Проблема с escape-символом и кавычками фабрики данных Azure - действие копирования
У меня есть конвейеры ADF, экспортирующие (через активность копирования) данные из базы данных SQL Azure в озеро данных (ADLS2), а затем оттуда в другую базу данных SQL Azure. Все работало нормально, пока не появились некоторые персонажи.
Вот как выглядит запись о виновнике в первой базе данных SQL Azure: "Gasunie\
введите описание изображения здесь
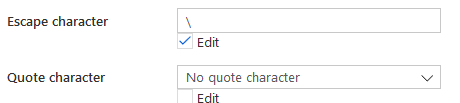
Вот как набор данных настраивается в ADF для его экспорта в ADLS: разделитель столбцов - вертикальная черта Разделитель строк - автоматическое определение кодировки - по умолчанию (UTF-8) escape-символ - обратная косая черта () кавычка - двойная кавычка (")
введите описание изображения здесь
Вот как выглядит экспортированный файл в блокноте ++ (это файл с разделителями-вертикальными чертами): "\"Gasunie\" введите здесь описание изображения
Это настройки для набора данных adls в ADF при его загрузке из adls в azure sql db: разделитель столбцов - запятая Разделитель строк - автоматическое определение кодировки - по умолчанию (UTF-8) символ escape - обратная косая черта () символ кавычки - двойная кавычка (")
Обратите внимание, что теперь он разделен запятыми, но это не вызывает никаких проблем.
введите описание изображения здесь
Но вот как это выглядит после загрузки: "Gasunie"|1|||||||||||... Изначально существовавшая обратная косая черта каким-то образом заставила его остановить разделение для следующих нескольких столбцов. введите описание изображения здесь
Я пробовал много, много различных настроек для кавычек и escape-символов, но они создают больше проблем для других данных в наборе данных.
Кто-нибудь знает, как я могу это исправить, не требуя исправления источника?
Примечание: есть причина, по которой он хранится в adls, поэтому он не может быть копией из базы данных Azure sql в другую базу данных Azure Sql.
Он построен консультантами на основе шаблона, сильно параметризован, поэтому вставка потоков данных для обработки файлов в ADL будет очень длительным процессом.
Любая помощь приветствуется. Спасибо.
3 ответа
Столкнулся с похожей проблемой.
Я думаю, что с вами происходит следующее.
- Данные состоят из 9 символов, например, "Gasunie\"
- Вывод записывается в кавычки и использует \ как escape-символ.
- Таким образом, на выходе будет "your_text", но любые кавычки в your_text заменяются на \"
- Таким образом, на выходе получается "\"Gasunie\" - внешние кавычки заключают ваш текст, а внутренние кавычки экранированы с помощью \
Теперь мы подошли к тому, чтобы прочитать это снова: похоже, это разбирается вот так.
- Первая кавычка - это начало вашего значения поля в кавычках, поэтому с этого момента я читаю значение вашего текстового поля.
- Затем я вижу \"символ кавычки (который был экранирован).
- Затем я вижу Газюни
- Затем я вижу \"символ кавычки (который был экранирован).
- Затем я вижу разделители полей, но поскольку я все еще думаю, что нахожусь внутри поля, заключенного в кавычки, то они просто текст, поэтому они включены в мой вывод "Gasunie"|1|||||||||||...
- Я продолжаю читать символы в этом поле, пока не дойду до следующей двойной кавычки, после чего я ожидаю, что новый разделитель начнет следующее поле.
Итак, проблема в том, что ADF заключает в кавычки любую строку, которую он держит в руке, и записывает это в вывод; а при вводе он анализирует слева направо, поэтому любая строка, оканчивающаяся на escape-символ, является проблемой. Я не уверен, что вы назовете это ошибкой.
Что ты можешь сделать?
В вашем случае просто измените escape-символ на то, чего никогда не было в вашем вводе (возможно, @ или {или что-то в этом роде). Тогда \"в конце вашего выходного текста больше не будет экранированной кавычкой.
Мой аналогичный случай - когда escape-символ не является escape-символом?
У меня есть поле, содержащее запятую, но запятая также является разделителем полей. Мои данные поступают от третьей стороны, и они легко экранировали эту запятую для меня, используя обратную косую черту, таким образом:
Field One, Field\,Two, Field Three
У меня есть экранирующий символ \, так что можно подумать, что это даст мне три выходных поля:
| Field One | Field,Two | Field Three |
Неправильно. Управляющий символ работает только тогда, когда он находится внутри поля, заключенного в кавычки. Мой ввод не цитируется, поэтому обратная косая черта обрабатывается просто как текст, а запятая - это разделитель полей, что означает, что мой вывод имеет четыре поля
| Field One | Field\ | Two | Field Three |
Решение: скажите моему набору данных ADF, что вокруг моего ввода нет кавычек - тогда он обрабатывает все, что находится после запятой, как текстовое поле и применяет escape-символ, как ожидалось.
Возможно, вас заинтересует https://feedback.azure.com/forums/270578-data-factory/suggestions/35482144-text-format-escape-char-only-if-needed-or-per-fiel.
Так что, если вы ищете "экранированная запятая в csv создает дополнительное поле", я надеюсь, что это сэкономит вам немного времени!
Просто предложение, я придумал ситуацию, когда при копировании данных из azuresql в datalake, символы возврата каретки и новой строки разделяли сохраненный файл csv на adls. Я заменил их в запросе, используя следующий код, и он сработал.
replace (REPLACE(Description,CHAR(10),''),char(13),'') Описание
Вы можете попробовать следующее
REPLACE([yourcolumn],char(34),' ')


у меня возникла проблема, когда строка заканчивалась на ", а escape-символом был /", поэтому первое, что я сделал, это удалил все выражения регулярных выражений из столбца, а затем загрузил данные.
SELECT replace(translate(COL_NAME , ',~@#$%&*().!/\', replace(' ',14)), ' ', '') as COL_NEW_NAME FROM TABLE_NAME;
Или вы можете попробовать сделать следующее:
