Как подключиться к IBM COS (Cloud Object Store) с помощью SPARK, Как решить проблему "Нет файловой системы для схемы: cos"
Я пытаюсь создать соединение с IBM COS (Cloud Object Store) с помощью Spark. Версия Spark = 2.4.4, Версия Scala = 2.11.12.
Я запускаю его локально с правильными учетными данными, но наблюдаю следующую ошибку - "Нет файловой системы для схемы: cos"
Я делюсь фрагментом кода вместе с журналом ошибок. Может ли кто-нибудь помочь мне решить эту проблему.
Заранее спасибо!
Фрагмент кода:
import com.ibm.ibmos2spark.CloudObjectStorage
import org.apache.spark.sql.SparkSession
object CosConnection extends App{
var credentials = scala.collection.mutable.HashMap[String, String](
"endPoint"->"ENDPOINT",
"accessKey"->"ACCESSKEY",
"secretKey"->"SECRETKEY"
)
var bucketName = "FOO"
var objectname = "xyz.csv"
var configurationName = "softlayer_cos"
val spark = SparkSession
.builder()
.appName("Connect IBM COS")
.master("local")
.getOrCreate()
spark.sparkContext.hadoopConfiguration.set("fs.stocator.scheme.list", "cos")
spark.sparkContext.hadoopConfiguration.set("fs.stocator.cos.impl", "com.ibm.stocator.fs.cos.COSAPIClient")
spark.sparkContext.hadoopConfiguration.set("fs.stocator.cos.scheme", "cos")
var cos = new CloudObjectStorage(spark.sparkContext, credentials, configurationName=configurationName)
var dfData1 = spark.
read.format("org.apache.spark.sql.execution.datasources.csv.CSVFileFormat").
option("header", "true").
option("inferSchema", "true").
load(cos.url(bucketName, objectname))
dfData1.printSchema()
dfData1.show(5,0)
}
ОШИБКА:
Exception in thread "main" java.io.IOException: No FileSystem for scheme: cos
at org.apache.hadoop.fs.FileSystem.getFileSystemClass(FileSystem.java:2586)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2593)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:91)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2632)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2614)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:370)
at org.apache.hadoop.fs.Path.getFileSystem(Path.java:296)
1 ответ
Эта проблема была решена путем сопоставления следующей зависимости стокатора с SPARK Version = 2.4.4, SCALA Version = 2.11.12
// https://mvnrepository.com/artifact/com.ibm.stocator/stocator
libraryDependencies += "com.ibm.stocator" % "stocator" % "1.0.24"
Убедитесь, что у вас есть stocator-1.0.24-jar-with-dependencies.jar во внешних библиотеках при сборке пакета
Также убедитесь, что вы передаете конечную точку как s3.us.cloud-object-storage.appdomain.cloudвместо https://s3.us.cloud-object-storage.appdomain.cloud
Вы можете собрать банку стокатора вручную и включить target/stocator-1.0.24-SNAPSHOT-IBM-SDK.jar jar в ClassPath (при необходимости) -
git clone https://github.com/SparkTC/stocator
cd stocator
git fetch
git checkout -b 1.0.24-ibm-sdk origin/1.0.24-ibm-sdk
mvn clean install –DskipTests
Вы должны установить
.config("spark.hadoop.fs.stocator.scheme.list", "cos") вместе с некоторыми другими
fs.cos... конфигурации.
Вот пример кода сквозного фрагмента Python, который работает. Должно быть несложно преобразовать в Scala:
from pyspark.sql import SparkSession
stocator_jar = '/path/to/stocator-1.1.2-SNAPSHOT-IBM-SDK.jar'
cos_instance_name = '<myCosIntanceName>'
bucket_name = '<bucketName>'
s3_region = '<region>'
cos_iam_api_key = '*******'
iam_servicce_id = 'crn:v1:bluemix:public:iam-identity::<****************>'
spark_builder = (
SparkSession
.builder
.appName('test_app'))
spark_builder.config('spark.driver.extraClassPath', stocator_jar)
spark_builder.config('spark.executor.extraClassPath', stocator_jar)
spark_builder.config(f"fs.cos.{cos_instance_name}.iam.api.key", cos_iam_api_key)
spark_builder.config(f"fs.cos.{cos_instance_name}.endpoint", f"s3.{s3_region}.cloud-object-storage.appdomain.cloud")
spark_builder.config(f"fs.cos.{cos_instance_name}.iam.service.id", iam_servicce_id)
spark_builder.config("spark.hadoop.fs.stocator.scheme.list", "cos")
spark_builder.config("spark.hadoop.fs.cos.impl", "com.ibm.stocator.fs.ObjectStoreFileSystem")
spark_builder.config("fs.stocator.cos.impl", "com.ibm.stocator.fs.cos.COSAPIClient")
spark_builder.config("fs.stocator.cos.scheme", "cos")
spark_sess = spark_builder.getOrCreate()
dataset = spark_sess.range(1, 10)
dataset = dataset.withColumnRenamed('id', 'user_idx')
dataset.repartition(1).write.csv(
f'cos://{bucket_name}.{cos_instance_name}/test.csv',
mode='overwrite',
header=True)
spark_sess.stop()
print('done!')
Я использую Spark версии 2.4.5 и Scala версии 2.11.12 в Windows 10. Я уже добавил путь к классам для обоих в переменной среды.
