mlr3 PipeOps: создавайте ветки с различными преобразованиями данных и сравнивайте разных учащихся внутри и между ветвями.
Я бы хотел использовать PipeOps для обучения учащегося трем альтернативным преобразованиям набора данных:
- Никакой трансформации.
- Уравновешивание классов - вниз.
- Балансировка классов.
Затем я хотел бы сравнить три изученные модели.
Моя идея заключалась в том, чтобы настроить конвейер следующим образом:
- Сделайте конвейер: Ввод -> Импортировать набор данных (необязательно) -> Ветвь -> Разделить на три ветви, описанные выше -> Добавить учащегося в каждую ветвь -> Разветвить.
- Обучайте конвейер и надеюсь (вот где я ошибаюсь), что результат будет сохранен для каждого ученика в каждой ветви.
К сожалению, выполнение этих шагов приводит к тому, что один учащийся, кажется, "объединил" все из разных ветвей. Я надеялся получить список длиной 3, но вместо этого получил список длиной 1.
Код R:
library(data.table)
library(paradox)
library(mlr3)
library(mlr3filters)
library(mlr3learners)
library(mlr3misc)
library(mlr3pipelines)
library(mlr3tuning)
library(mlr3viz)
learner <- lrn("classif.rpart", predict_type = "prob")
learner$param_set$values <- list(
cp = 0,
maxdepth = 21,
minbucket = 12,
minsplit = 24
)
graph =
po("imputehist") %>>%
po("branch", c("nop", "classbalancing_up", "classbalancing_down")) %>>%
gunion(list(
po("nop", id = "null"),
po("classbalancing", id = "classbalancing_down", ratio = 2, reference = 'minor'),
po("classbalancing", id = "classbalancing_up", ratio = 2, reference = 'major')
)) %>>%
gunion(list(
po("learner", learner, id = "learner_null"),
po("learner", learner, id = "learner_classbalancing_down"),
po("learner", learner, id = "learner_classbalancing_up")
)) %>>%
po("unbranch")
plot(graph)
tr <- mlr3::resample(tsk("iris"), graph, rsmp("holdout"))
tr$learners
Вопрос 1 Как я могу вместо этого получить три разных результата?
Вопрос 2 Как я могу сравнить эти три результата в конвейере после неразветвления?
Вопрос 3 Что, если я хочу добавить нескольких учащихся в каждую ветку? Я бы хотел, чтобы некоторые учащиеся были вставлены с фиксированными гиперпараметрами, а для других я бы хотел, чтобы их гиперпараметры были настроены с помощьюAutoTunerвнутри каждой ветви. Затем я хотел бы сравнить их в каждой ветке и выбрать "лучшие" из каждой ветки. Наконец, я хотел бы сравнить трех лучших учеников, чтобы в итоге получился единственный лучший.
Большое спасибо.
2 ответа
Я думаю, что нашел ответ на то, что ищу. Вкратце, я бы хотел:
Создайте конвейер графа с несколькими учениками. Я бы хотел, чтобы некоторые учащиеся были вставлены с фиксированными гиперпараметрами, а для других я бы хотел настроить их гиперпараметры. Затем я хотел бы сравнить их и выбрать "лучший". Я также хотел бы, чтобы бенчмаркинг учащихся проводился с использованием различных стратегий балансировки классов, а именно: ничего не делать, повышать и понижать выборку. Оптимальные настройки параметров для повышения / понижения дискретизации (например, отношения) также будут определены во время настройки.
Два примера ниже, один, что почти делает то, что я хочу, а другие делают именно то, что я хочу.
Пример 1. Создайте канал, включающий всех учащихся, то есть учащихся с фиксированными гиперпараметрами, а также учащихся, гиперпараметры которых требуют настройки.
Как будет показано ниже, использование обоих типов учащихся (то есть с фиксированными и настраиваемыми гиперпараметрами) кажется плохой, поскольку при настройке канала не учитываются учащиеся с настраиваемыми гиперпараметрами.
