.87 | 29 |
Вы можете получить желаемый результат, используя несколько агрегатов в виде табличных выражений; затем вы просто соединяете их вместе, чтобы получить полный результат.
Например:
select
x.c_name,
x.number_of_pids,
x.min_rating,
x.avg_level,
s.sum_sales
from (
select
c.c_id,
max(c.c_name) as c_name,
count(distinct s.p_id) as number_of_pids,
min(s.rating) as min_rating,
avg(s.level) as avg_level
from cats c
left join stock s on s.c_id = c.c_id
group by c.c_id
) x
left join (
select
s.c_id, sum(sales) as sum_sales
from stock s
left join orders o on o.p_id = s.p_id
group by s.c_id
) s on s.c_id = x.c_id