Команда для запуска оболочки Spark (откройте командную строку и вставьте команду ниже):
spark-shell --packages com.ibm.stocator:stocator:1.0.36
Если вы получаете подробную информацию, как показано ниже, это означает, что вы успешно запустили искровой снаряд. 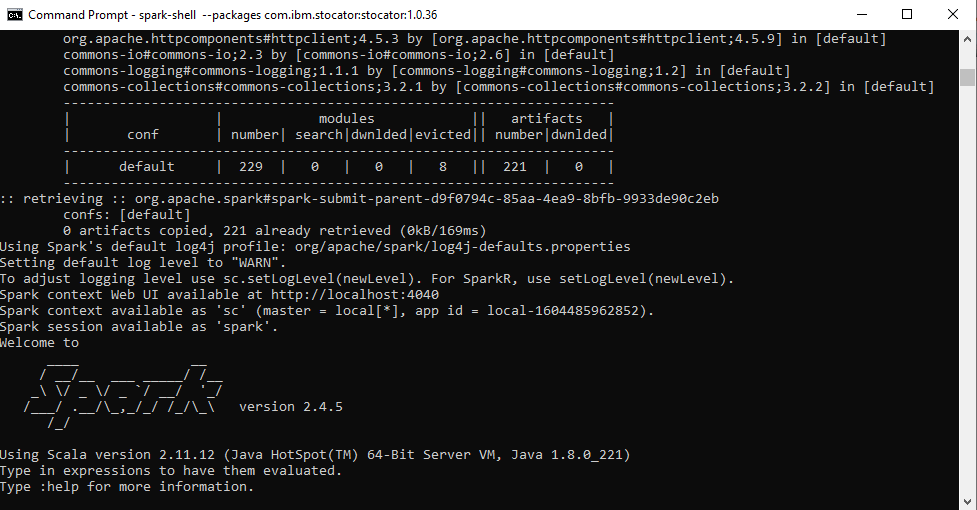
вы также можете проверить это в браузере, как указано в командной строке, например - Веб-интерфейс контекста Spark доступен по адресу http://localhost:4040 (в вашем случае порт может измениться).
Задайте информацию о конфигурации в scala (моя COS находится на востоке США):
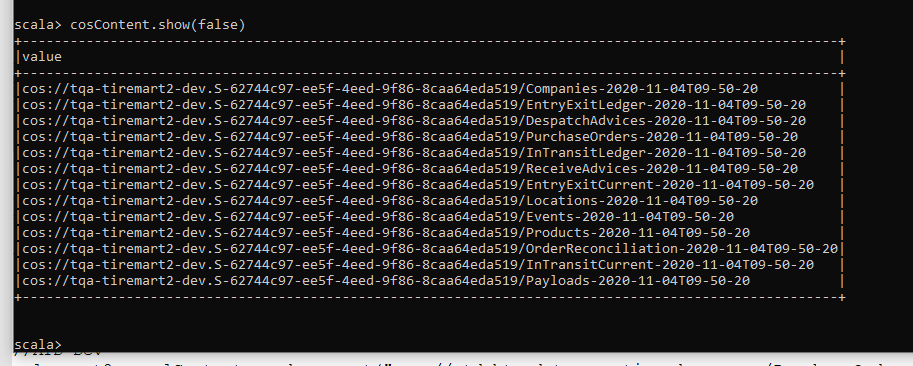
sc.hadoopConfiguration.set("fs.stocator.scheme.list", "cos") sc.hadoopConfiguration.set("fs.cos.impl", "com.ibm.stocator.fs.ObjectStoreFileSystem") sc.hadoopConfiguration.set("fs.stocator.cos.impl", "com.ibm.stocator.fs.cos.COSAPIClient") sc.hadoopConfiguration.set("fs.stocator.cos.scheme", "cos") sc.hadoopConfiguration.set("fs.cos.mycos.access.key", "your access key") sc.hadoopConfiguration.set("fs.cos.mycos.secret.key", "your secret key") sc.hadoopConfiguration.set("fs.cos.mycos.endpoint", "https://s3.us-east.cloud-object-storage.appdomain.cloud")Получите список объектов из файла манифеста:
val sqlContext = new org.apache.spark.sql.SQLContext(sc) val cosContent = sqlContext.read.text("cos://someBucketName.mycos/someFile.mf") cosContent.show(false)
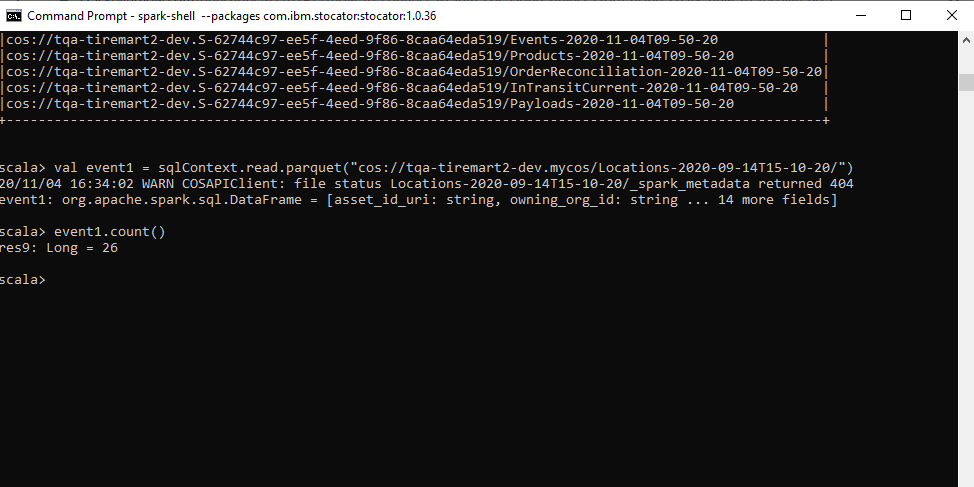
ИЛИ вы можете прочитать данные из файла паркета, как показано ниже:
val event1 = sqlContext.read.parquet("cos://someBucketName.mycos/parquetDirectoryName/")
event1.printSchema()
event1.count()
event1.show(false)