####################################################################################
# Build Machine Learning pipeline that:
# 1. Imputes missing values (optional).
# 2. Tunes and benchmarks a range of learners.
# 3. Handles imbalanced data in different ways.
# 4. Identifies optimal learner for the task at hand.
# Abbreviations
# 1. td: Tuned. Learner already tuned with optimal hyperparameters, as found empirically by Probst et al. (2009). See http://jmlr.csail.mit.edu/papers/volume20/18-444/18-444.pdf
# 2. tn: Tuner. Optimal hyperparameters for the learner to be determined within the Tuner.
# 3. raw: Raw dataset in that class imbalances were not treated in any way.
# 4. up: Data upsampling to balance class imbalances.
# 5. down: Data downsampling to balance class imbalances.
# References
# Probst et al. (2009). http://jmlr.csail.mit.edu/papers/volume20/18-444/18-444.pdf
####################################################################################
task <- tsk('sonar')
# Indices for splitting data into training and test sets
train.idx <- task$data() %>%
select(Class) %>%
rownames_to_column %>%
group_by(Class) %>%
sample_frac(2 / 3) %>% # Stratified sample to maintain proportions between classes.
ungroup %>%
select(rowname) %>%
deframe %>%
as.numeric
test.idx <- setdiff(seq_len(task$nrow), train.idx)
# Define training and test sets in task format
task_train <- task$clone()$filter(train.idx)
task_test <- task$clone()$filter(test.idx)
# Define class balancing strategies
class_counts <- table(task_train$truth())
upsample_ratio <- class_counts[class_counts == max(class_counts)] /
class_counts[class_counts == min(class_counts)]
downsample_ratio <- 1 / upsample_ratio
# 1. Enrich minority class by factor 'ratio'
po_over <- po("classbalancing", id = "up", adjust = "minor",
reference = "minor", shuffle = FALSE, ratio = upsample_ratio)
# 2. Reduce majority class by factor '1/ratio'
po_under <- po("classbalancing", id = "down", adjust = "major",
reference = "major", shuffle = FALSE, ratio = downsample_ratio)
# 3. No class balancing
po_raw <- po("nop", id = "raw") # Pipe operator for 'do nothing' ('nop'), i.e. don't up/down-balance the classes.
# We will be using an XGBoost learner throughout with different hyperparameter settings.
# Define XGBoost learner with the optimal hyperparameters of Probst et al.
# Learner will be added to the pipeline later on, in conjuction with and without class balancing.
xgb_td <- lrn("classif.xgboost", predict_type = 'prob')
xgb_td$param_set$values <- list(
booster = "gbtree",
nrounds = 2563,
max_depth = 11,
min_child_weight = 1.75,
subsample = 0.873,
eta = 0.052,
colsample_bytree = 0.713,
colsample_bylevel = 0.638,
lambda = 0.101,
alpha = 0.894
)
xgb_td_raw <- GraphLearner$new(
po_raw %>>%
po('learner', xgb_td, id = 'xgb_td'),
predict_type = 'prob'
)
xgb_tn_raw <- GraphLearner$new(
po_raw %>>%
po('learner', lrn("classif.xgboost",
predict_type = 'prob'), id = 'xgb_tn'),
predict_type = 'prob'
)
xgb_td_up <- GraphLearner$new(
po_over %>>%
po('learner', xgb_td, id = 'xgb_td'),
predict_type = 'prob'
)
xgb_tn_up <- GraphLearner$new(
po_over %>>%
po('learner', lrn("classif.xgboost",
predict_type = 'prob'), id = 'xgb_tn'),
predict_type = 'prob'
)
xgb_td_down <- GraphLearner$new(
po_under %>>%
po('learner', xgb_td, id = 'xgb_td'),
predict_type = 'prob'
)
xgb_tn_down <- GraphLearner$new(
po_under %>>%
po('learner', lrn("classif.xgboost",
predict_type = 'prob'), id = 'xgb_tn'),
predict_type = 'prob'
)
learners_all <- list(
xgb_td_raw,
xgb_tn_raw,
xgb_td_up,
xgb_tn_up,
xgb_td_down,
xgb_tn_down
)
names(learners_all) <- sapply(learners_all, function(x) x$id)
# Create pipeline as a graph. This way, pipeline can be plotted. Pipeline can then be converted into a learner with GraphLearner$new(pipeline).
# Pipeline is a collection of Graph Learners (type ?GraphLearner in the command line for info).
# Each GraphLearner is a td or tn model (see abbreviations above) with or without class balancing.
# Up/down or no sampling happens within each GraphLearner, otherwise an error during tuning indicates that there are >= 2 data sources.
# Up/down or no sampling within each GraphLearner can be specified by chaining the relevant pipe operators (function po(); type ?PipeOp in command line) with the PipeOp of each learner.
graph <-
#po("imputehist") %>>% # Optional. Impute missing values only when using classifiers that can't handle them (e.g. Random Forest).
po("branch", names(learners_all)) %>>%
gunion(unname(learners_all)) %>>%
po("unbranch")
graph$plot() # Plot pipeline
pipe <- GraphLearner$new(graph) # Convert pipeline to learner
pipe$predict_type <- 'prob' # Don't forget to specify we want to predict probabilities and not classes.
ps_table <- as.data.table(pipe$param_set)
View(ps_table[, 1:4])
# Set hyperparameter ranges for the tunable learners
ps_xgboost <- ps_table$id %>%
lapply(
function(x) {
if (grepl('_tn', x)) {
if (grepl('.booster', x)) {
ParamFct$new(x, levels = "gbtree")
} else if (grepl('.nrounds', x)) {
ParamInt$new(x, lower = 100, upper = 110)
} else if (grepl('.max_depth', x)) {
ParamInt$new(x, lower = 3, upper = 10)
} else if (grepl('.min_child_weight', x)) {
ParamDbl$new(x, lower = 0, upper = 10)
} else if (grepl('.subsample', x)) {
ParamDbl$new(x, lower = 0, upper = 1)
} else if (grepl('.eta', x)) {
ParamDbl$new(x, lower = 0.1, upper = 0.6)
} else if (grepl('.colsample_bytree', x)) {
ParamDbl$new(x, lower = 0.5, upper = 1)
} else if (grepl('.gamma', x)) {
ParamDbl$new(x, lower = 0, upper = 5)
}
}
}
)
ps_xgboost <- Filter(Negate(is.null), ps_xgboost)
ps_xgboost <- ParamSet$new(ps_xgboost)
# Se parameter ranges for the class balancing strategies
ps_class_balancing <- ps_table$id %>%
lapply(
function(x) {
if (all(grepl('up.', x), grepl('.ratio', x))) {
ParamDbl$new(x, lower = 1, upper = upsample_ratio)
} else if (all(grepl('down.', x), grepl('.ratio', x))) {
ParamDbl$new(x, lower = downsample_ratio, upper = 1)
}
}
)
ps_class_balancing <- Filter(Negate(is.null), ps_class_balancing)
ps_class_balancing <- ParamSet$new(ps_class_balancing)
# Define parameter set
param_set <- ParamSetCollection$new(list(
ParamSet$new(list(pipe$param_set$params$branch.selection$clone())), # ParamFct can be copied.
ps_xgboost,
ps_class_balancing
))
# Add dependencies. For instance, we can only set the mtry value if the pipe is configured to use the Random Forest (ranger).
# In a similar manner, we want do add a dependency between, e.g. hyperparameter "raw.xgb_td.xgb_tn.booster" and branch "raw.xgb_td"
# See https://mlr3gallery.mlr-org.com/tuning-over-multiple-learners/
param_set$ids()[-1] %>%
lapply(
function(x) {
aux <- names(learners_all) %>%
sapply(
function(y) {
grepl(y, x)
}
)
aux <- names(aux[aux])
param_set$add_dep(x, "branch.selection",
CondEqual$new(aux))
}
)
# Set up tuning instance
instance <- TuningInstance$new(
task = task_train,
learner = pipe,
resampling = rsmp('cv', folds = 2),
measures = msr("classif.bbrier"),
#measures = prc_micro,
param_set,
terminator = term("evals", n_evals = 3))
tuner <- TunerRandomSearch$new()
# Tune pipe learner to find best-performing branch
tuner$tune(instance)
instance$result
instance$archive()
instance$archive(unnest = "tune_x") # Unnest the tuner search space values
pipe$param_set$values <- instance$result$params
pipe$train(task_train)
pred <- pipe$predict(task_test)
pred$confusion
Обратите внимание, что тюнер предпочитает игнорировать настройку настраиваемых учеников и фокусируется только на настроенных учениках. Это можно подтвердить, осмотревinstance$result: единственное, что было настроено для настраиваемых учащихся, - это параметры балансировки классов, которые на самом деле не являются гиперпараметрами учащегося.
Пример 2: Создайте канал, включающий только настраиваемых учащихся, найдите "лучшего" и затем сравните его с учащимися с фиксированными гиперпараметрами на втором этапе.
Шаг 1. Создайте канал для настраиваемых учеников
learners_all <- list(
#xgb_td_raw,
xgb_tn_raw,
#xgb_td_up,
xgb_tn_up,
#xgb_td_down,
xgb_tn_down
)
names(learners_all) <- sapply(learners_all, function(x) x$id)
# Create pipeline as a graph. This way, pipeline can be plotted. Pipeline can then be converted into a learner with GraphLearner$new(pipeline).
# Pipeline is a collection of Graph Learners (type ?GraphLearner in the command line for info).
# Each GraphLearner is a td or tn model (see abbreviations above) with or without class balancing.
# Up/down or no sampling happens within each GraphLearner, otherwise an error during tuning indicates that there are >= 2 data sources.
# Up/down or no sampling within each GraphLearner can be specified by chaining the relevant pipe operators (function po(); type ?PipeOp in command line) with the PipeOp of each learner.
graph <-
#po("imputehist") %>>% # Optional. Impute missing values only when using classifiers that can't handle them (e.g. Random Forest).
po("branch", names(learners_all)) %>>%
gunion(unname(learners_all)) %>>%
po("unbranch")
graph$plot() # Plot pipeline
pipe <- GraphLearner$new(graph) # Convert pipeline to learner
pipe$predict_type <- 'prob' # Don't forget to specify we want to predict probabilities and not classes.
ps_table <- as.data.table(pipe$param_set)
View(ps_table[, 1:4])
ps_xgboost <- ps_table$id %>%
lapply(
function(x) {
if (grepl('_tn', x)) {
if (grepl('.booster', x)) {
ParamFct$new(x, levels = "gbtree")
} else if (grepl('.nrounds', x)) {
ParamInt$new(x, lower = 100, upper = 110)
} else if (grepl('.max_depth', x)) {
ParamInt$new(x, lower = 3, upper = 10)
} else if (grepl('.min_child_weight', x)) {
ParamDbl$new(x, lower = 0, upper = 10)
} else if (grepl('.subsample', x)) {
ParamDbl$new(x, lower = 0, upper = 1)
} else if (grepl('.eta', x)) {
ParamDbl$new(x, lower = 0.1, upper = 0.6)
} else if (grepl('.colsample_bytree', x)) {
ParamDbl$new(x, lower = 0.5, upper = 1)
} else if (grepl('.gamma', x)) {
ParamDbl$new(x, lower = 0, upper = 5)
}
}
}
)
ps_xgboost <- Filter(Negate(is.null), ps_xgboost)
ps_xgboost <- ParamSet$new(ps_xgboost)
ps_class_balancing <- ps_table$id %>%
lapply(
function(x) {
if (all(grepl('up.', x), grepl('.ratio', x))) {
ParamDbl$new(x, lower = 1, upper = upsample_ratio)
} else if (all(grepl('down.', x), grepl('.ratio', x))) {
ParamDbl$new(x, lower = downsample_ratio, upper = 1)
}
}
)
ps_class_balancing <- Filter(Negate(is.null), ps_class_balancing)
ps_class_balancing <- ParamSet$new(ps_class_balancing)
param_set <- ParamSetCollection$new(list(
ParamSet$new(list(pipe$param_set$params$branch.selection$clone())), # ParamFct can be copied.
ps_xgboost,
ps_class_balancing
))
# Add dependencies. For instance, we can only set the mtry value if the pipe is configured to use the Random Forest (ranger).
# In a similar manner, we want do add a dependency between, e.g. hyperparameter "raw.xgb_td.xgb_tn.booster" and branch "raw.xgb_td"
# See https://mlr3gallery.mlr-org.com/tuning-over-multiple-learners/
param_set$ids()[-1] %>%
lapply(
function(x) {
aux <- names(learners_all) %>%
sapply(
function(y) {
grepl(y, x)
}
)
aux <- names(aux[aux])
param_set$add_dep(x, "branch.selection",
CondEqual$new(aux))
}
)
# Set up tuning instance
instance <- TuningInstance$new(
task = task_train,
learner = pipe,
resampling = rsmp('cv', folds = 2),
measures = msr("classif.bbrier"),
#measures = prc_micro,
param_set,
terminator = term("evals", n_evals = 3))
tuner <- TunerRandomSearch$new()
# Tune pipe learner to find best-performing branch
tuner$tune(instance)
instance$result
instance$archive()
instance$archive(unnest = "tune_x") # Unnest the tuner search space values
pipe$param_set$values <- instance$result$params
pipe$train(task_train)
pred <- pipe$predict(task_test)
pred$confusion
Обратите внимание, что сейчас instance$result возвращает оптимальные результаты и для гиперпараметров учащихся, а не только для параметров балансировки классов.
