Преобразование XML в фреймворк pandas
Я хочу преобразовать XML в pandas DataFrame. Я использовалElementTree библиотека для анализа XML.
import pandas as pd
import xml.etree.ElementTree as et
xtree = et.parse('xmlfile.xml)
xroot = xtree.getroot()
[elem.tag for elem in xroot.iter()]
Как мне получить доступ к значениям каждого тега, чтобы я мог преобразовать XML в фреймворк pandas?
Dataframe должен выглядеть так:
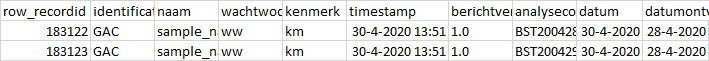
Используя следующий XML в качестве примера, можете ли вы придумать код Python для реализации вышеуказанного DataFrame?
<?xml version="1.0" encoding="UTF-8"?>
<!-- Deze grammatica wordt niet meer gebruikt. Gebruik voortaan FMPXMLRESULT. -->
-<FMPDSORESULT xmlns="http://www.filemaker.com/fmpdsoresult">
<ERRORCODE>0</ERRORCODE>
<DATABASE>FrontEnd.fmp12</DATABASE>
<LAYOUT/>
-<ROW RECORDID="183122" MODID="0">
<identificatie>GAC</identificatie>
<naam>sample_naam_1</naam>
<wachtwoord>ww</wachtwoord>
<kenmerk>km</kenmerk>
<timestamp>30-4-2020 13:51:05</timestamp>
<berichtversie>1.0</berichtversie>
<analysecode>BST200428</analysecode>
<datum>30-4-2020</datum>
<datumontvangst>28-4-2020</datumontvangst>
</ROW>
-<ROW RECORDID="183123" MODID="0">
<identificatie>GAC</identificatie>
<naam>sample_naam_2</naam>
<wachtwoord>ww</wachtwoord>
<kenmerk>km</kenmerk>
<timestamp>30-4-2020 13:51:05</timestamp>
<berichtversie>1.0</berichtversie>
<analysecode>BST200429</analysecode>
<datum>30-4-2020</datum>
<datumontvangst>28-4-2020</datumontvangst>
</ROW>
</FMPDSORESULT>
2 ответа
Решение
Вы можете использовать xmltodict для анализа вашего XML, а затем создать фрейм данных.
Попробуй это:
import pandas as pd
import xmltodict
data = """
<?xml version='1.0' encoding='UTF-8'?>
<FMPDSORESULT xmlns='http://www.filemaker.com/fmpdsoresult'>
<ERRORCODE>0</ERRORCODE>
<DATABASE>FrontEnd.fmp12</DATABASE>
<LAYOUT/>
<ROW RECORDID='183122' MODID='0'>
<identificatie>GAC</identificatie>
<naam>sample_naam_1</naam>
<wachtwoord>ww</wachtwoord>
<kenmerk>km</kenmerk>
<timestamp>30-4-2020 13:51:05</timestamp>
<berichtversie>1.0</berichtversie>
<analysecode>BST200428</analysecode>
<datum>30-4-2020</datum>
<datumontvangst>28-4-2020</datumontvangst>
</ROW>
<ROW RECORDID='183123' MODID='0'>
<identificatie>GAC</identificatie>
<naam>sample_naam_2</naam>
<wachtwoord>ww</wachtwoord>
<kenmerk>km</kenmerk>
<timestamp>30-4-2020 13:51:05</timestamp>
<berichtversie>1.0</berichtversie>
<analysecode>BST200429</analysecode>
<datum>30-4-2020</datum>
<datumontvangst>28-4-2020</datumontvangst>
</ROW>
</FMPDSORESULT>
"""
parsed = xmltodict.parse(data.strip())
df = pd.DataFrame(parsed["FMPDSORESULT"]["ROW"])
display(df)
Это распечатывает:
@RECORDID @MODID identificatie naam wachtwoord kenmerk timestamp berichtversie analysecode datum datumontvangst
0 183122 0 GAC sample_naam_1 ww km 30-4-2020 13:51:05 1.0 BST200428 30-4-2020 28-4-2020
1 183123 0 GAC sample_naam_2 ww km 30-4-2020 13:51:05 1.0 BST200429 30-4-2020 28-4-2020
Имейте в виду, что мне пришлось дополнительно очистить ваш XML и поменять местами все круглые скобки (") к одиночным (').
Я сделал пакет для аналогичного варианта использования. Здесь тоже может сработать.
pip install pandas_read_xml
ты можешь сделать что-то вроде
import pandas_read_xml as pdx
df = pdx.read_xml('filename.xml', ['FMPDSORESULT'])
Чтобы сгладить, вы могли
df = pdx.flatten(df)
или
df = pdx.fully_flatten(df)