Как создать конвейер AWS IoT Analytics Pipeline с отдельным набором данных для каждого устройства?
У меня есть мобильное приложение, которое получает данные с датчиков и отправляет их в AWS IoT Core Topic. Я хочу передать эти данные в AWS IoT Analytics, а затем проанализировать их с помощью собственного кода машинного обучения - с использованием контейнерных наборов данных. Важно убедиться, что события разделяются и группируются поdevice_idи проанализированы в 30-минутных временных окнах. В моем случае имеет смысл анализировать только вместе группу событий, которые генерируются одним и тем же device_id. Полезные данные события уже содержат уникальное свойство device_id. Первое решение, которое приходит на ум, - создать отдельныйChannel -> Pipeline -> DataStore -> SQL DataSet -> Container Data Setнастройка для каждого из мобильных клиентов. Визуально это выглядит так:
учитывая, что количество устройств равно N, проблема с этой архитектурой заключается в том, что мне нужно иметь N каналов, N конвейеров, которые фактически идентичны, N хранилищ данных, которые хранят идентичный тип / схему данных и, наконец, 2*N наборов данных. Так что, если у меня есть 50 000 устройств, количество ресурсов огромно. Это заставляет меня понять, что это не лучшее решение. Следующая идея, которая приходит мне в голову, - иметь только один канал, один конвейер и одно хранилище данных для всех устройств и иметь только разные наборы данных SQL и разные наборы данных контейнера для каждого устройства. Это выглядит так:
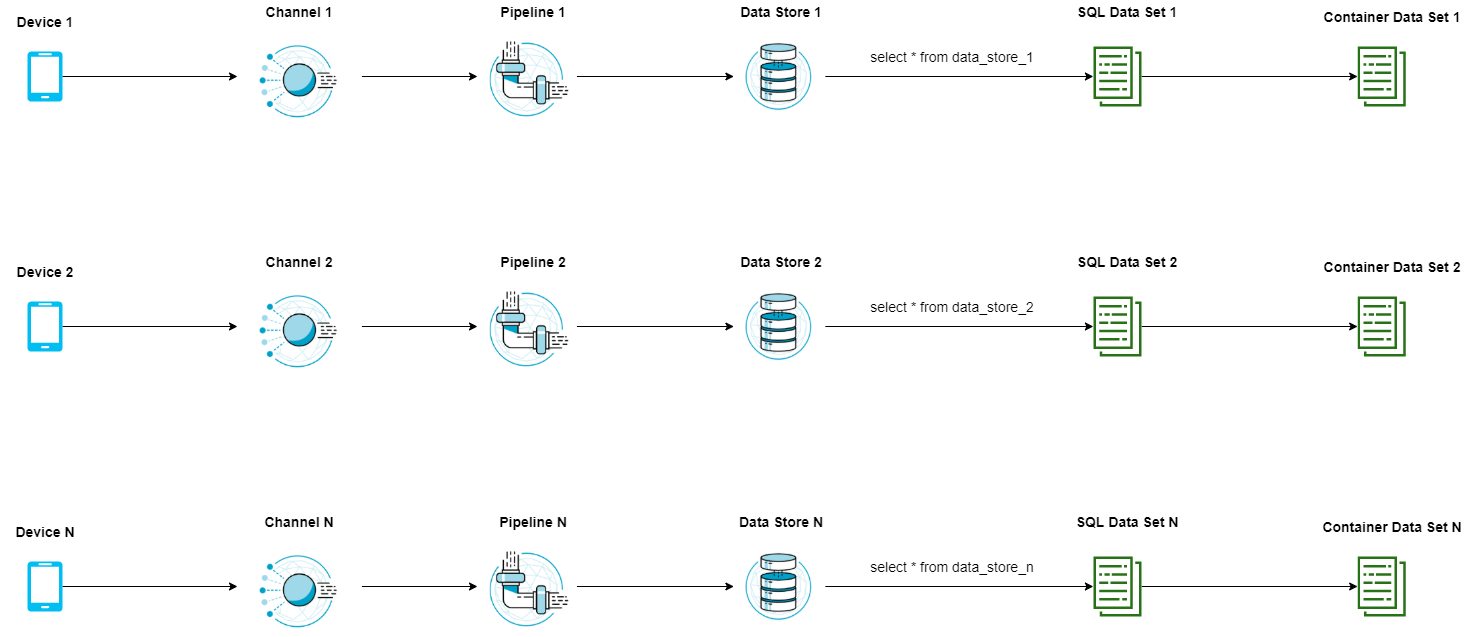 Эта архитектура сейчас выглядит намного лучше, но если бы у меня было 50 000 устройств, мне все равно понадобилось бы 100 000 различных наборов данных. Лимит AWS по умолчанию - 100 наборов данных на аккаунт. Конечно, я могу запросить увеличение лимита, но если лимит по умолчанию составляет 100 наборов данных, тогда мне интересно, имеет ли смысл запрашивать увеличение лимита, которое в 1000 раз превышает значение по умолчанию? В какой из этих двух архитектур предполагается использовать AWS IoT Analytics, или мне что-то не хватает?
Эта архитектура сейчас выглядит намного лучше, но если бы у меня было 50 000 устройств, мне все равно понадобилось бы 100 000 различных наборов данных. Лимит AWS по умолчанию - 100 наборов данных на аккаунт. Конечно, я могу запросить увеличение лимита, но если лимит по умолчанию составляет 100 наборов данных, тогда мне интересно, имеет ли смысл запрашивать увеличение лимита, которое в 1000 раз превышает значение по умолчанию? В какой из этих двух архитектур предполагается использовать AWS IoT Analytics, или мне что-то не хватает?
1 ответ
Я разместил тот же вопрос на форуме AWS и получил полезный ответ от инженера, который там работает. Я публикую его ответ здесь для тех, у кого могут быть похожие требования к архитектуре, как у меня:
Я не думаю, что набор данных для каждого пользователя - правильный способ смоделировать это. Мы бы рекомендовали архитектуру данных использовать один набор данных (или, может быть, небольшое количество наборов данных, развернутых по типу устройства, стране или другой группировке более высокого уровня) и иметь SQL-запрос, который извлекает данные за интересующий период времени., 30 минут в твоем случае. Затем вы запускаете набор данных контейнера, который потребляет набор данных и подготавливает окончательный анализ, необходимый для каждого пользователя. Ноутбук будет в основном перебирать каждый уникальный идентификатор клиента (вы, возможно, смогли выполнить группировку и упорядочивание в SQL, чтобы сделать это быстрее) и выполнить необходимый анализ перед отправкой этих данных туда, где это необходимо.У вас может быть 1 набор данных контейнера для начальной обработки данных для каждого клиента и второй набор данных контейнера для обучения машинному обучению в зависимости от сложности сценария, но во многих случаях будет достаточно одного набора данных контейнера - я использовал этот подход для обучения десятков тысяч отдельных "устройств", так что это также может сработать для вашего варианта использования.