Шаг 2: сравнительный анализ "лучшего" настраиваемого учащегося (теперь настроенного) и учащихся с фиксированными гиперпараметрами.
# Define re-sampling and instantiate it so always the same split will be used
resampling <- rsmp("cv", folds = 2)
set.seed(123)
resampling$instantiate(task_train)
bmr <- benchmark(
design = benchmark_grid(
task_train,
learner = list(pipe, xgb_td_raw, xgb_td_up, xgb_tn_down),
resampling
),
store_models = TRUE # Only needed if you want to inspect the models
)
bmr$aggregate(msr("classif.bbrier"))
Несколько вопросов для рассмотрения
- Мне, вероятно, следовало создать второй, отдельный канал для учащихся с фиксированными гиперпараметрами, чтобы хотя бы настроить параметры балансировки классов. Затем две трубы (настраиваемый и фиксированный гиперпараметры) будут протестированы с помощью
benchmark(). - Возможно, мне следовало использовать одну и ту же стратегию передискретизации от начала до конца? То есть создайте экземпляр стратегии повторной выборки прямо перед настройкой первой трубы, чтобы эта стратегия также использовалась во второй трубе и в финальном тесте.
Комментарии / подтверждение более чем приветствуются.
( missuse благодарность missuse за конструктивные комментарии)
Самый простой способ сравнить несколько конвейеров - определить соответствующие графики и использовать функцию тестирования:
library(paradox)
library(mlr3)
library(mlr3pipelines)
library(mlr3tuning)
learner <- lrn("classif.rpart", predict_type = "prob")
learner$param_set$values <- list(
cp = 0,
maxdepth = 21,
minbucket = 12,
minsplit = 24
)
Создайте древовидные графики:
график 1, просто импутехист
graph_nop <- po("imputehist") %>>%
learner
График 2: мажоритарный класс с импутеистом и неполной выборкой (отношение к классу большинства)
graph_down <- po("imputehist") %>>%
po("classbalancing", id = "undersample", adjust = "major",
reference = "major", shuffle = FALSE, ratio = 1/2) %>>%
learner
График 3: вмененная история и дополнительная выборка класса меньшинства (соотношение по отношению к классу меньшинства)
graph_up <- po("imputehist") %>>%
po("classbalancing", id = "oversample", adjust = "minor",
reference = "minor", shuffle = FALSE, ratio = 2) %>>%
learner
Преобразуйте графики в учащихся и установите pred_type
graph_nop <- GraphLearner$new(graph_nop)
graph_nop$predict_type <- "prob"
graph_down <- GraphLearner$new(graph_down)
graph_down$predict_type <- "prob"
graph_up <- GraphLearner$new(graph_up)
graph_up$predict_type <- "prob"
определить повторную выборку и создать ее экземпляр, чтобы всегда использовалось одно и то же разбиение:
hld <- rsmp("holdout")
set.seed(123)
hld$instantiate(tsk("sonar"))
Контрольный показатель
bmr <- benchmark(design = benchmark_grid(task = tsk("sonar"),
learner = list(graph_nop,
graph_up,
graph_down),
hld),
store_models = TRUE) #only needed if you want to inspect the models
проверьте результат с помощью различных мер:
bmr$aggregate(msr("classif.auc"))
nr resample_result task_id learner_id resampling_id iters classif.auc
1: 1 <ResampleResult> sonar imputehist.classif.rpart holdout 1 0.7694257
2: 2 <ResampleResult> sonar imputehist.oversample.classif.rpart holdout 1 0.7360642
3: 3 <ResampleResult> sonar imputehist.undersample.classif.rpart holdout 1 0.7668919
bmr$aggregate(msr("classif.ce"))
nr resample_result task_id learner_id resampling_id iters classif.ce
1: 1 <ResampleResult> sonar imputehist.classif.rpart holdout 1 0.3043478
2: 2 <ResampleResult> sonar imputehist.oversample.classif.rpart holdout 1 0.3188406
3: 3 <ResampleResult> sonar imputehist.undersample.classif.rpart holdout 1 0.2898551
Это также можно выполнить в одном конвейере с ветвлением, но нужно будет определить набор параметров и использовать тюнер:
graph2 <-
po("imputehist") %>>%
po("branch", c("nop", "classbalancing_up", "classbalancing_down")) %>>%
gunion(list(
po("nop", id = "nop"),
po("classbalancing", id = "classbalancing_up", ratio = 2, reference = 'major'),
po("classbalancing", id = "classbalancing_down", ratio = 2, reference = 'minor')
)) %>>%
po("unbranch") %>>%
learner
graph2$plot()
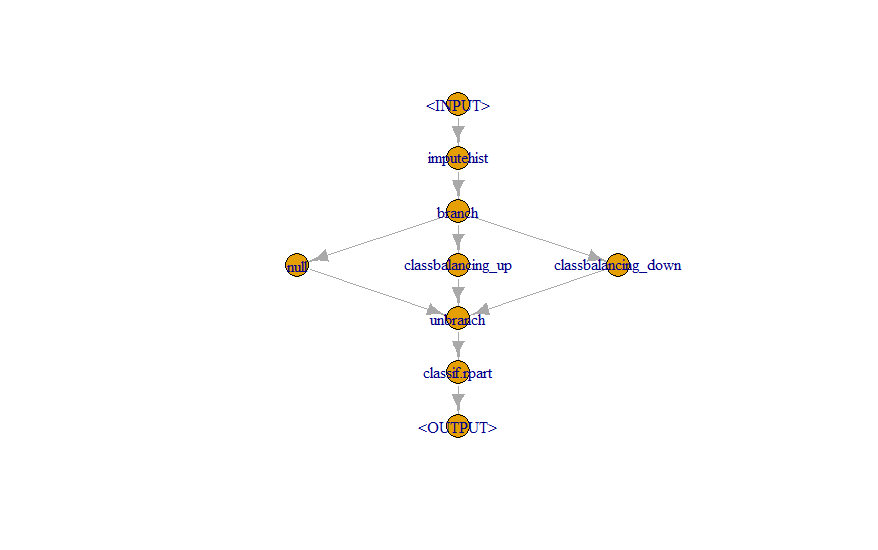
Обратите внимание, что разветвление происходит до учащегося, поскольку используется один (всегда один и тот же) учащийся. Преобразуйте график в ученика и установите pred_type
graph2 <- GraphLearner$new(graph2)
graph2$predict_type <- "prob"
Определите набор параметров. В этом случае просто разные варианты веток.
ps <- ParamSet$new(
list(
ParamFct$new("branch.selection", levels = c("nop", "classbalancing_up", "classbalancing_down"))
))
В общем, вы хотели бы добавить также гиперпараметры учащегося, такие как cp и minsplit для rpart, а также соотношение избыточной / недостаточной выборки.
Создайте экземпляр настройки и поиск по сетке с разрешением 1, поскольку никакие другие параметры не настраиваются. Тюнер будет перебирать различные ветви конвейера, как определено в наборе параметров.
instance <- TuningInstance$new(
task = tsk("sonar"),
learner = graph2,
resampling = hld,
measures = msr("classif.auc"),
param_set = ps,
terminator = term("none")
)
tuner <- tnr("grid_search", resolution = 1)
set.seed(321)
tuner$tune(instance)
Проверяем результат:
instance$archive(unnest = "tune_x")
nr batch_nr resample_result task_id
1: 1 1 <ResampleResult> sonar
2: 2 2 <ResampleResult> sonar
3: 3 3 <ResampleResult> sonar
learner_id resampling_id iters params
1: imputehist.branch.null.classbalancing_up.classbalancing_down.unbranch.classif.rpart holdout 1 <list>
2: imputehist.branch.null.classbalancing_up.classbalancing_down.unbranch.classif.rpart holdout 1 <list>
3: imputehist.branch.null.classbalancing_up.classbalancing_down.unbranch.classif.rpart holdout 1 <list>
warnings errors classif.auc branch.selection
1: 0 0 0.7842061 classbalancing_down
2: 0 0 0.7673142 classbalancing_up
3: 0 0 0.7694257 nop
Несмотря на то, что приведенный выше пример возможен, я думаю, что mlr3pipelines разработан таким образом, что вы настраиваете гиперпараметры учащегося вместе с шагами предварительной обработки, а также выбираете лучшие шаги предварительной обработки (через ветвление).
В вопросе 3 есть несколько подвопросов, на некоторые из которых потребуется довольно много кода и пояснений, чтобы ответить. Я предлагаю проверить mlr3book, а также mlr3gallery.
РЕДАКТИРОВАТЬ: сообщение галереи mlr3: https://mlr3gallery.mlr-org.com/posts/2020-03-30-imbalanced-data/ имеет отношение к вопросу.